


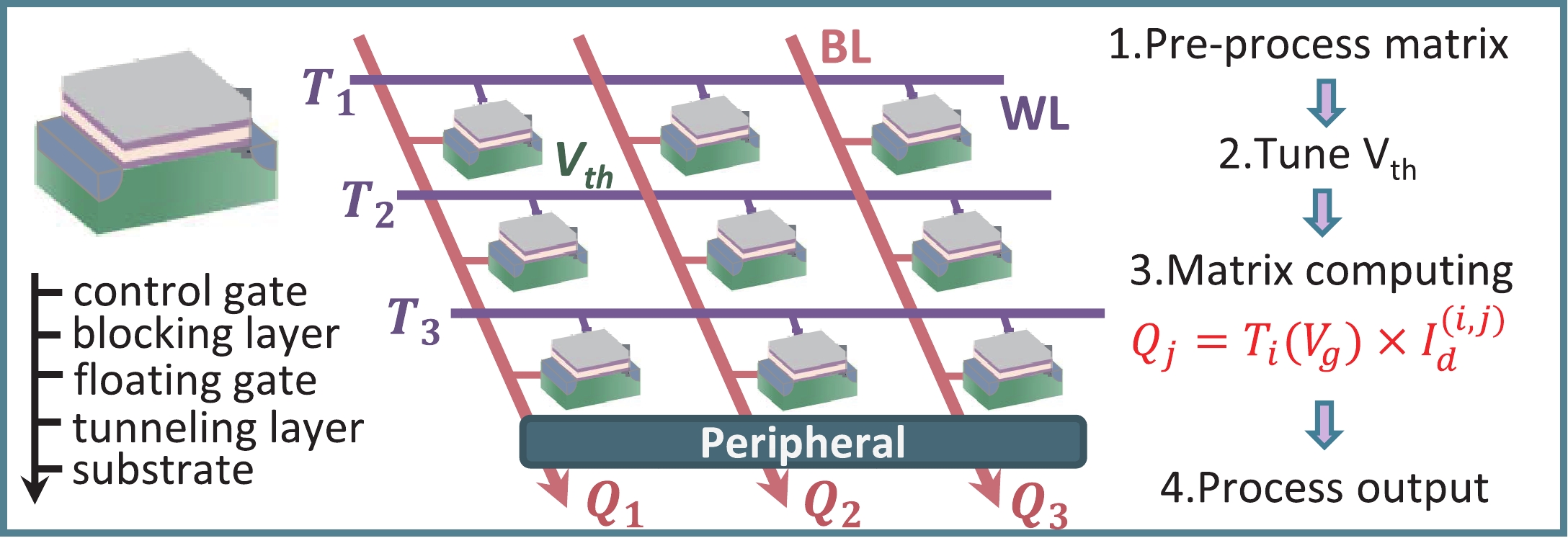
Fig. 1.
(Color online) Schematics of flash-based CIM architecture. The pulse time of Vg and the threshold voltage is individually mapped as vector and matrix, then the amount of charge can represent the result of MVM.
ARTICLES
Yang Feng1, Zhaohui Sun1, Yueran Qi1, Xuepeng Zhan1, Junyu Zhang2, Jing Liu3, Masaharu Kobayashi4, Jixuan Wu1, and Jiezhi Chen1,
Corresponding author: Jixuan Wu, jixuanwu@sdu.edu.cn; Jiezhi Chen, chen.jiezhi@sdu.edu.cn
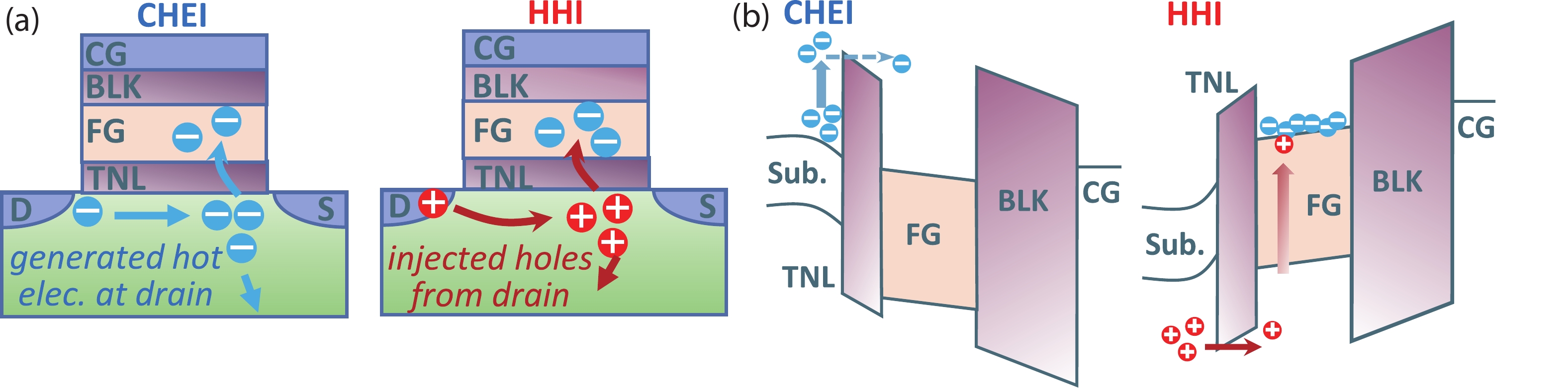
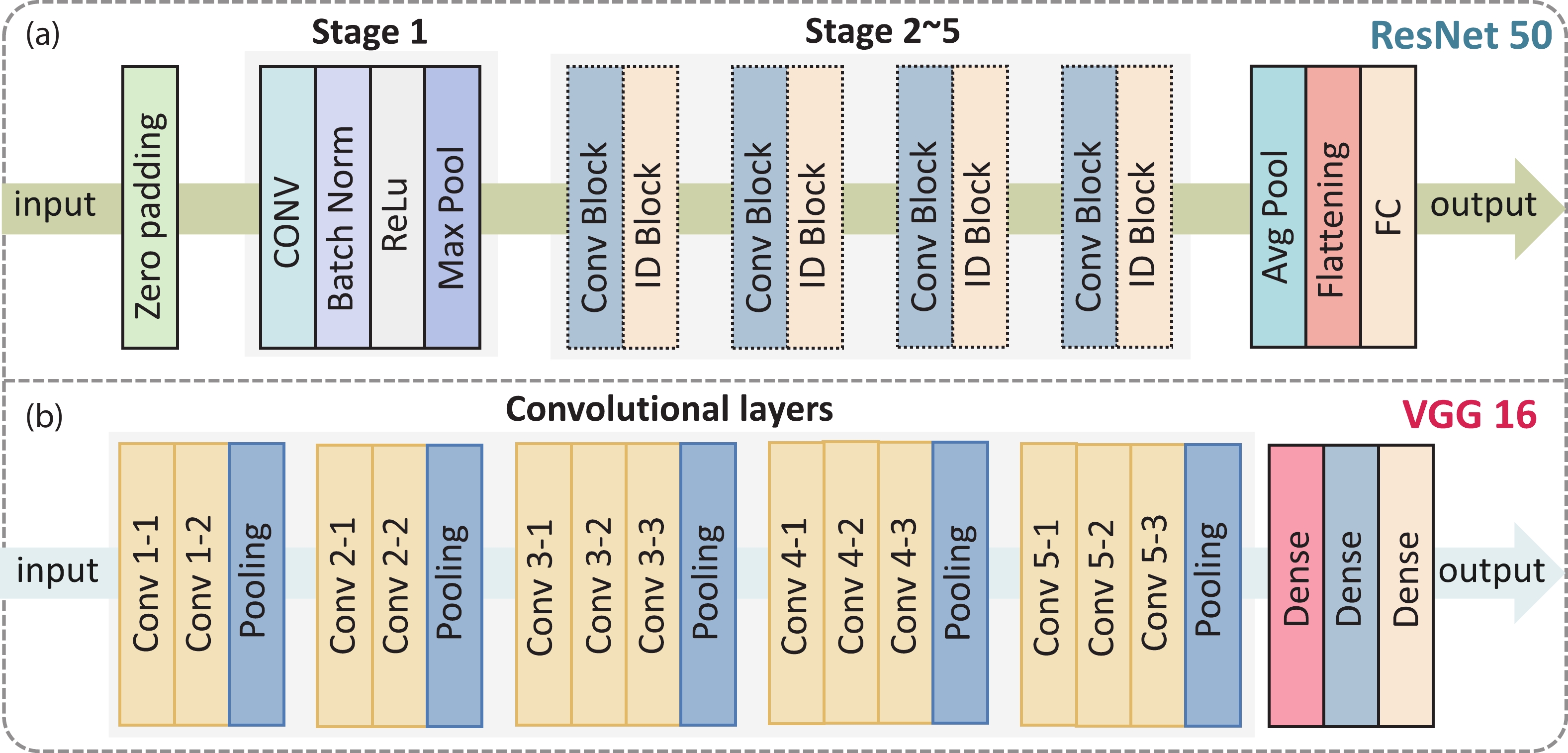
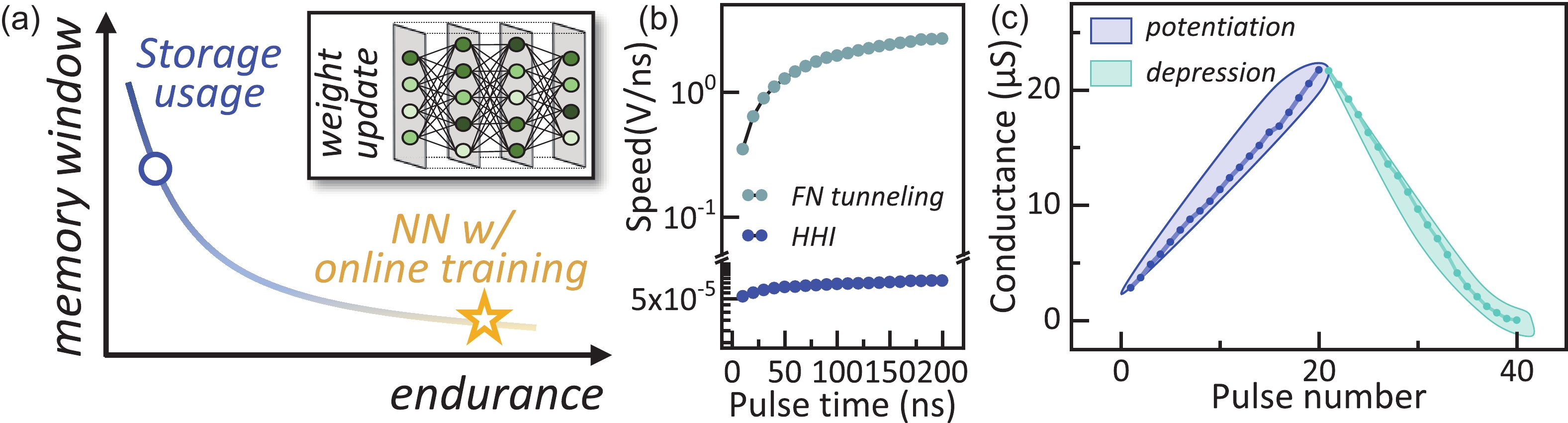
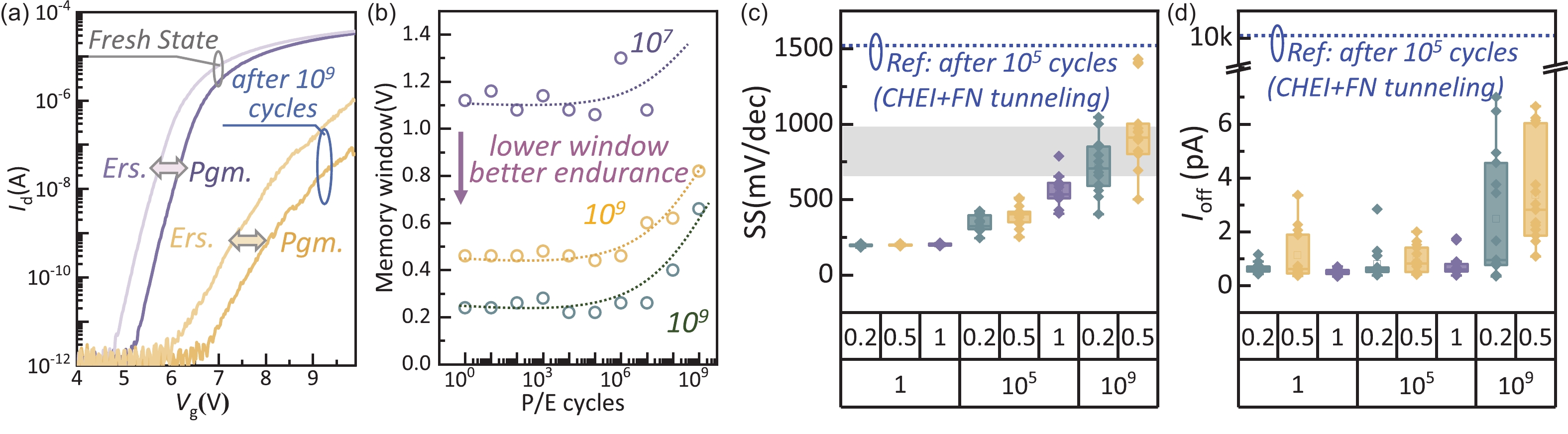
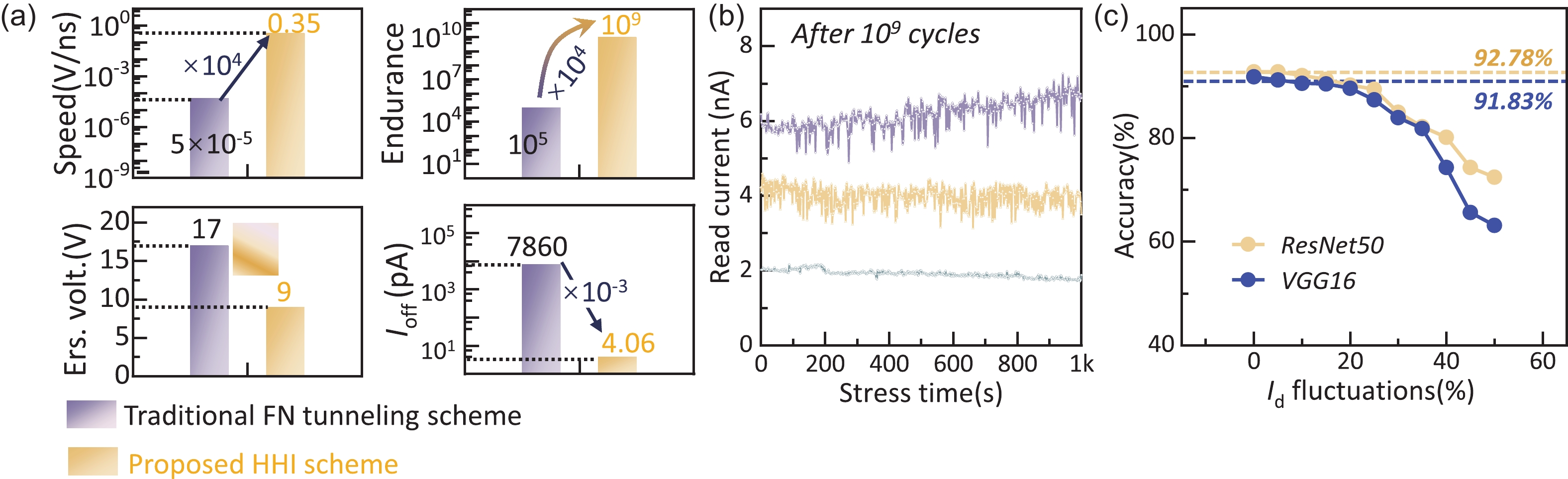
Abstract: With the rapid development of machine learning, the demand for high-efficient computing becomes more and more urgent. To break the bottleneck of the traditional Von Neumann architecture, computing-in-memory (CIM) has attracted increasing attention in recent years. In this work, to provide a feasible CIM solution for the large-scale neural networks (NN) requiring continuous weight updating in online training, a flash-based computing-in-memory with high endurance (109 cycles) and ultra-fast programming speed is investigated. On the one hand, the proposed programming scheme of channel hot electron injection (CHEI) and hot hole injection (HHI) demonstrate high linearity, symmetric potentiation, and a depression process, which help to improve the training speed and accuracy. On the other hand, the low-damage programming scheme and memory window (MW) optimizations can suppress cell degradation effectively with improved computing accuracy. Even after 109 cycles, the leakage current (Ioff) of cells remains sub-10pA, ensuring the large-scale computing ability of memory. Further characterizations are done on read disturb to demonstrate its robust reliabilities. By processing CIFAR-10 tasks, it is evident that ~90% accuracy can be achieved after 109 cycles in both ResNet50 and VGG16 NN. Our results suggest that flash-based CIM has great potential to overcome the limitations of traditional Von Neumann architectures and enable high-performance NN online training, which pave the way for further development of artificial intelligence (AI) accelerators.
Key words: NOR flash memory, computing-in-memory, endurance, neural network, online training
| [1] |
Yao P, Wu H Q, Gao B, et al. Fully hardware-implemented memristor convolutional neural network. Nature, 2020, 577, 641 doi: 10.1038/s41586-020-1942-4
|
| [2] |
Khwa W S, Akarvardar K, Chen Y S, et al. MLC PCM techniques to improve nerual network inference retention time by 105X and reduce accuracy degradation by 10.8X. Proc IEEE Symp VLSI Technol, 2020, 1
|
| [3] |
Zhang W Y, Wang S C, Li Y, et al. Few-shot graph learning with robust and energy-efficient memory-augmented graph neural network (MAGNN) based on homogeneous computing-in-memory. 2022 IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits), 2022, 224
|
| [4] |
Kumar S, Wang X X, Strachan J P, et al. Dynamical memristors for higher-complexity neuromorphic computing. Nat Rev Mater, 2022, 7, 575 doi: 10.1038/s41578-022-00434-z
|
| [5] |
Lu Y M, Li X, Yan B N, et al. In-memory realization of eligibility traces based on conductance drift of phase change memory for energy-efficient reinforcement learning. Adv Mater, 2022, 34, 2107811 doi: 10.1002/adma.202107811
|
| [6] |
Huang P, Zhou Z, Zhang Y, et al. Dual-configuration in-memory computing bitcells using SiOx RRAM for binary neural networks. APL Mater, 2019, 7, 081105 doi: 10.1063/1.5116863
|
| [7] |
Chang C C, Chen P C, Chou T, et al. Mitigating asymmetric nonlinear weight update effects in hardware neural network based on analog resistive synapse. IEEE J Emerg Sel Top Circuits Syst, 2018, 8, 116 doi: 10.1109/JETCAS.2017.2771529
|
| [8] |
Ravsher T, Garbin D, Fantini A, et al. Enhanced performance and low-power capability of SiGeAsSe-GeSbTe 1S1R phase-change memory operated in bipolar mode. 2022 IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits), 2022, 312
|
| [9] |
Ielmini D, Ghetti A, Spinelli A S, et al. A study of hot-hole injection during programming drain disturb in flash memories. IEEE Trans Electron Devices, 2006, 53, 668 doi: 10.1109/TED.2006.870280
|
| [10] |
Wu W, Wu H Q, Gao B, et al. A methodology to improve linearity of analog RRAM for neuromorphic computing. 2018 IEEE Symposium on VLSI Technology, 2018, 103 doi: 10.1109/VLSIT.2018.8510690
|
| [11] |
Wang Q W, Park Y, Lu W D. Device variation effects on neural network inference accuracy in analog In-memory computing systems. Adv Intell Syst, 2022, 4, 2100199 doi: 10.1002/aisy.202100199
|
| [12] |
Ogawa S, Shiono N. Interface-trap generation induced by hot-hole injection at the Si-SiO2 interface. Appl Phys Lett, 1992, 61, 807 doi: 10.1063/1.107751
|
| [13] |
Choi W, Kwak M, Heo S, et al. Hardware neural network using hybrid synapses via transfer learning: WO x nano-resistors and TiO x RRAM synapse for energy-efficient edge-AI sensor. 2021 IEEE International Electron Devices Meeting (IEDM), 2021, 23.1. 1
|
| [14] |
Ali T, Seidel K, Kühnel K, et al. A novel dual ferroelectric layer based MFMFIS FeFET with optimal stack tuning toward low power and high-speed NVM for neuromorphic applications. 2020 IEEE Symposium on VLSI Technology, 2020, 1 doi: 10.1109/VLSITechnology18217.2020.9265111
|
| [15] |
Lue H T, Hsu P K, Wei M L, et al. Optimal design methods to transform 3D NAND flash into a high-density, high-bandwidth and low-power nonvolatile computing in memory (nvCIM) accelerator for deep-learning neural networks (DNN). 2019 IEEE International Electron Devices Meeting (IEDM), 2020, 38.1.1 doi: 10.1109/IEDM19573.2019.8993652
|
| [16] |
Malavena G, Spinelli A S, Compagnoni C M. Implementing spike-timing-dependent plasticity and unsupervised learning in a mainstream NOR flash memory array. 2018 IEEE International Electron Devices Meeting (IEDM), 2019, 2.3.1 doi: 10.1109/IEDM.2018.8614561
|
| [1] |
Yao P, Wu H Q, Gao B, et al. Fully hardware-implemented memristor convolutional neural network. Nature, 2020, 577, 641 doi: 10.1038/s41586-020-1942-4
|
| [2] |
Khwa W S, Akarvardar K, Chen Y S, et al. MLC PCM techniques to improve nerual network inference retention time by 105X and reduce accuracy degradation by 10.8X. Proc IEEE Symp VLSI Technol, 2020, 1
|
| [3] |
Zhang W Y, Wang S C, Li Y, et al. Few-shot graph learning with robust and energy-efficient memory-augmented graph neural network (MAGNN) based on homogeneous computing-in-memory. 2022 IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits), 2022, 224
|
| [4] |
Kumar S, Wang X X, Strachan J P, et al. Dynamical memristors for higher-complexity neuromorphic computing. Nat Rev Mater, 2022, 7, 575 doi: 10.1038/s41578-022-00434-z
|
| [5] |
Lu Y M, Li X, Yan B N, et al. In-memory realization of eligibility traces based on conductance drift of phase change memory for energy-efficient reinforcement learning. Adv Mater, 2022, 34, 2107811 doi: 10.1002/adma.202107811
|
| [6] |
Huang P, Zhou Z, Zhang Y, et al. Dual-configuration in-memory computing bitcells using SiOx RRAM for binary neural networks. APL Mater, 2019, 7, 081105 doi: 10.1063/1.5116863
|
| [7] |
Chang C C, Chen P C, Chou T, et al. Mitigating asymmetric nonlinear weight update effects in hardware neural network based on analog resistive synapse. IEEE J Emerg Sel Top Circuits Syst, 2018, 8, 116 doi: 10.1109/JETCAS.2017.2771529
|
| [8] |
Ravsher T, Garbin D, Fantini A, et al. Enhanced performance and low-power capability of SiGeAsSe-GeSbTe 1S1R phase-change memory operated in bipolar mode. 2022 IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits), 2022, 312
|
| [9] |
Ielmini D, Ghetti A, Spinelli A S, et al. A study of hot-hole injection during programming drain disturb in flash memories. IEEE Trans Electron Devices, 2006, 53, 668 doi: 10.1109/TED.2006.870280
|
| [10] |
Wu W, Wu H Q, Gao B, et al. A methodology to improve linearity of analog RRAM for neuromorphic computing. 2018 IEEE Symposium on VLSI Technology, 2018, 103 doi: 10.1109/VLSIT.2018.8510690
|
| [11] |
Wang Q W, Park Y, Lu W D. Device variation effects on neural network inference accuracy in analog In-memory computing systems. Adv Intell Syst, 2022, 4, 2100199 doi: 10.1002/aisy.202100199
|
| [12] |
Ogawa S, Shiono N. Interface-trap generation induced by hot-hole injection at the Si-SiO2 interface. Appl Phys Lett, 1992, 61, 807 doi: 10.1063/1.107751
|
| [13] |
Choi W, Kwak M, Heo S, et al. Hardware neural network using hybrid synapses via transfer learning: WO x nano-resistors and TiO x RRAM synapse for energy-efficient edge-AI sensor. 2021 IEEE International Electron Devices Meeting (IEDM), 2021, 23.1. 1
|
| [14] |
Ali T, Seidel K, Kühnel K, et al. A novel dual ferroelectric layer based MFMFIS FeFET with optimal stack tuning toward low power and high-speed NVM for neuromorphic applications. 2020 IEEE Symposium on VLSI Technology, 2020, 1 doi: 10.1109/VLSITechnology18217.2020.9265111
|
| [15] |
Lue H T, Hsu P K, Wei M L, et al. Optimal design methods to transform 3D NAND flash into a high-density, high-bandwidth and low-power nonvolatile computing in memory (nvCIM) accelerator for deep-learning neural networks (DNN). 2019 IEEE International Electron Devices Meeting (IEDM), 2020, 38.1.1 doi: 10.1109/IEDM19573.2019.8993652
|
| [16] |
Malavena G, Spinelli A S, Compagnoni C M. Implementing spike-timing-dependent plasticity and unsupervised learning in a mainstream NOR flash memory array. 2018 IEEE International Electron Devices Meeting (IEDM), 2019, 2.3.1 doi: 10.1109/IEDM.2018.8614561
|









Article views: 561 Times PDF downloads: 70 Times Cited by: 0 Times
Received: 14 July 2023 Revised: 09 September 2023 Online: Accepted Manuscript: 10 November 2023Uncorrected proof: 11 December 2023Published: 10 January 2024
| Citation: |
Yang Feng, Zhaohui Sun, Yueran Qi, Xuepeng Zhan, Junyu Zhang, Jing Liu, Masaharu Kobayashi, Jixuan Wu, Jiezhi Chen. Optimized operation scheme of flash-memory-based neural network online training with ultra-high endurance[J]. Journal of Semiconductors, 2024, 45(1): 012301. doi: 10.1088/1674-4926/45/1/012301
Y Feng, Z H Sun, Y R Qi, X P Zhan, J Y Zhang, J Liu, M Kobayashi, J X Wu, J Z Chen. Optimized operation scheme of flash-memory-based neural network online training with ultra-high endurance[J]. J. Semicond, 2024, 45(1): 012301. doi: 10.1088/1674-4926/45/1/012301
Export: BibTex EndNote

|
| [1] |
Yao P, Wu H Q, Gao B, et al. Fully hardware-implemented memristor convolutional neural network. Nature, 2020, 577, 641 doi: 10.1038/s41586-020-1942-4
|
| [2] |
Khwa W S, Akarvardar K, Chen Y S, et al. MLC PCM techniques to improve nerual network inference retention time by 105X and reduce accuracy degradation by 10.8X. Proc IEEE Symp VLSI Technol, 2020, 1
|
| [3] |
Zhang W Y, Wang S C, Li Y, et al. Few-shot graph learning with robust and energy-efficient memory-augmented graph neural network (MAGNN) based on homogeneous computing-in-memory. 2022 IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits), 2022, 224
|
| [4] |
Kumar S, Wang X X, Strachan J P, et al. Dynamical memristors for higher-complexity neuromorphic computing. Nat Rev Mater, 2022, 7, 575 doi: 10.1038/s41578-022-00434-z
|
| [5] |
Lu Y M, Li X, Yan B N, et al. In-memory realization of eligibility traces based on conductance drift of phase change memory for energy-efficient reinforcement learning. Adv Mater, 2022, 34, 2107811 doi: 10.1002/adma.202107811
|
| [6] |
Huang P, Zhou Z, Zhang Y, et al. Dual-configuration in-memory computing bitcells using SiOx RRAM for binary neural networks. APL Mater, 2019, 7, 081105 doi: 10.1063/1.5116863
|
| [7] |
Chang C C, Chen P C, Chou T, et al. Mitigating asymmetric nonlinear weight update effects in hardware neural network based on analog resistive synapse. IEEE J Emerg Sel Top Circuits Syst, 2018, 8, 116 doi: 10.1109/JETCAS.2017.2771529
|
| [8] |
Ravsher T, Garbin D, Fantini A, et al. Enhanced performance and low-power capability of SiGeAsSe-GeSbTe 1S1R phase-change memory operated in bipolar mode. 2022 IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits), 2022, 312
|
| [9] |
Ielmini D, Ghetti A, Spinelli A S, et al. A study of hot-hole injection during programming drain disturb in flash memories. IEEE Trans Electron Devices, 2006, 53, 668 doi: 10.1109/TED.2006.870280
|
| [10] |
Wu W, Wu H Q, Gao B, et al. A methodology to improve linearity of analog RRAM for neuromorphic computing. 2018 IEEE Symposium on VLSI Technology, 2018, 103 doi: 10.1109/VLSIT.2018.8510690
|
| [11] |
Wang Q W, Park Y, Lu W D. Device variation effects on neural network inference accuracy in analog In-memory computing systems. Adv Intell Syst, 2022, 4, 2100199 doi: 10.1002/aisy.202100199
|
| [12] |
Ogawa S, Shiono N. Interface-trap generation induced by hot-hole injection at the Si-SiO2 interface. Appl Phys Lett, 1992, 61, 807 doi: 10.1063/1.107751
|
| [13] |
Choi W, Kwak M, Heo S, et al. Hardware neural network using hybrid synapses via transfer learning: WO x nano-resistors and TiO x RRAM synapse for energy-efficient edge-AI sensor. 2021 IEEE International Electron Devices Meeting (IEDM), 2021, 23.1. 1
|
| [14] |
Ali T, Seidel K, Kühnel K, et al. A novel dual ferroelectric layer based MFMFIS FeFET with optimal stack tuning toward low power and high-speed NVM for neuromorphic applications. 2020 IEEE Symposium on VLSI Technology, 2020, 1 doi: 10.1109/VLSITechnology18217.2020.9265111
|
| [15] |
Lue H T, Hsu P K, Wei M L, et al. Optimal design methods to transform 3D NAND flash into a high-density, high-bandwidth and low-power nonvolatile computing in memory (nvCIM) accelerator for deep-learning neural networks (DNN). 2019 IEEE International Electron Devices Meeting (IEDM), 2020, 38.1.1 doi: 10.1109/IEDM19573.2019.8993652
|
| [16] |
Malavena G, Spinelli A S, Compagnoni C M. Implementing spike-timing-dependent plasticity and unsupervised learning in a mainstream NOR flash memory array. 2018 IEEE International Electron Devices Meeting (IEDM), 2019, 2.3.1 doi: 10.1109/IEDM.2018.8614561
|
 WeChat ID
WeChat ID
Journal of Semiconductors © 2017 All Rights Reserved 京ICP备05085259号-2

 DownLoad:
DownLoad:

