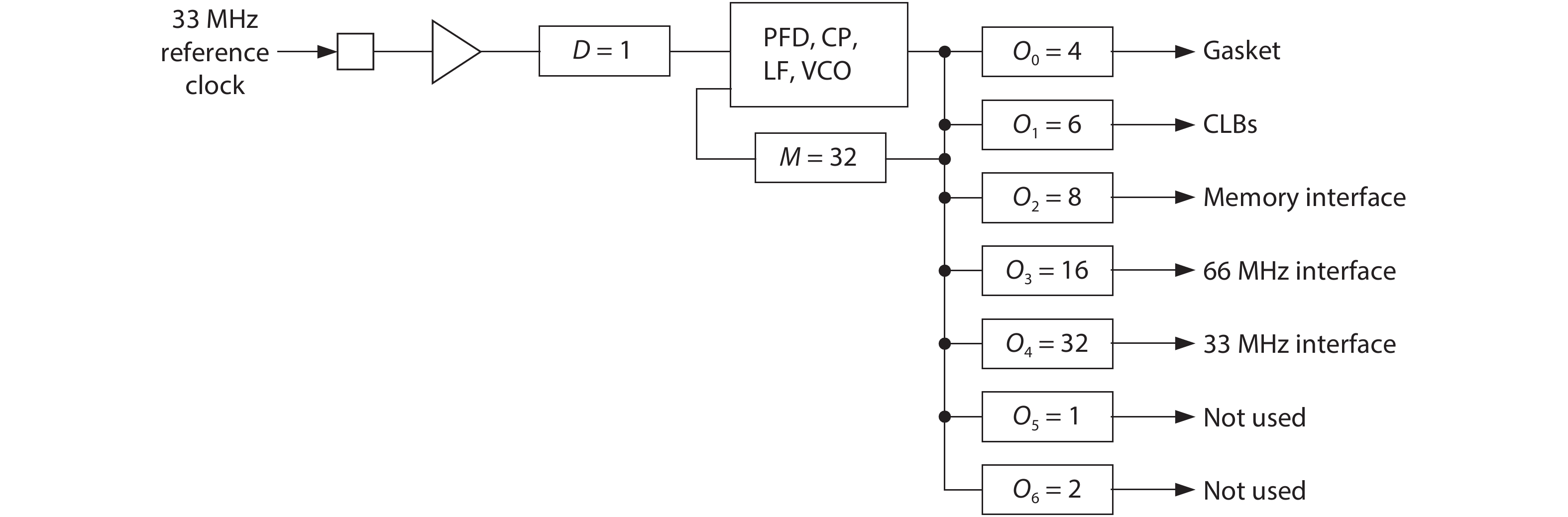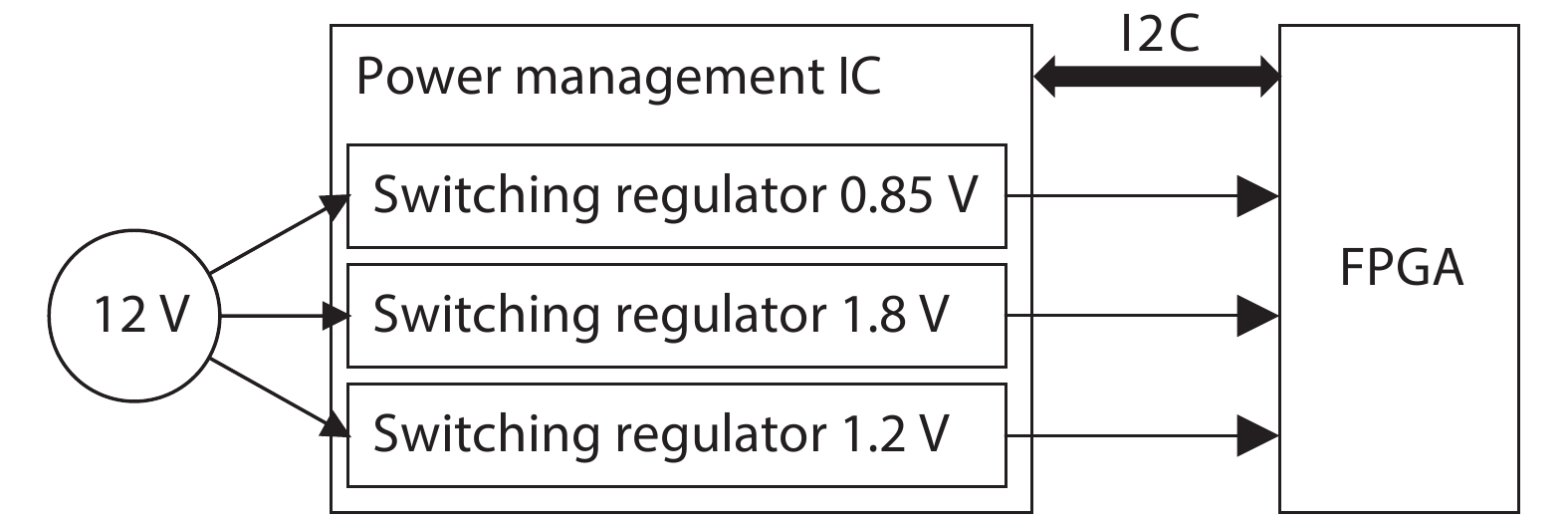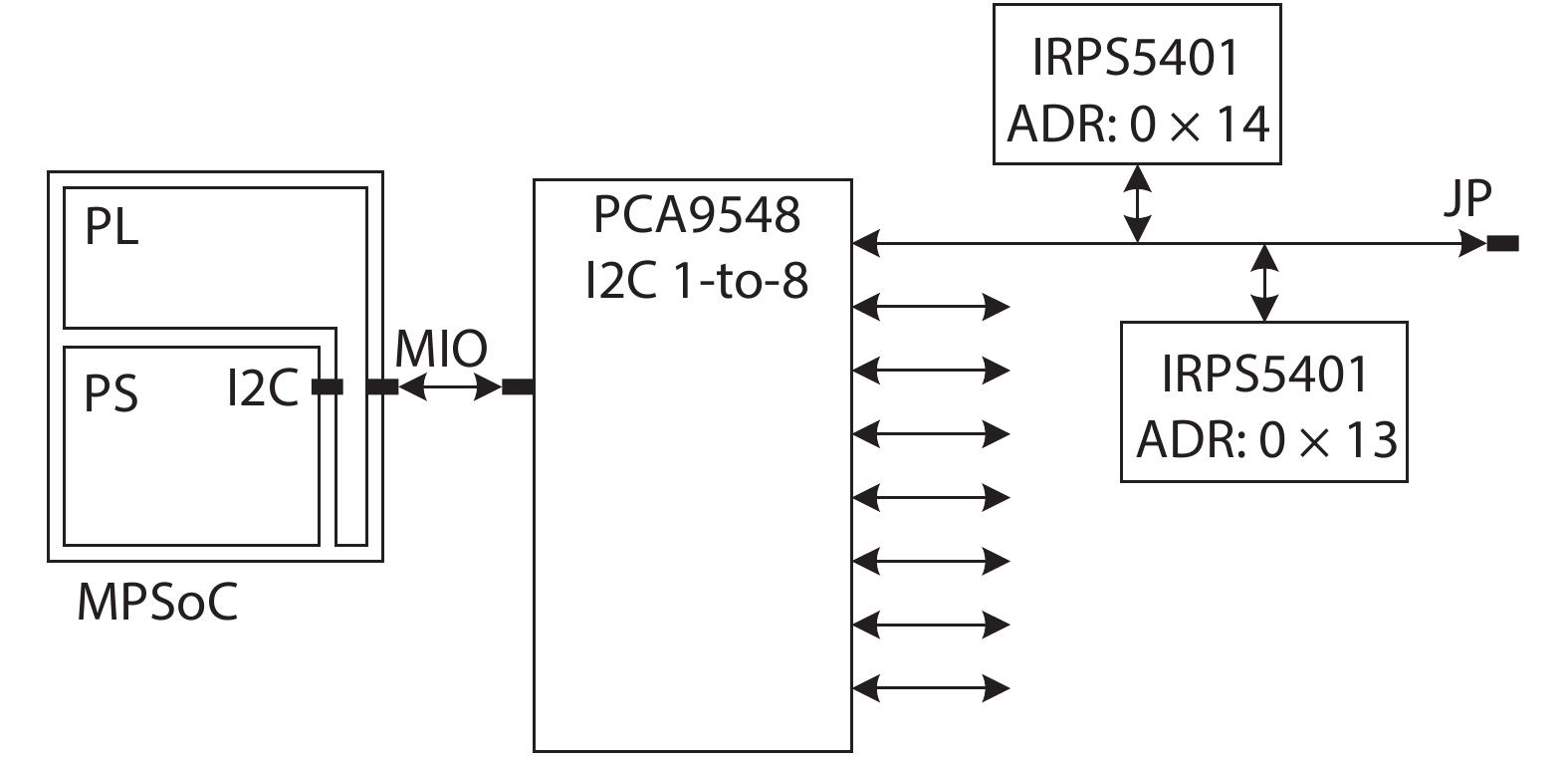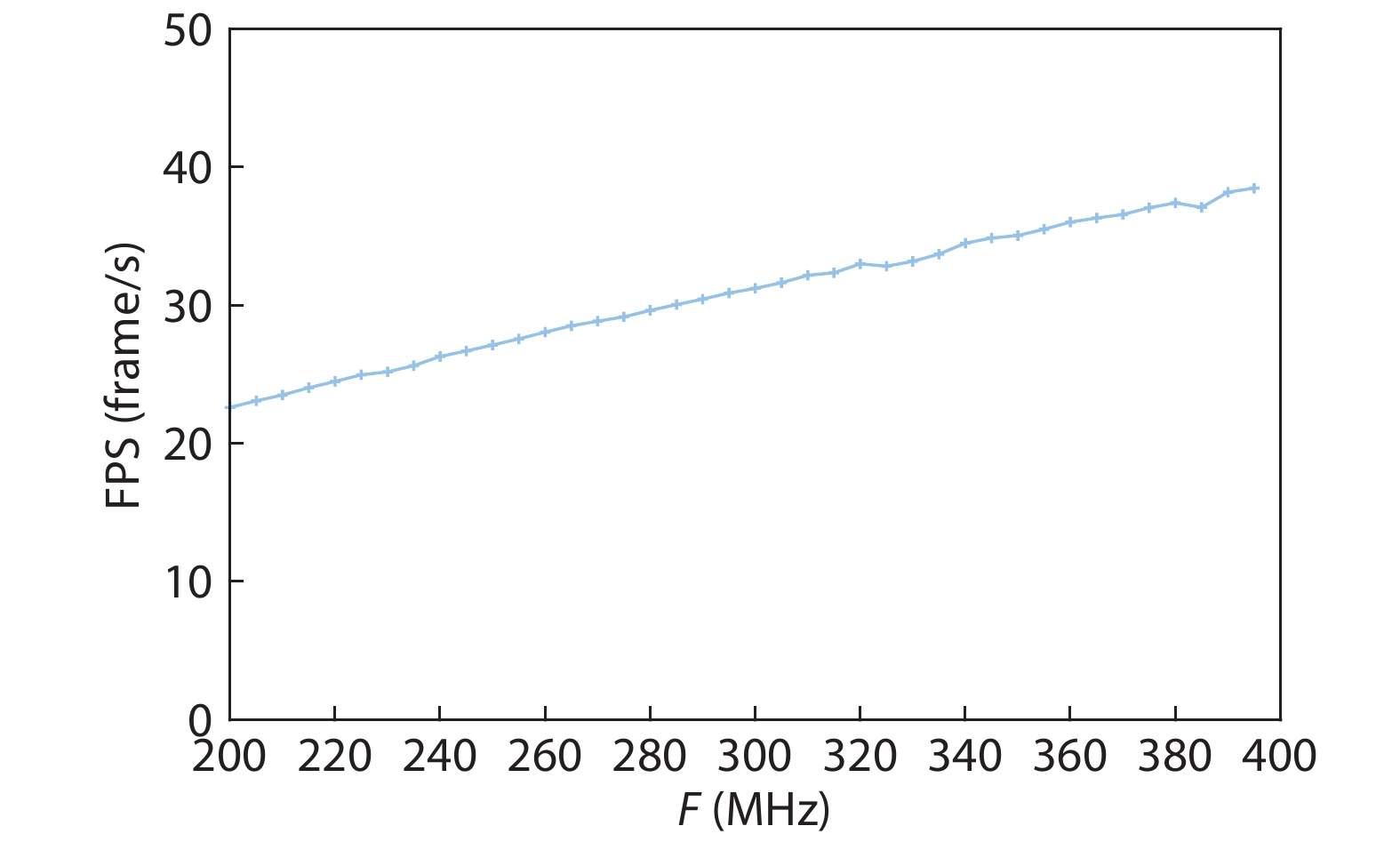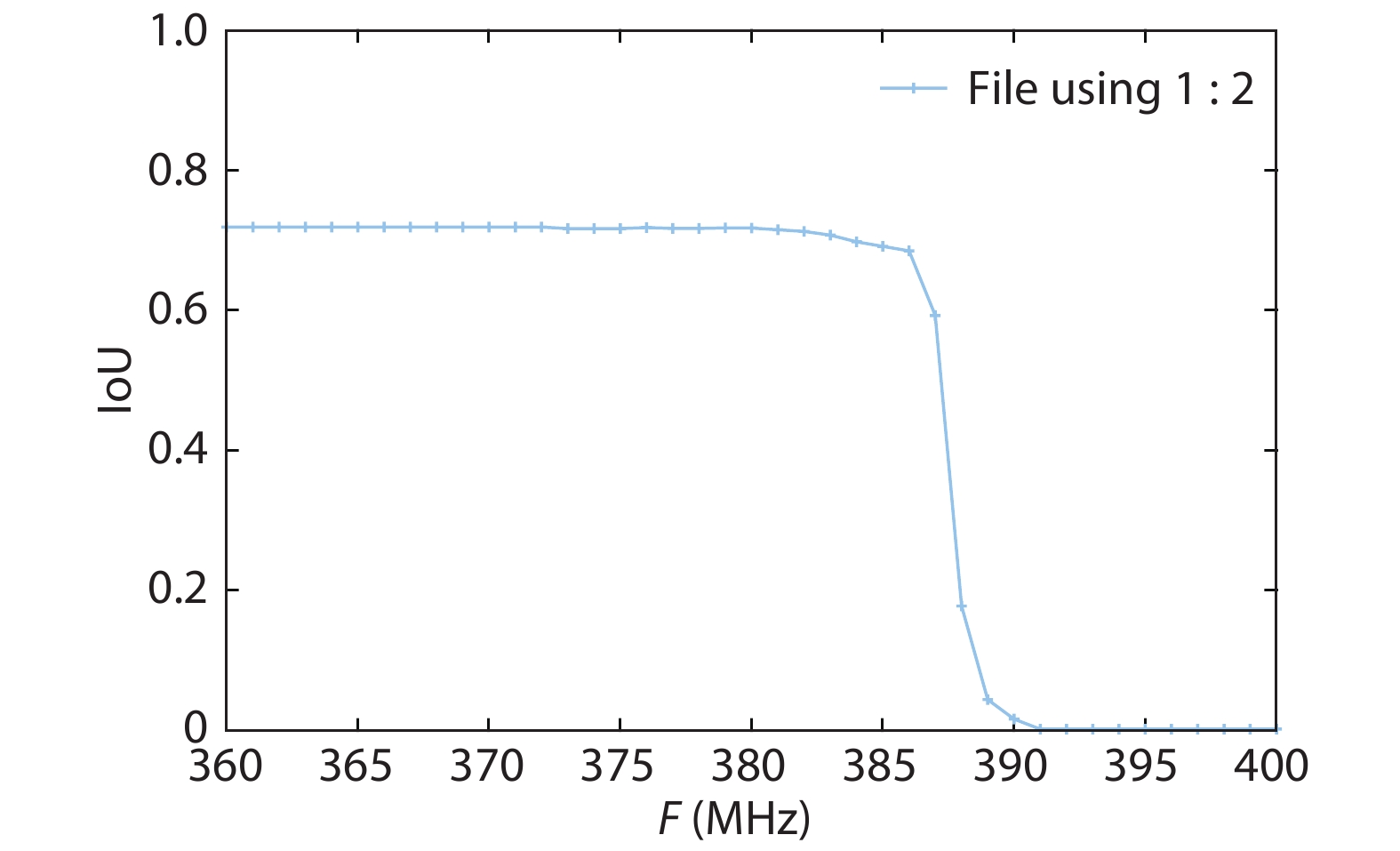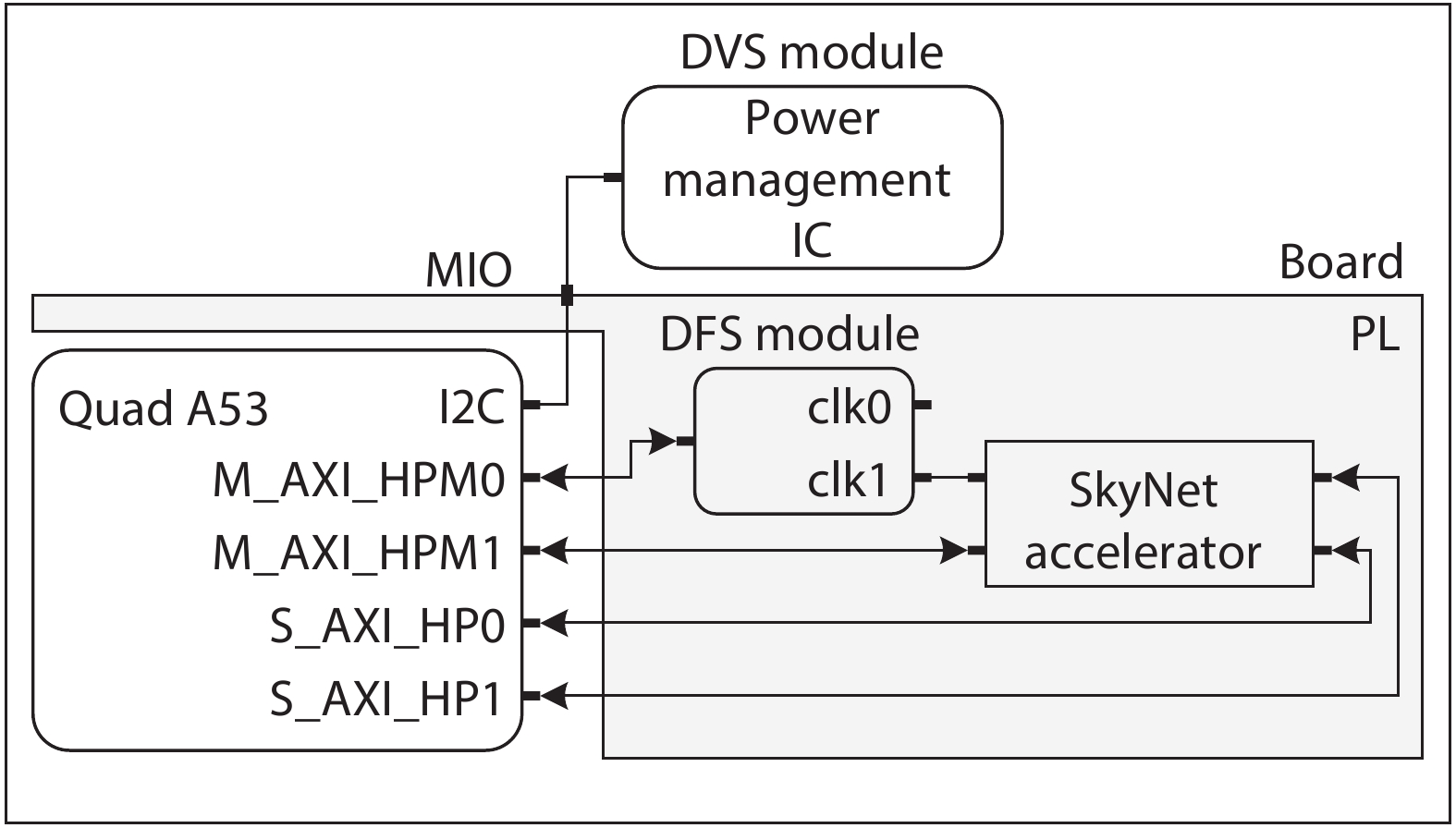
Fig. 1.
System architecture of CNN accelerator.
ARTICLES
Weixiong Jiang1, 2, 3, Heng Yu4, Jiale Zhang1, 2, 3, Jiaxuan Wu1, 2, 3, Shaobo Luo5 and Yajun Ha1, 2, 3,
Corresponding author: Yajun Ha, email: hayj@shanghaitech.edu.cn
Abstract: On the one hand, accelerating convolution neural networks (CNNs) on FPGAs requires ever increasing high energy efficiency in the edge computing paradigm. On the other hand, unlike normal digital algorithms, CNNs maintain their high robustness even with limited timing errors. By taking advantage of this unique feature, we propose to use dynamic voltage and frequency scaling (DVFS) to further optimize the energy efficiency for CNNs. First, we have developed a DVFS framework on FPGAs. Second, we apply the DVFS to SkyNet, a state-of-the-art neural network targeting on object detection. Third, we analyze the impact of DVFS on CNNs in terms of performance, power, energy efficiency and accuracy. Compared to the state-of-the-art, experimental results show that we have achieved 38% improvement in energy efficiency without any loss in accuracy. Results also show that we can achieve 47% improvement in energy efficiency if we allow 0.11% relaxation in accuracy.
Keywords: CNN, FPGA, DVFS, object detection
| [1] |
Nurvitadhi E, Venkatesh G, Sim J, et al. Can FPGAs beat GPUs in accelerating next-generation deep neural networks. Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2017
|
| [2] |
Mantovani P, Cota E G, Tien K, et al. An FPGA-based infrastructure for fine-grained DVFS analysis in high-performance embedded systems. Proceedings of the 53rd Annual Design Automation Conference, 2016
|
| [3] |
Bai L, Zhao Y, Huang X. A CNN accelerator on FPGA using depthwise separable convolution. IEEE Trans Circuits Syst II, 2018, 65(10), 1415 doi: 10.1109/TCSII.2018.2865896
|
| [4] |
Ma Y, Cao Y, Vrudhula S, et al. An automatic RTL compiler for high-throughput FPGA implementation of diverse deep convolutional neural networks. 27th International Conference on Field Programmable Logic and Applications (FPL), 2017
|
| [5] |
Ma Y, Cao Y, Vrudhula S, et al. Optimizing loop operation and dataflow in FPGA acceleration of deep convolutional neural networks. Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2017
|
| [6] |
Ma Y, Kim M, Cao Y, et al. End-to-end scalable FPGA accelerator for deep residual networks. 2017 IEEE International Symposium on Circuits and Systems (ISCAS), 2017
|
| [7] |
Wei X, Liang Y, Li X, et al. TGPA: tile-grained pipeline architecture for low latency CNN inference. 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), 2018
|
| [8] |
Guo K, Sui L, Qiu J, et al. Angel-eye: A complete design flow for mapping CNN onto embedded FPGA. IEEE Trans Comput-Aid Des Integr Circuits Syst, 2018, 37(1), 35 doi: 10.1109/TCAD.2017.2705069
|
| [9] |
Ma Y, Cao Y, Vrudhula S, et al. Performance modeling for cnn inference accelerators on FPGA. IEEE Trans Comput-Aid Des Integr Circuits Syst, 2019 doi: 10.1109/TCAD.2019.2897634
|
| [10] |
Qiu J, Wang J, Yao S, et al. Going deeper with embedded FPGA platform for convolutional neural network. Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2016
|
| [11] |
Zhang X, Wang J, Zhu C, et al. Dnnbuilder: an automated tool for building high-performance DNN hardware accelerators for FPGAs. Proceedings of the International Conference on Computer-Aided Design, 2018
|
| [12] |
Motamedi M, Fong D, Ghiasi S. Machine intelligence on resource-constrained IoT devices: The case of thread granularity optimization for CNN inference. ACM Trans Embedded Comput Syst, 2017, 16(5s), 151 doi: 10.1145/3126555
|
| [13] |
Xiao Q, Liang Y, Lu L, et al. Exploring heterogeneous algorithms for accelerating deep convolutional neural networks on FPGAs. 2017 54th ACM/EDAC/IEEE Design Automation Conference (DAC), 2017
|
| [14] |
Dutta S, Bai Z, Low T M, et al. Codenet: Training large scale neural networks in presence of soft-errors. arXiv preprint arXiv: 190301042, 2019
|
| [15] |
Nie B, Tiwari D, Gupta S, et al. A large-scale study of soft-errors on GPUs in the field. 2016 IEEE International Symposium on High Performance Computer Architecture (HPCA), 2016
|
| [16] |
Chen Y, Zhu Y, Qiao F, et al. Evaluating data resilience in CNNs from an approximate memory perspective. Proceedings of the on Great Lakes Symposium on VLSI, 2017, 89
|
| [17] |
Qiao A, Aragam B, Zhang B, et al. Fault tolerance in iterative-convergent machine learning. arXiv preprint arXiv: 1810.07354, 2018
|
| [18] |
Nunez-Yanez J L. Adaptive voltage scaling with in-situ detectors in commercial FPGAs. IEEE Trans Comput, 2014, 64(1), 45 doi: 10.1109/TC.2014.2365963
|
| [19] |
Nabina A, Nunez-Yanez J L. Adaptive voltage scaling in a dynamically reconfigurable FPGA-based platform. ACM Trans Reconfig Technol Syst, 2012, 5(4), 20 doi: 10.1145/2392616.2392618
|
| [20] |
Wei X, Liang Y, Cong J. Overcoming data transfer bottlenecks in FPGA-based DNN accelerators via layer conscious memory management. DAC, 2019, 125
|
| [21] |
Ding C, Wang S, Liu N, et al. Req-yolo: A resource-aware, efficient quantization framework for object detection on FPGAs. Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2019
|
| [22] |
Zhang X, Hao C, Li Y, et al. A bi-directional co-design approach to enable deep learning on IoT devices. arXiv preprint arXiv: 190508369, 2019
|
| [23] |
Hao C, Zhang X, Li Y, et al. FPGA/DNN co-design: An efficient design methodology for IoT intelligence on the edge. Proceedings of the 56th Annual Design Automation Conference, 2019
|
| [24] |
Nunez-Yanez J L. Energy proportional neural network inference with adaptive voltage and frequency scaling. IEEE Trans Comput, 2018, 99(99), 1 doi: 10.1109/TC.2018.2879333
|
| [25] |
Zhang X, Hao C, Lu H, et al., Skynet: A champion design for DAC-SDC on low power object detection. arXiv preprint arXiv: 190610327, 2019
|
| [26] |
Weissel A, Bellosa F, Process cruise control: event-driven clock scaling for dynamic power management. Proceedings of the 2002 International Conference on Compilers, Architecture, and Synthesis for Embedded Systems, 2002
|
| [27] |
De Vogeleer K, Memmi G, Jouvelot P, et al. The energy/frequency convexity rule: Modeling and experimental validation on mobile devices. International Conference on Parallel Processing and Applied Mathematics, 2013
|
| [28] |
Huang H, Chaturvedi V, Quan G, et al. Throughput maximization for periodic real-time systems under the maximal temperature constraint. ACM Trans Embed Comput Syst, 2014, 13(2s), 70 doi: 10.1145/2544375.2544390
|
| [29] |
Yu H, Syed R, Ha Y. Thermal-aware frequency scaling for adaptive workloads on heterogeneous MPSoCs. Proceedings of the Conference on Design, Automation & Test in Europe, 2014
|
| [30] |
Yu H, Ha Y, Wang J. Quality optimization of resilient applications under temperature constraints. Proceedings of the Computing Frontiers Conference, 2017
|
| [31] |
Ma Y, Chantem T, Dick R P, et al. Improving system-level lifetime reliability of multicore soft real-time systems. IEEE Trans Very Large Scale Integr Syst, 2017, 25(6), 1895 doi: 10.1109/TVLSI.2017.2669144
|
| [32] |
Bong K, Choi S, Kim C, et al. Low-power convolutional neural network processor for a face-recognition system. IEEE Micro, 2017, 37(6), 30 doi: 10.1109/MM.2017.4241350
|
| [33] |
Santoro G, Casu M R, Peluso V, et al. Design-space exploration of pareto-optimal architectures for deep learning with DVFS. 2018 IEEE International Symposium on Circuits and Systems (ISCAS), 2018
|
| [34] |
Hsieh G C, Hung J C. Phase-locked loop techniques. A survey. IEEE Trans Indust Electron, 1996, 43(6), 609 doi: 10.1109/41.544547
|
| [35] |
Kim J H, Kwak Y H, Kim M, et al. A 120-MHz–1.8-GHz CMOS dll-based clock generator for dynamic frequency scaling. IEEE J Solid-State Circuits, 2006, 41(9), 2077 doi: 10.1109/JSSC.2006.880609
|
| [36] |
Brynjolfson I, Zilic Z. Dynamic clock management for low power applications in FPGAs. Proceedings of the IEEE 2000 Custom Integrated Circuits Conference, 2000
|
| [37] |
Beldachi A F, Nunez-Yanez J L. Run-time power and performance scaling in 28 nm FPGAs. IET Comput Digit Tech, 2014, 8(4), 178
|
| [38] |
Beldachi A F, Nunez-Yanez J L. Accurate power control and monitoring in zynq boards. 2014 24th International Conference on Field Programmable Logic and Applications (FPL), 2014
|
| [39] |
Hosseinabady M, Nunez-Yanez J L. Run-time power gating in hybrid arm-FPGA devices. 2014 24th International Conference on Field Programmable Logic and Applications (FPL), 2014
|
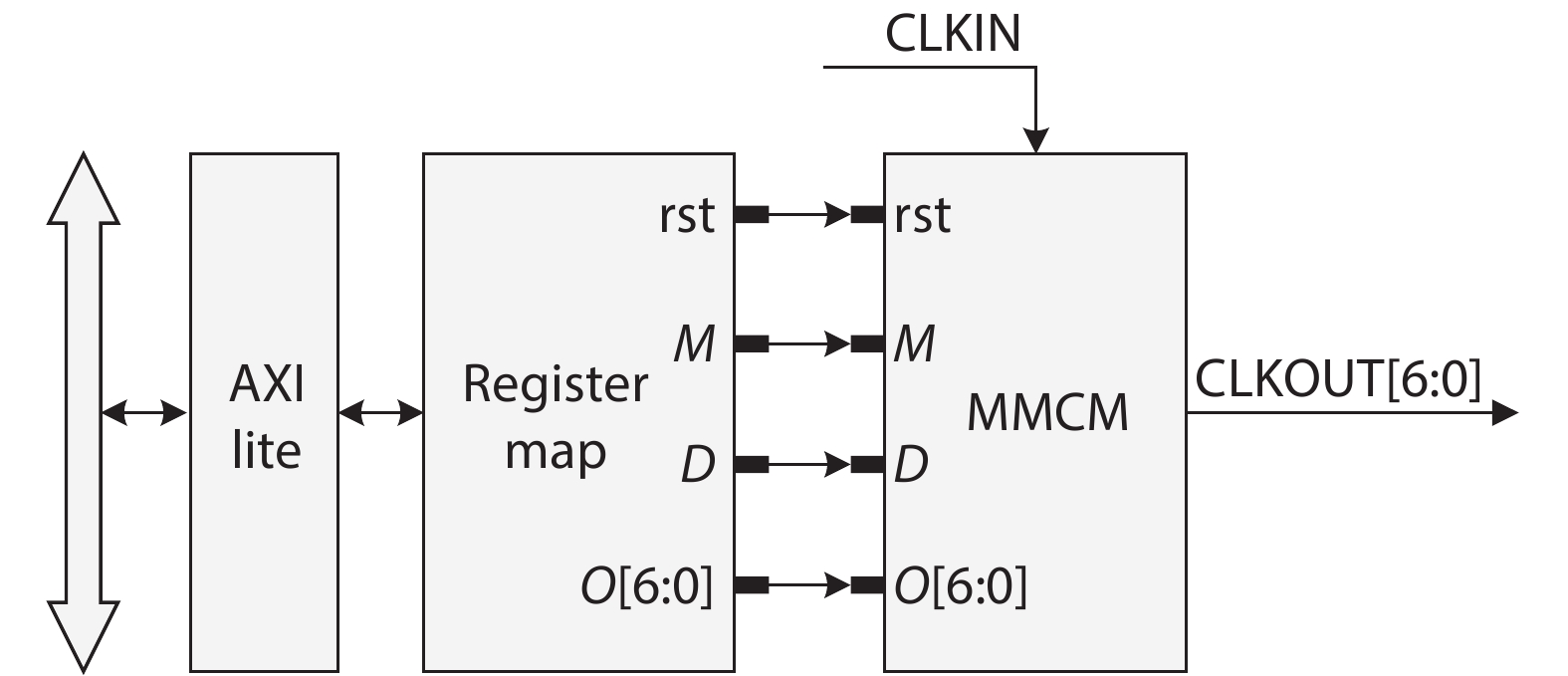
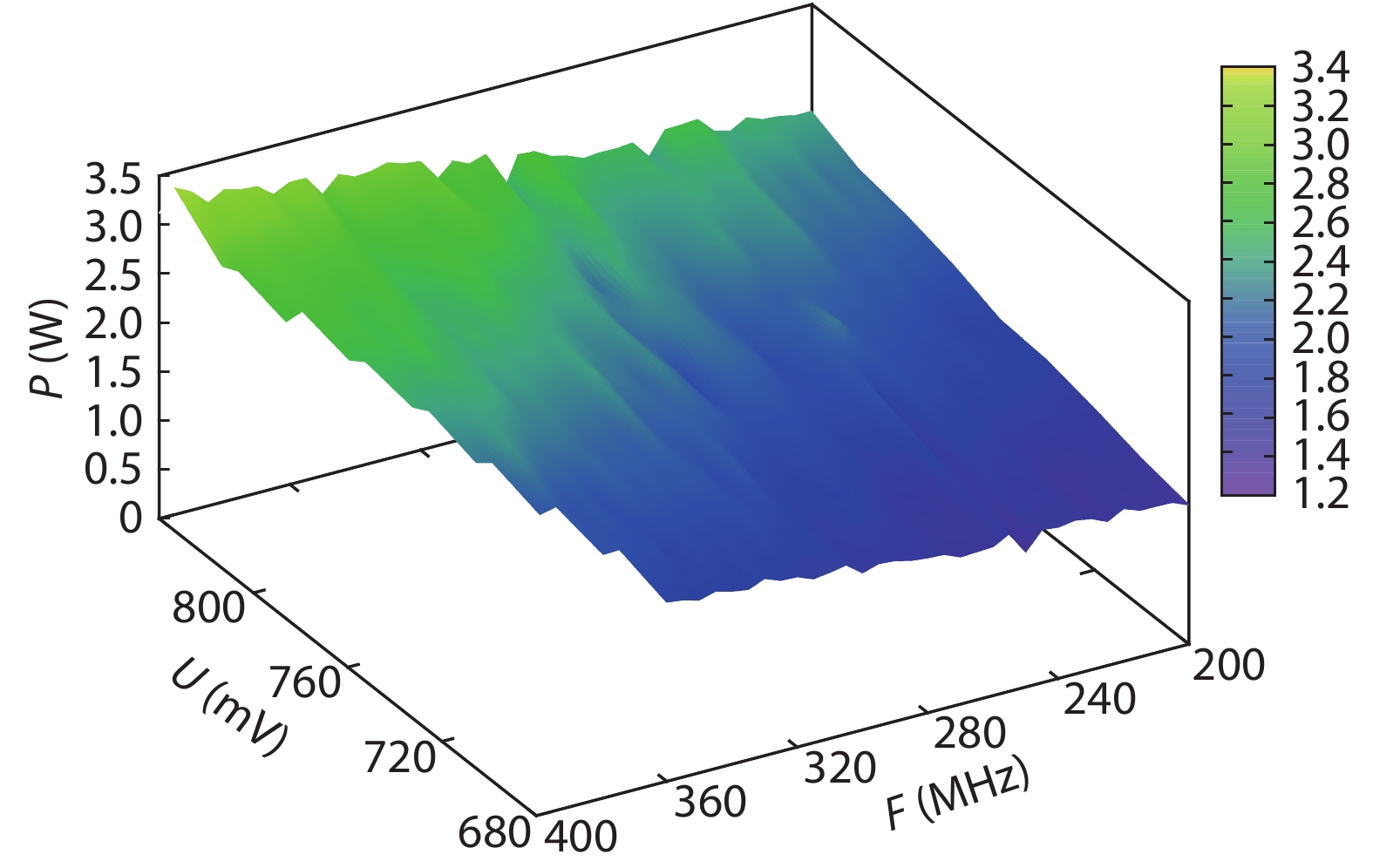
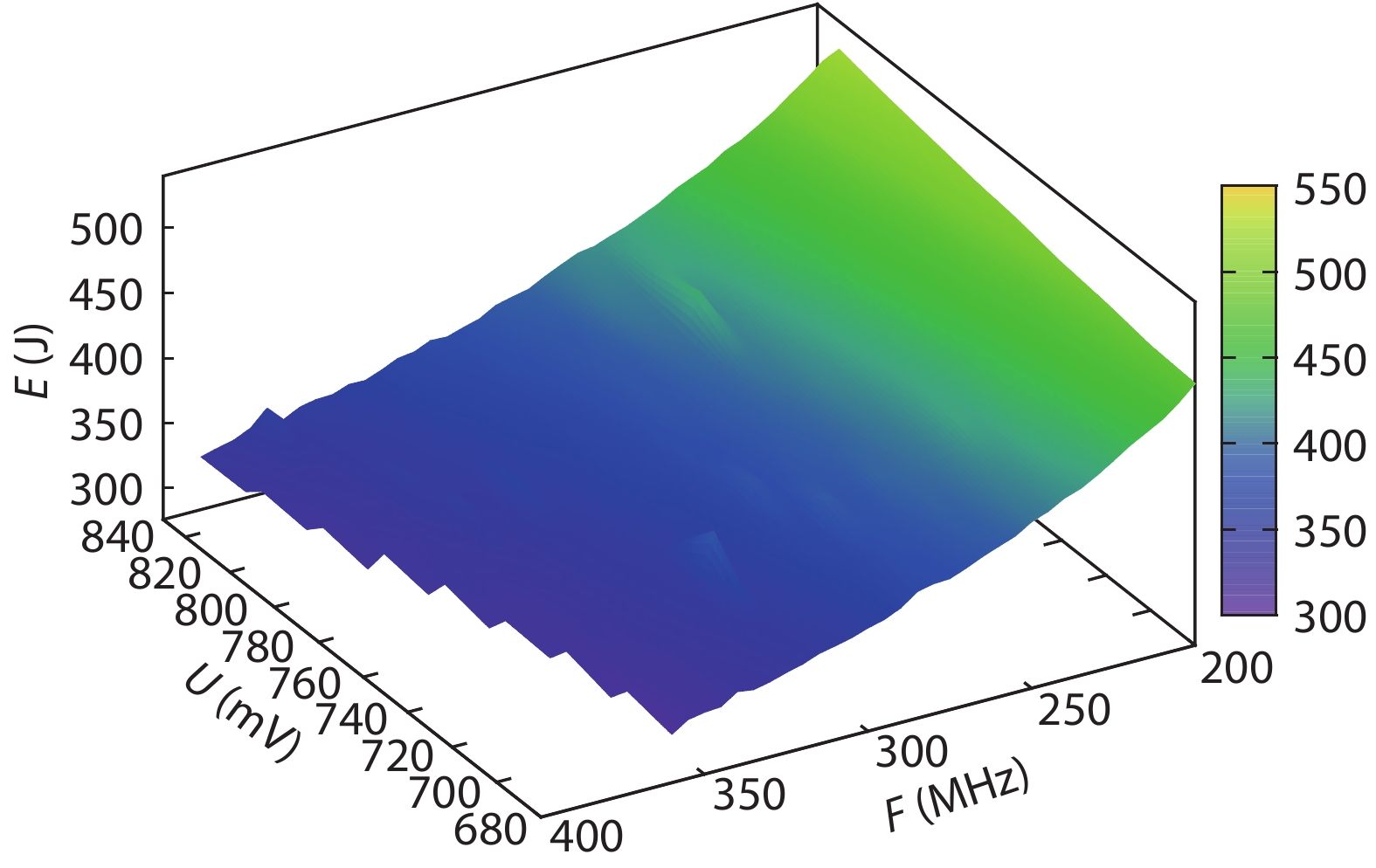
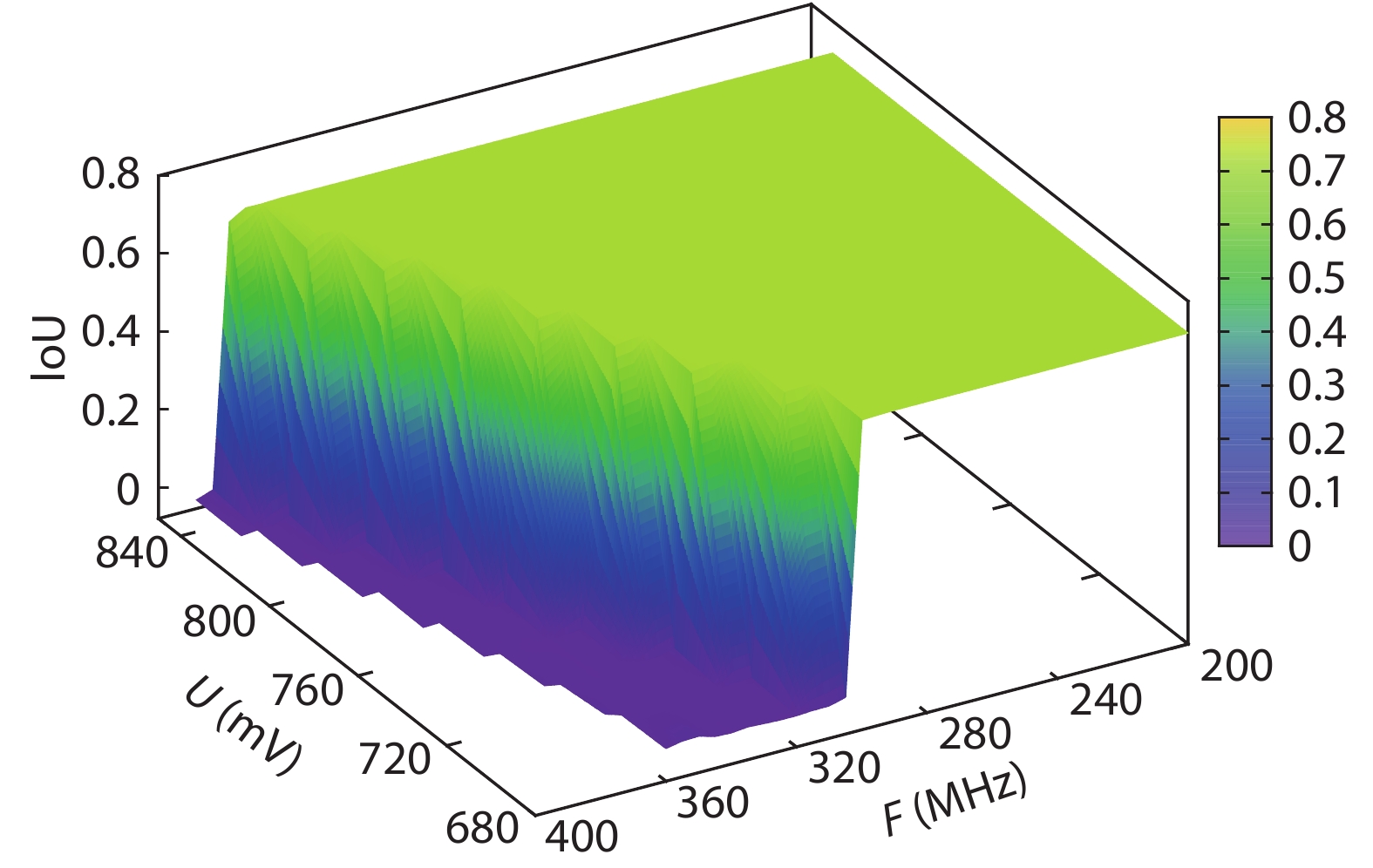
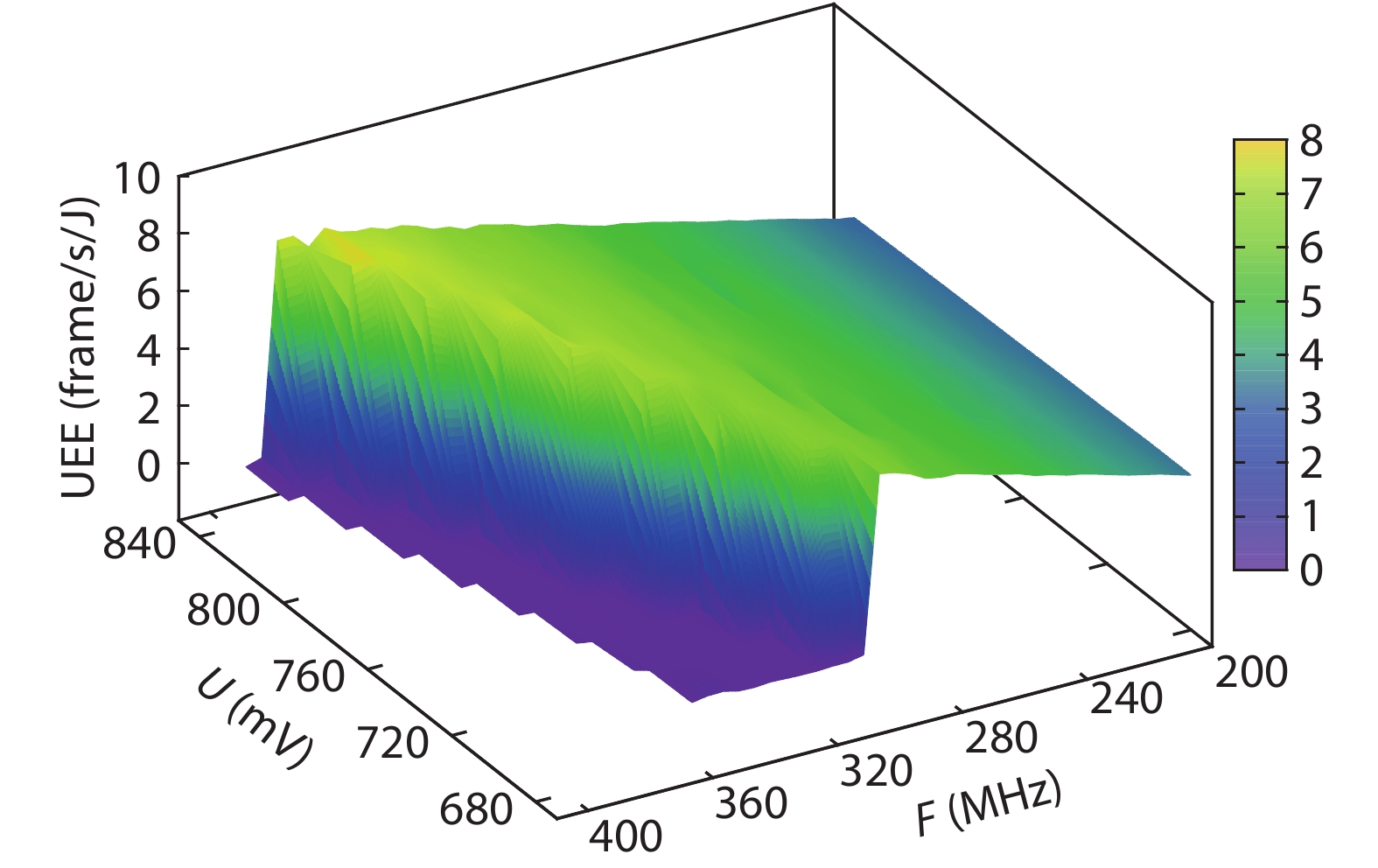
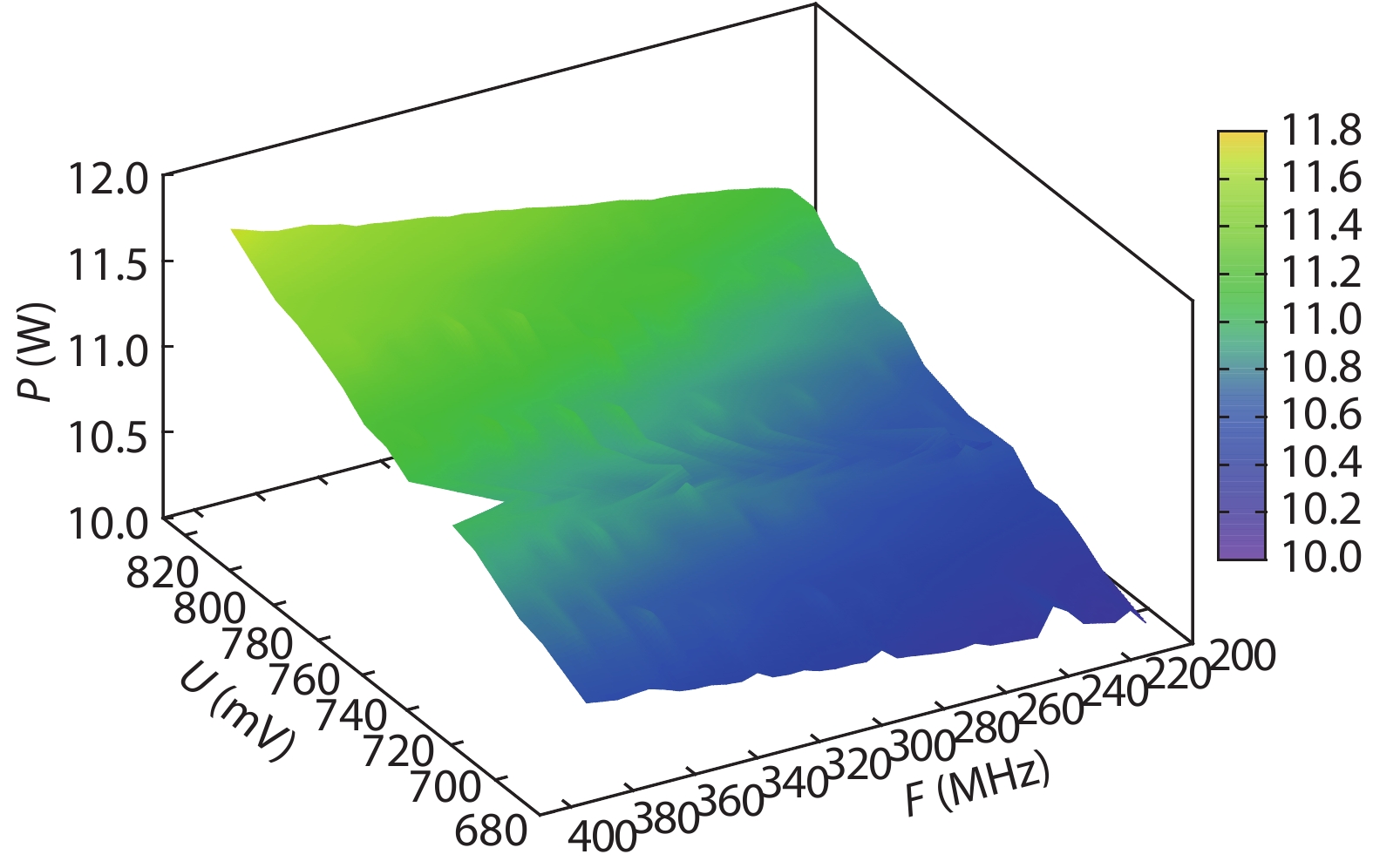
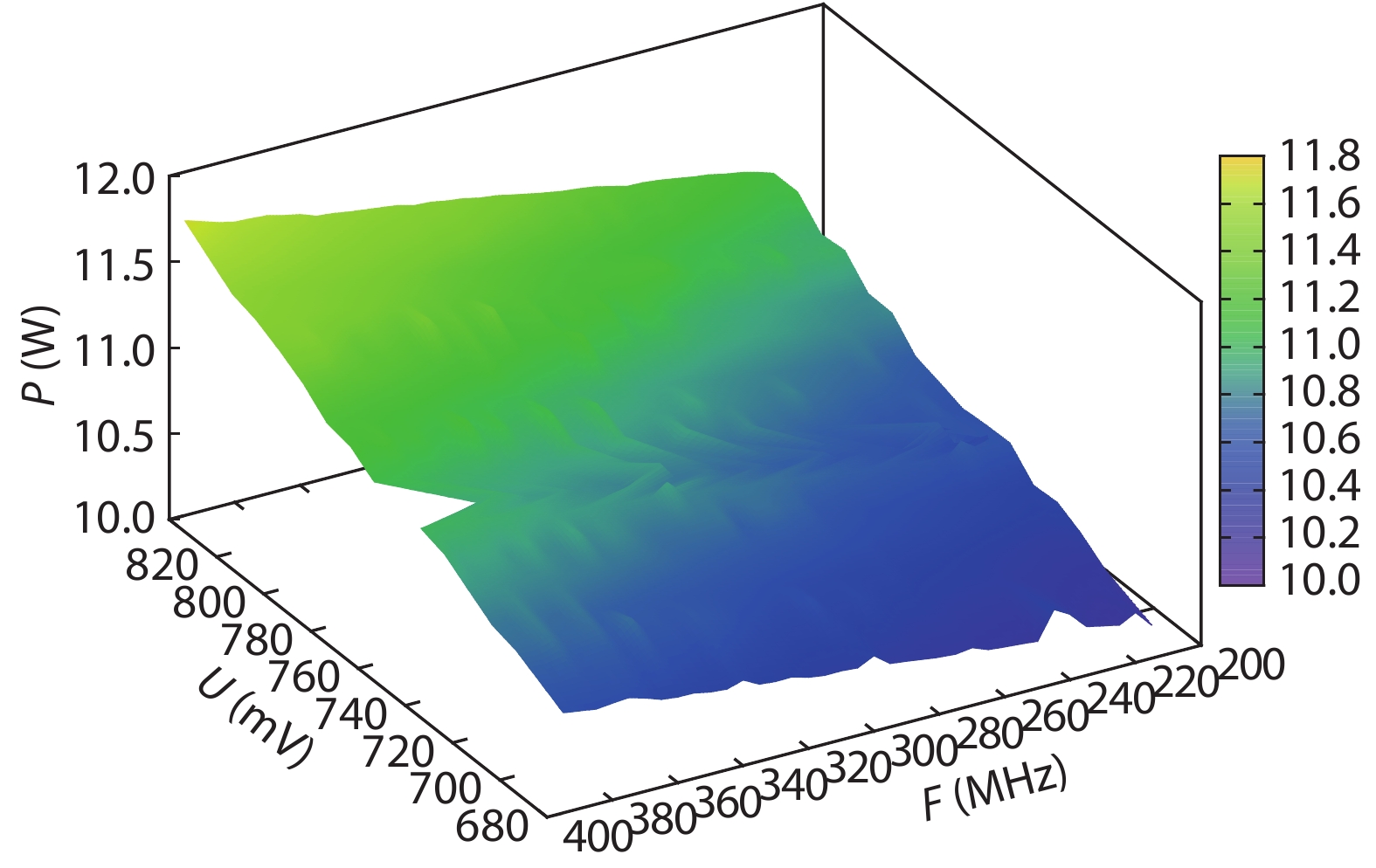
Table 1. Resource utilization of the system.
| Resource | LUT | LUTRAM | FF | BRAM | DSP |
| SkyNet total | 54639 | 1984 | 65196 | 209 | 333 |
| Accelerator | 49934 | 921 | 57101 | 209 | 333 |
| AXI bus | 4691 | 1062 | 8030 | 0 | 0 |
| System reset | 14 | 1 | 65 | 0 | 0 |
| SkyNet DVFS total | 56902 | 2084 | 66781 | 209 | 333 |
| Accelerator | 49910 | 921 | 56095 | 209 | 333 |
| AXI bus | 5799 | 1161 | 9127 | 0 | 0 |
| DFS module | 1164 | 0 | 1492 | 0 | 0 |
| System reset | 29 | 2 | 67 | 0 | 0 |
| Total | 230400 | 101760 | 460800 | 312 | 1728 |
 DownLoad: CSV
DownLoad: CSV
| [1] |
Nurvitadhi E, Venkatesh G, Sim J, et al. Can FPGAs beat GPUs in accelerating next-generation deep neural networks. Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2017
|
| [2] |
Mantovani P, Cota E G, Tien K, et al. An FPGA-based infrastructure for fine-grained DVFS analysis in high-performance embedded systems. Proceedings of the 53rd Annual Design Automation Conference, 2016
|
| [3] |
Bai L, Zhao Y, Huang X. A CNN accelerator on FPGA using depthwise separable convolution. IEEE Trans Circuits Syst II, 2018, 65(10), 1415 doi: 10.1109/TCSII.2018.2865896
|
| [4] |
Ma Y, Cao Y, Vrudhula S, et al. An automatic RTL compiler for high-throughput FPGA implementation of diverse deep convolutional neural networks. 27th International Conference on Field Programmable Logic and Applications (FPL), 2017
|
| [5] |
Ma Y, Cao Y, Vrudhula S, et al. Optimizing loop operation and dataflow in FPGA acceleration of deep convolutional neural networks. Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2017
|
| [6] |
Ma Y, Kim M, Cao Y, et al. End-to-end scalable FPGA accelerator for deep residual networks. 2017 IEEE International Symposium on Circuits and Systems (ISCAS), 2017
|
| [7] |
Wei X, Liang Y, Li X, et al. TGPA: tile-grained pipeline architecture for low latency CNN inference. 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), 2018
|
| [8] |
Guo K, Sui L, Qiu J, et al. Angel-eye: A complete design flow for mapping CNN onto embedded FPGA. IEEE Trans Comput-Aid Des Integr Circuits Syst, 2018, 37(1), 35 doi: 10.1109/TCAD.2017.2705069
|
| [9] |
Ma Y, Cao Y, Vrudhula S, et al. Performance modeling for cnn inference accelerators on FPGA. IEEE Trans Comput-Aid Des Integr Circuits Syst, 2019 doi: 10.1109/TCAD.2019.2897634
|
| [10] |
Qiu J, Wang J, Yao S, et al. Going deeper with embedded FPGA platform for convolutional neural network. Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2016
|
| [11] |
Zhang X, Wang J, Zhu C, et al. Dnnbuilder: an automated tool for building high-performance DNN hardware accelerators for FPGAs. Proceedings of the International Conference on Computer-Aided Design, 2018
|
| [12] |
Motamedi M, Fong D, Ghiasi S. Machine intelligence on resource-constrained IoT devices: The case of thread granularity optimization for CNN inference. ACM Trans Embedded Comput Syst, 2017, 16(5s), 151 doi: 10.1145/3126555
|
| [13] |
Xiao Q, Liang Y, Lu L, et al. Exploring heterogeneous algorithms for accelerating deep convolutional neural networks on FPGAs. 2017 54th ACM/EDAC/IEEE Design Automation Conference (DAC), 2017
|
| [14] |
Dutta S, Bai Z, Low T M, et al. Codenet: Training large scale neural networks in presence of soft-errors. arXiv preprint arXiv: 190301042, 2019
|
| [15] |
Nie B, Tiwari D, Gupta S, et al. A large-scale study of soft-errors on GPUs in the field. 2016 IEEE International Symposium on High Performance Computer Architecture (HPCA), 2016
|
| [16] |
Chen Y, Zhu Y, Qiao F, et al. Evaluating data resilience in CNNs from an approximate memory perspective. Proceedings of the on Great Lakes Symposium on VLSI, 2017, 89
|
| [17] |
Qiao A, Aragam B, Zhang B, et al. Fault tolerance in iterative-convergent machine learning. arXiv preprint arXiv: 1810.07354, 2018
|
| [18] |
Nunez-Yanez J L. Adaptive voltage scaling with in-situ detectors in commercial FPGAs. IEEE Trans Comput, 2014, 64(1), 45 doi: 10.1109/TC.2014.2365963
|
| [19] |
Nabina A, Nunez-Yanez J L. Adaptive voltage scaling in a dynamically reconfigurable FPGA-based platform. ACM Trans Reconfig Technol Syst, 2012, 5(4), 20 doi: 10.1145/2392616.2392618
|
| [20] |
Wei X, Liang Y, Cong J. Overcoming data transfer bottlenecks in FPGA-based DNN accelerators via layer conscious memory management. DAC, 2019, 125
|
| [21] |
Ding C, Wang S, Liu N, et al. Req-yolo: A resource-aware, efficient quantization framework for object detection on FPGAs. Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2019
|
| [22] |
Zhang X, Hao C, Li Y, et al. A bi-directional co-design approach to enable deep learning on IoT devices. arXiv preprint arXiv: 190508369, 2019
|
| [23] |
Hao C, Zhang X, Li Y, et al. FPGA/DNN co-design: An efficient design methodology for IoT intelligence on the edge. Proceedings of the 56th Annual Design Automation Conference, 2019
|
| [24] |
Nunez-Yanez J L. Energy proportional neural network inference with adaptive voltage and frequency scaling. IEEE Trans Comput, 2018, 99(99), 1 doi: 10.1109/TC.2018.2879333
|
| [25] |
Zhang X, Hao C, Lu H, et al., Skynet: A champion design for DAC-SDC on low power object detection. arXiv preprint arXiv: 190610327, 2019
|
| [26] |
Weissel A, Bellosa F, Process cruise control: event-driven clock scaling for dynamic power management. Proceedings of the 2002 International Conference on Compilers, Architecture, and Synthesis for Embedded Systems, 2002
|
| [27] |
De Vogeleer K, Memmi G, Jouvelot P, et al. The energy/frequency convexity rule: Modeling and experimental validation on mobile devices. International Conference on Parallel Processing and Applied Mathematics, 2013
|
| [28] |
Huang H, Chaturvedi V, Quan G, et al. Throughput maximization for periodic real-time systems under the maximal temperature constraint. ACM Trans Embed Comput Syst, 2014, 13(2s), 70 doi: 10.1145/2544375.2544390
|
| [29] |
Yu H, Syed R, Ha Y. Thermal-aware frequency scaling for adaptive workloads on heterogeneous MPSoCs. Proceedings of the Conference on Design, Automation & Test in Europe, 2014
|
| [30] |
Yu H, Ha Y, Wang J. Quality optimization of resilient applications under temperature constraints. Proceedings of the Computing Frontiers Conference, 2017
|
| [31] |
Ma Y, Chantem T, Dick R P, et al. Improving system-level lifetime reliability of multicore soft real-time systems. IEEE Trans Very Large Scale Integr Syst, 2017, 25(6), 1895 doi: 10.1109/TVLSI.2017.2669144
|
| [32] |
Bong K, Choi S, Kim C, et al. Low-power convolutional neural network processor for a face-recognition system. IEEE Micro, 2017, 37(6), 30 doi: 10.1109/MM.2017.4241350
|
| [33] |
Santoro G, Casu M R, Peluso V, et al. Design-space exploration of pareto-optimal architectures for deep learning with DVFS. 2018 IEEE International Symposium on Circuits and Systems (ISCAS), 2018
|
| [34] |
Hsieh G C, Hung J C. Phase-locked loop techniques. A survey. IEEE Trans Indust Electron, 1996, 43(6), 609 doi: 10.1109/41.544547
|
| [35] |
Kim J H, Kwak Y H, Kim M, et al. A 120-MHz–1.8-GHz CMOS dll-based clock generator for dynamic frequency scaling. IEEE J Solid-State Circuits, 2006, 41(9), 2077 doi: 10.1109/JSSC.2006.880609
|
| [36] |
Brynjolfson I, Zilic Z. Dynamic clock management for low power applications in FPGAs. Proceedings of the IEEE 2000 Custom Integrated Circuits Conference, 2000
|
| [37] |
Beldachi A F, Nunez-Yanez J L. Run-time power and performance scaling in 28 nm FPGAs. IET Comput Digit Tech, 2014, 8(4), 178
|
| [38] |
Beldachi A F, Nunez-Yanez J L. Accurate power control and monitoring in zynq boards. 2014 24th International Conference on Field Programmable Logic and Applications (FPL), 2014
|
| [39] |
Hosseinabady M, Nunez-Yanez J L. Run-time power gating in hybrid arm-FPGA devices. 2014 24th International Conference on Field Programmable Logic and Applications (FPL), 2014
|









Article views: 6263 Times PDF downloads: 122 Times Cited by: 0 Times
Received: 17 September 2019 Revised: 13 November 2019 Online: Accepted Manuscript: 17 December 2019Uncorrected proof: 18 December 2019Published: 11 February 2020
| Citation: |
Weixiong Jiang, Heng Yu, Jiale Zhang, Jiaxuan Wu, Shaobo Luo, Yajun Ha. Optimizing energy efficiency of CNN-based object detection with dynamic voltage and frequency scaling[J]. Journal of Semiconductors, 2020, 41(2): 022406. doi: 10.1088/1674-4926/41/2/022406
****
W X Jiang, H Yu, J L Zhang, J X Wu, S B Luo, Y J Ha, Optimizing energy efficiency of CNN-based object detection with dynamic voltage and frequency scaling[J]. J. Semicond., 2020, 41(2): 022406. doi: 10.1088/1674-4926/41/2/022406.

|
| [1] |
Nurvitadhi E, Venkatesh G, Sim J, et al. Can FPGAs beat GPUs in accelerating next-generation deep neural networks. Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2017
|
| [2] |
Mantovani P, Cota E G, Tien K, et al. An FPGA-based infrastructure for fine-grained DVFS analysis in high-performance embedded systems. Proceedings of the 53rd Annual Design Automation Conference, 2016
|
| [3] |
Bai L, Zhao Y, Huang X. A CNN accelerator on FPGA using depthwise separable convolution. IEEE Trans Circuits Syst II, 2018, 65(10), 1415 doi: 10.1109/TCSII.2018.2865896
|
| [4] |
Ma Y, Cao Y, Vrudhula S, et al. An automatic RTL compiler for high-throughput FPGA implementation of diverse deep convolutional neural networks. 27th International Conference on Field Programmable Logic and Applications (FPL), 2017
|
| [5] |
Ma Y, Cao Y, Vrudhula S, et al. Optimizing loop operation and dataflow in FPGA acceleration of deep convolutional neural networks. Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2017
|
| [6] |
Ma Y, Kim M, Cao Y, et al. End-to-end scalable FPGA accelerator for deep residual networks. 2017 IEEE International Symposium on Circuits and Systems (ISCAS), 2017
|
| [7] |
Wei X, Liang Y, Li X, et al. TGPA: tile-grained pipeline architecture for low latency CNN inference. 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), 2018
|
| [8] |
Guo K, Sui L, Qiu J, et al. Angel-eye: A complete design flow for mapping CNN onto embedded FPGA. IEEE Trans Comput-Aid Des Integr Circuits Syst, 2018, 37(1), 35 doi: 10.1109/TCAD.2017.2705069
|
| [9] |
Ma Y, Cao Y, Vrudhula S, et al. Performance modeling for cnn inference accelerators on FPGA. IEEE Trans Comput-Aid Des Integr Circuits Syst, 2019 doi: 10.1109/TCAD.2019.2897634
|
| [10] |
Qiu J, Wang J, Yao S, et al. Going deeper with embedded FPGA platform for convolutional neural network. Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2016
|
| [11] |
Zhang X, Wang J, Zhu C, et al. Dnnbuilder: an automated tool for building high-performance DNN hardware accelerators for FPGAs. Proceedings of the International Conference on Computer-Aided Design, 2018
|
| [12] |
Motamedi M, Fong D, Ghiasi S. Machine intelligence on resource-constrained IoT devices: The case of thread granularity optimization for CNN inference. ACM Trans Embedded Comput Syst, 2017, 16(5s), 151 doi: 10.1145/3126555
|
| [13] |
Xiao Q, Liang Y, Lu L, et al. Exploring heterogeneous algorithms for accelerating deep convolutional neural networks on FPGAs. 2017 54th ACM/EDAC/IEEE Design Automation Conference (DAC), 2017
|
| [14] |
Dutta S, Bai Z, Low T M, et al. Codenet: Training large scale neural networks in presence of soft-errors. arXiv preprint arXiv: 190301042, 2019
|
| [15] |
Nie B, Tiwari D, Gupta S, et al. A large-scale study of soft-errors on GPUs in the field. 2016 IEEE International Symposium on High Performance Computer Architecture (HPCA), 2016
|
| [16] |
Chen Y, Zhu Y, Qiao F, et al. Evaluating data resilience in CNNs from an approximate memory perspective. Proceedings of the on Great Lakes Symposium on VLSI, 2017, 89
|
| [17] |
Qiao A, Aragam B, Zhang B, et al. Fault tolerance in iterative-convergent machine learning. arXiv preprint arXiv: 1810.07354, 2018
|
| [18] |
Nunez-Yanez J L. Adaptive voltage scaling with in-situ detectors in commercial FPGAs. IEEE Trans Comput, 2014, 64(1), 45 doi: 10.1109/TC.2014.2365963
|
| [19] |
Nabina A, Nunez-Yanez J L. Adaptive voltage scaling in a dynamically reconfigurable FPGA-based platform. ACM Trans Reconfig Technol Syst, 2012, 5(4), 20 doi: 10.1145/2392616.2392618
|
| [20] |
Wei X, Liang Y, Cong J. Overcoming data transfer bottlenecks in FPGA-based DNN accelerators via layer conscious memory management. DAC, 2019, 125
|
| [21] |
Ding C, Wang S, Liu N, et al. Req-yolo: A resource-aware, efficient quantization framework for object detection on FPGAs. Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2019
|
| [22] |
Zhang X, Hao C, Li Y, et al. A bi-directional co-design approach to enable deep learning on IoT devices. arXiv preprint arXiv: 190508369, 2019
|
| [23] |
Hao C, Zhang X, Li Y, et al. FPGA/DNN co-design: An efficient design methodology for IoT intelligence on the edge. Proceedings of the 56th Annual Design Automation Conference, 2019
|
| [24] |
Nunez-Yanez J L. Energy proportional neural network inference with adaptive voltage and frequency scaling. IEEE Trans Comput, 2018, 99(99), 1 doi: 10.1109/TC.2018.2879333
|
| [25] |
Zhang X, Hao C, Lu H, et al., Skynet: A champion design for DAC-SDC on low power object detection. arXiv preprint arXiv: 190610327, 2019
|
| [26] |
Weissel A, Bellosa F, Process cruise control: event-driven clock scaling for dynamic power management. Proceedings of the 2002 International Conference on Compilers, Architecture, and Synthesis for Embedded Systems, 2002
|
| [27] |
De Vogeleer K, Memmi G, Jouvelot P, et al. The energy/frequency convexity rule: Modeling and experimental validation on mobile devices. International Conference on Parallel Processing and Applied Mathematics, 2013
|
| [28] |
Huang H, Chaturvedi V, Quan G, et al. Throughput maximization for periodic real-time systems under the maximal temperature constraint. ACM Trans Embed Comput Syst, 2014, 13(2s), 70 doi: 10.1145/2544375.2544390
|
| [29] |
Yu H, Syed R, Ha Y. Thermal-aware frequency scaling for adaptive workloads on heterogeneous MPSoCs. Proceedings of the Conference on Design, Automation & Test in Europe, 2014
|
| [30] |
Yu H, Ha Y, Wang J. Quality optimization of resilient applications under temperature constraints. Proceedings of the Computing Frontiers Conference, 2017
|
| [31] |
Ma Y, Chantem T, Dick R P, et al. Improving system-level lifetime reliability of multicore soft real-time systems. IEEE Trans Very Large Scale Integr Syst, 2017, 25(6), 1895 doi: 10.1109/TVLSI.2017.2669144
|
| [32] |
Bong K, Choi S, Kim C, et al. Low-power convolutional neural network processor for a face-recognition system. IEEE Micro, 2017, 37(6), 30 doi: 10.1109/MM.2017.4241350
|
| [33] |
Santoro G, Casu M R, Peluso V, et al. Design-space exploration of pareto-optimal architectures for deep learning with DVFS. 2018 IEEE International Symposium on Circuits and Systems (ISCAS), 2018
|
| [34] |
Hsieh G C, Hung J C. Phase-locked loop techniques. A survey. IEEE Trans Indust Electron, 1996, 43(6), 609 doi: 10.1109/41.544547
|
| [35] |
Kim J H, Kwak Y H, Kim M, et al. A 120-MHz–1.8-GHz CMOS dll-based clock generator for dynamic frequency scaling. IEEE J Solid-State Circuits, 2006, 41(9), 2077 doi: 10.1109/JSSC.2006.880609
|
| [36] |
Brynjolfson I, Zilic Z. Dynamic clock management for low power applications in FPGAs. Proceedings of the IEEE 2000 Custom Integrated Circuits Conference, 2000
|
| [37] |
Beldachi A F, Nunez-Yanez J L. Run-time power and performance scaling in 28 nm FPGAs. IET Comput Digit Tech, 2014, 8(4), 178
|
| [38] |
Beldachi A F, Nunez-Yanez J L. Accurate power control and monitoring in zynq boards. 2014 24th International Conference on Field Programmable Logic and Applications (FPL), 2014
|
| [39] |
Hosseinabady M, Nunez-Yanez J L. Run-time power gating in hybrid arm-FPGA devices. 2014 24th International Conference on Field Programmable Logic and Applications (FPL), 2014
|

 WeChat ID
WeChat ID
Journal of Semiconductors © 2017 All Rights Reserved 京ICP备05085259号-2