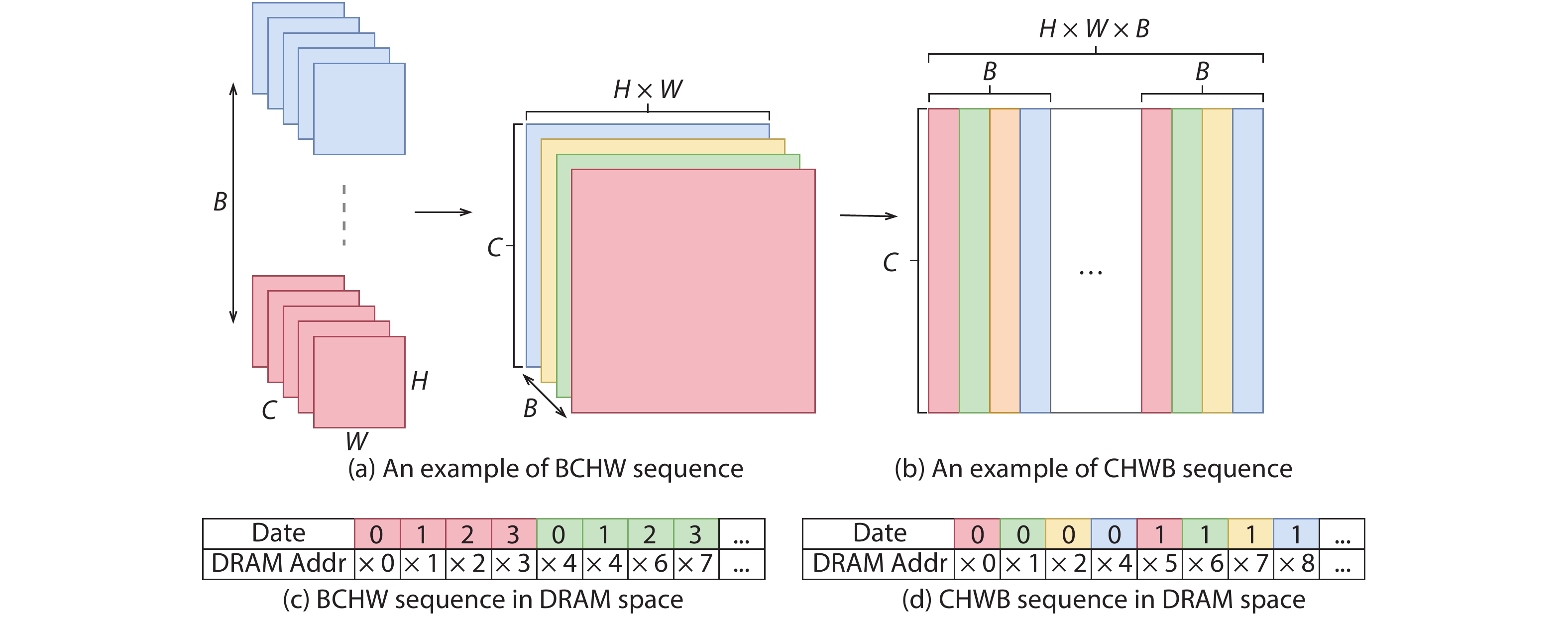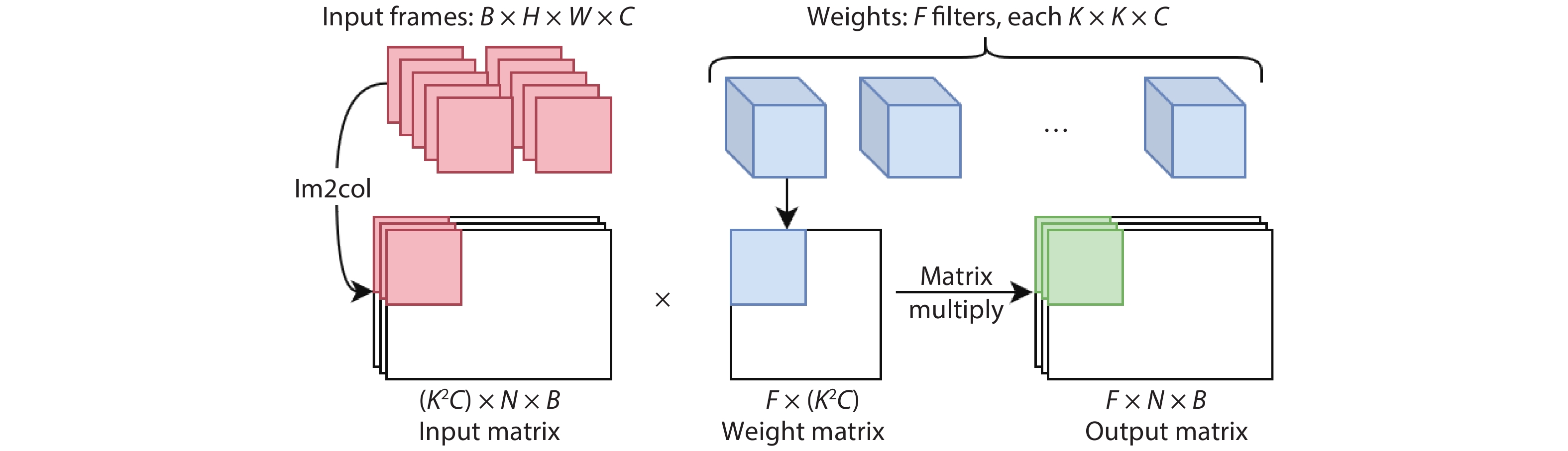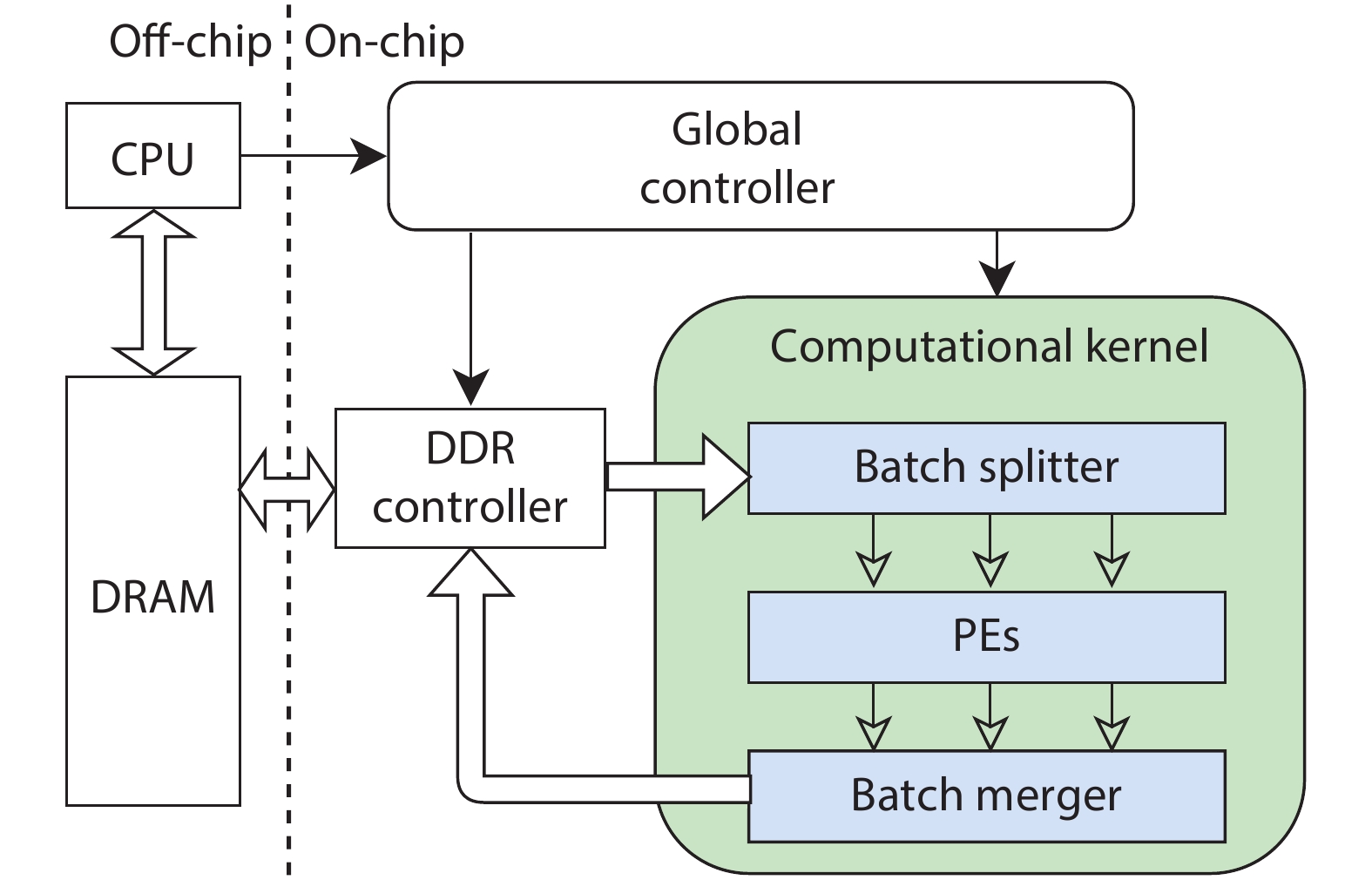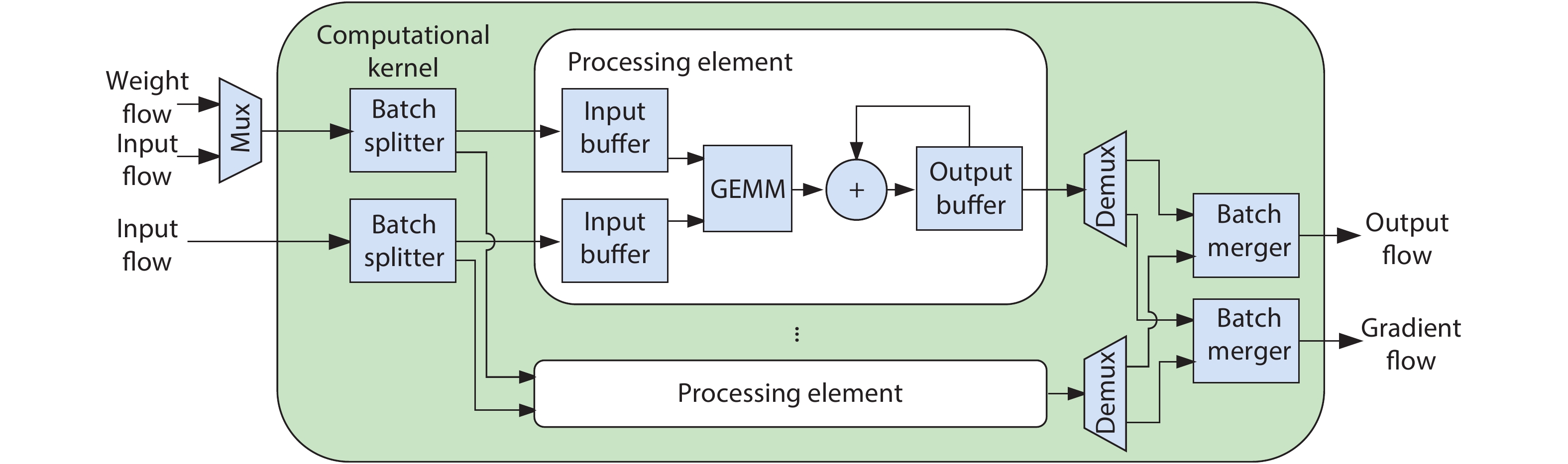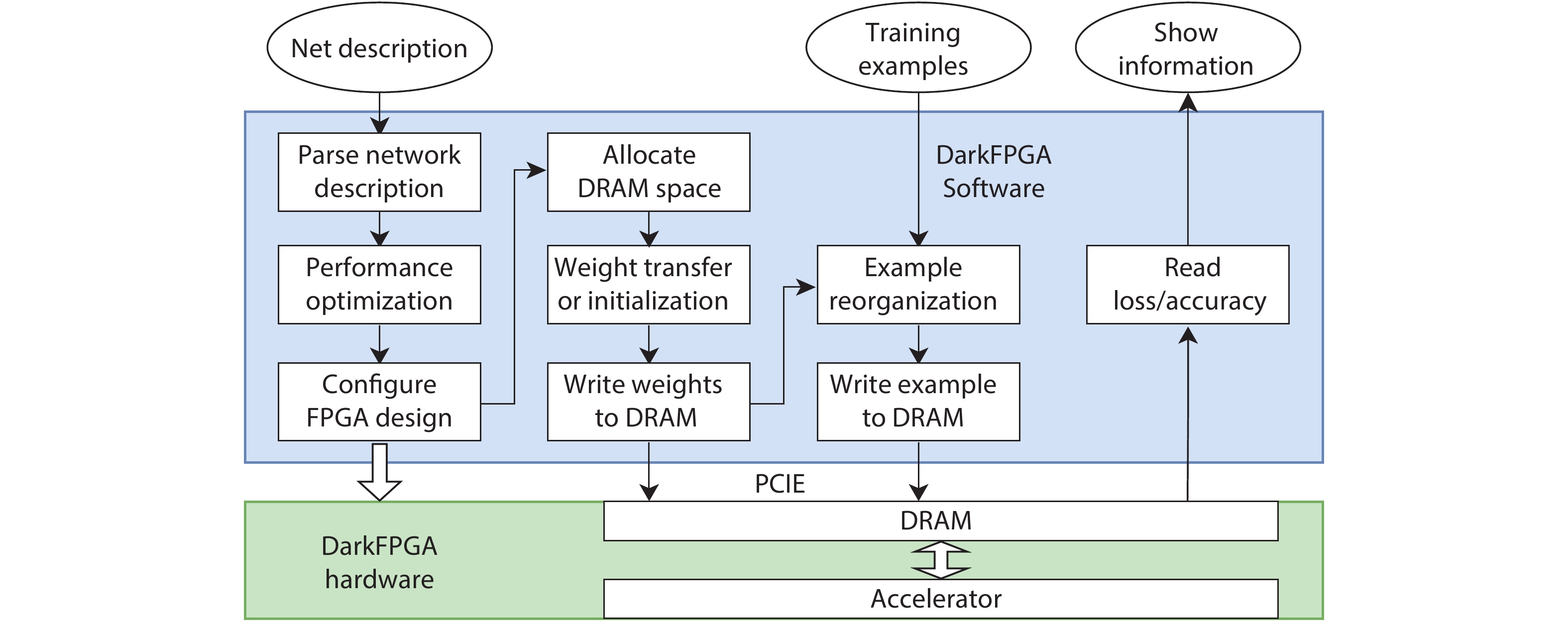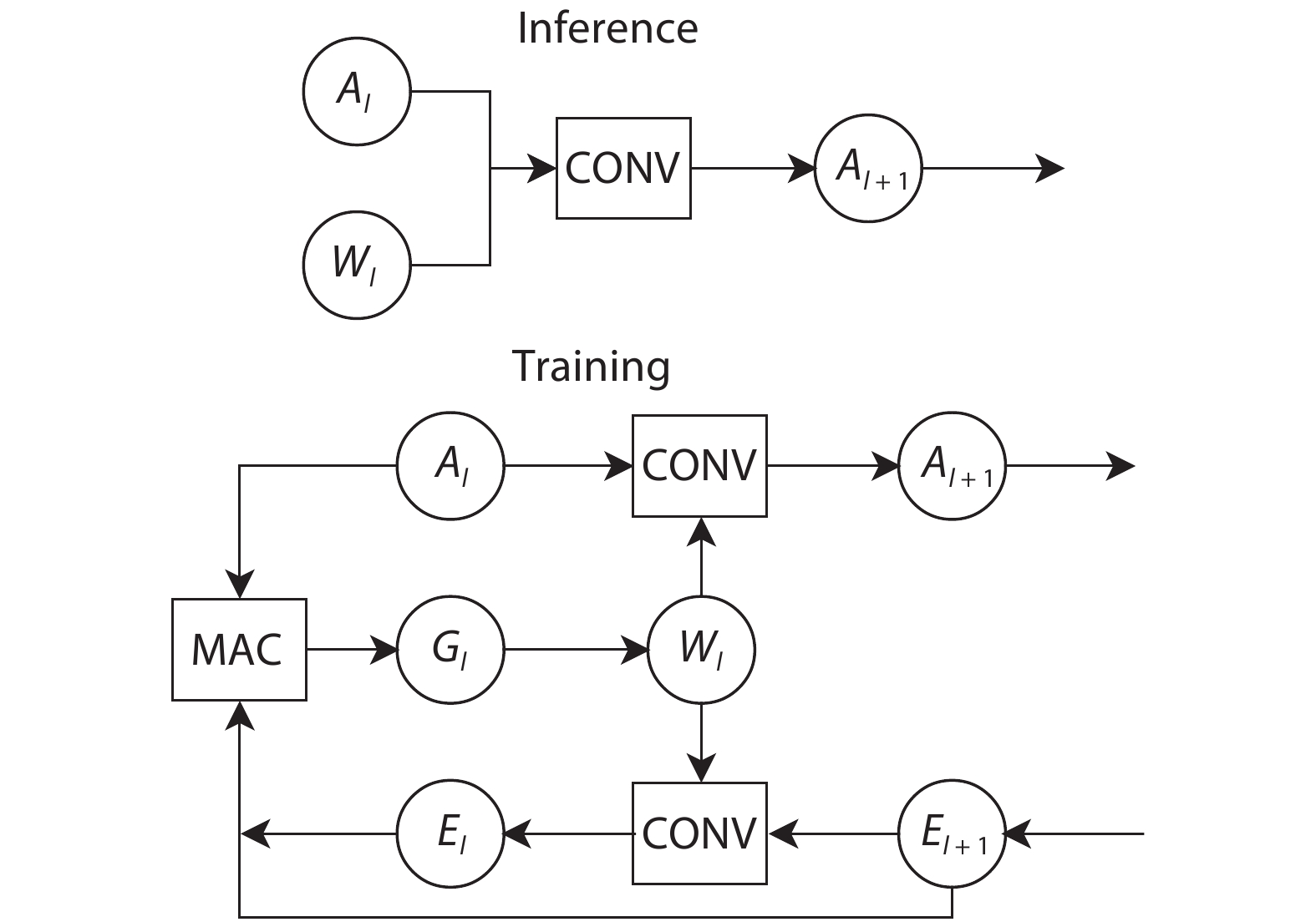
Fig. 1.
A overview of inference and training processes on the convolutional layer.
ARTICLES
Cheng Luo1, , Man-Kit Sit2, Hongxiang Fan2, Shuanglong Liu2, Wayne Luk2 and Ce Guo2
Corresponding author: Cheng Luo, Email: 16110720014@fudan.edu.cn
Abstract: Training deep neural networks (DNNs) requires a significant amount of time and resources to obtain acceptable results, which severely limits its deployment in resource-limited platforms. This paper proposes DarkFPGA, a novel customizable framework to efficiently accelerate the entire DNN training on a single FPGA platform. First, we explore batch-level parallelism to enable efficient FPGA-based DNN training. Second, we devise a novel hardware architecture optimised by a batch-oriented data pattern and tiling techniques to effectively exploit parallelism. Moreover, an analytical model is developed to determine the optimal design parameters for the DarkFPGA accelerator with respect to a specific network specification and FPGA resource constraints. Our results show that the accelerator is able to perform about 10 times faster than CPU training and about a third of the energy consumption than GPU training using 8-bit integers for training VGG-like networks on the CIFAR dataset for the Maxeler MAX5 platform.
Keywords: deep neural network, training, FPGA, batch-level parallelism
| [1] |
LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition. Proc IEEE, 1998
|
| [2] |
Russakovsky O, Deng J, Su H, et al. Imagenet large scale visual recognition challenge. IJCV, 2015
|
| [3] |
Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in Neural Information Processing Systems, 2015, 91
|
| [4] |
He K, Gkioxari G, Dollár P, et al. Mask r-cnn. Proceedings of the IEEE International Conference on Computer Vision, 2017, 2961
|
| [5] |
Jia Y, Learning semantic image representations at a large scale. PhD Thesis, UC Berkeley, 2014
|
| [6] |
Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015
|
| [7] |
Umuroglu Y, Fraser N J, Gambardella G, et al. Finn: A framework for fast, scalable binarized neural network inference. Acm/sigda International Symposium on Field-Programmable Gate Arrays, 2016
|
| [8] |
Nurvitadhi E, Venkatesh G, Sim J, et al. Can FPGAs beat GPUs in accelerating next-generation deep neural networks. ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2017
|
| [9] |
Guo K, Zeng S, Yu J, et al. A survey of FPGA-based neural network accelerator. arXiv: 171208934, 2017
|
| [10] |
Parisi G I, Kemker R, Part J L, et al. Continual lifelong learning with neural networks: A review. arXiv: 180207569, 2018
|
| [11] |
Micikevicius P, Narang S, Alben J, et al. Mixed precision training. arXiv: 171003740, 2017
|
| [12] |
Das D, Mellempudi N, Mudigere D, et al. Mixed precision training of convolutional neural networks using integer operations. arXiv: 180200930, 2018
|
| [13] |
Banner R, Hubara I, Hoffer E, et al. Scalable methods for 8-bit training of neural networks. arXiv: 180511046, 2018
|
| [14] |
De Sa C, Leszczynski M, Zhang J, et al. High-accuracy low-precision training. arXiv: 180303383, 2018
|
| [15] |
Wu S, Li G, Chen F, et al. Training and inference with integers in deep neural networks. arXiv: 180204680, 2018
|
| [16] |
Wen W, Xu C, Yan F, et al. Terngrad: Ternary gradients to reduce communication in distributed deep learning. Advances in Neural Information Processing Systems, 2017
|
| [17] |
Zhu H, Akrout M, Zheng B, et al. Benchmarking and analyzing deep neural network training. IEEE International Symposium on Workload Characterization (IISWC), 2018
|
| [18] |
Redmon J. Darknet: Open source neural networks in C. http://pjreddie.com/darknet/
|
| [19] |
Pell O, Mencer O, Tsoi K H, et al. Maximum performance computing with dataflow engines. High-performance computing using FPGAs, 2013
|
| [20] |
Luo C, Sit M K, Fan H, et al. Towards efficient deep neural network training by FPGA-based batch-level parallelism. 2019 IEEE 27th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), 2019, 45
|
| [21] |
Kingma D P, Ba J. Adam: A method for stochastic optimization. arXiv: 14126980, 2014
|
| [22] |
Qiu J, Wang J, Yao S, et al. Going deeper with embedded FPGA platform for convolutional neural network. Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2016
|
| [23] |
Suda N, Chandra V, Dasika G, et al. Throughput-optimized opencl-based FPGA accelerator for large-scale convolutional neural networks. Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2016
|
| [24] |
Motamedi M, Gysel P, Akella V, et al. Design space exploration of FPGA-based deep convolutional neural networks. ASP-DAC, 2016
|
| [25] |
Zhang C, Sun G, Fang Z, et al. Caffeine: Towards uniformed representation and acceleration for deep convolutional neural networks. IEEE Trans Comput-Aid Des Integr Circuits Syst, 2019, 38, 2072 doi: 10.1109/TCAD.2017.2785257
|
| [26] |
Ma Y, Cao Y, Vrudhula S, et al. An automatic rtl compiler for high-throughput FPGA implementation of diverse deep convolutional neural networks. 2017 27th International Conference on Field Programmable Logic and Applications (FPL), 2017, 1
|
| [27] |
Venkataramanaiah S K, Ma Y, Yin S, et al. Automatic compiler based FPGA accelerator for cnn training. 2019 29th International Conference on Field Programmable Logic and Applications (FPL), 2019, 166
|
| [28] |
Xiao Q, Liang Y, Lu L, et al. Exploring heterogeneous algorithms for accelerating deep convolutional neural networks on FPGAs. Proceedings of the 54th Annual Design Automation Conference, 2017
|
| [29] |
Zhao W, Fu H, Luk W, et al. F-CNN: An FPGA-based framework for training convolutional neural networks. IEEE 27th International Conference on Application-specific Systems, Architectures and Processors (ASAP), 2016
|
| [30] |
Geng T, Wang T, Li A, et al. A scalable framework for acceleration of cnn training on deeply-pipelined FPGA clusters with weight and workload balancing. arXiv: 190101007, 2019
|
| [31] |
Geng T, Wang T, Sanaullah A, et al. Fpdeep: Acceleration and load balancing of CNN training on FPGA clusters. IEEE 26th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), 2018
|
| [32] |
Li Y, Pedram A, Caterpillar: Coarse grain reconfigurable architecture for accelerating the training of deep neural networks. IEEE 28th International Conference on Application-Specific Systems, Architectures and Processors (ASAP), 2017
|
| [33] |
Dicecco R, Sun L, Chow P. FPGA-based training of convolutional neural networks with a reduced precision floating-point library. International Conference on Field Programmable Technology, 2018
|
| [34] |
Nakahara H, Sada Y, Shimoda M, et al. FPGA-based training accelerator utilizing sparseness of convolutional neural network. 2019 29th International Conference on Field Programmable Logic and Applications (FPL), 2019, 180
|
| [35] |
Fox S, Faraone J, Boland D, et al. Training deep neural networks in low-precision with high accuracy using FPGAs. International Conference on Field-Programmable Technology (FPT), 2019
|
| [36] |
Moss D J, Krishnan S, Nurvitadhi E, et al. A customizable matrix multiplication framework for the Intel HARPv2 Xeon+ FPGA platform: A deep learning case study. ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2018, 107
|
| [37] |
He K, Zhang X, Ren S, et al. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. Proceedings of the IEEE International Conference on Computer Vision, 2015, 1026
|
| [38] |
Zhou S, Wu Y, Ni Z, et al. Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients. arXiv preprint arXiv: 160606160, 2016
|
| [39] |
Matsumoto M, Nishimura T. Mersenne twister: a 623-dimensionally equidistributed uniform pseudo-random number generator. ACM Trans Model Comput Simul, 1998, 8(1), 3 doi: 10.1145/272991.272995
|
| [40] |
Performance guide of using nchw image data format. [Online]. Available: https://www.tensorflow.org/guide/performance/overview
|
| [41] |
Ma Y, Cao Y, Vrudhula S, et al. Optimizing loop operation and dataflow in FPGA acceleration of deep convolutional neural networks. Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2017
|
| [42] |
Steinkraus D, Buck I, Simard P. Using GPUs for machine learning algorithms. Eighth International Conference on Document Analysis and Recognition (ICDAR), 2005
|
| [43] |
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv: 14091556, 2014
|
| [44] |
Wei X, Yu C H, Zhang P, et al. Automated systolic array architecture synthesis for high throughput cnn inference on FPGAs. Proceedings of the 54th Annual Design Automation Conference, 2017,
|
| [45] |
Krishnan S, Ratusziak P, Johnson C, et al. Accelerator templates and runtime support for variable precision CNN. CISC Workshop, 2017
|
| [46] |
Abadi M, Barham P, Chen J, et al. TensorFlow: a system for large-scale machine learning. OSDI, 2016, 265
|
| [47] |
Chetlur S, Woolley C, Vandermersch P, et al. cuDNN: Efficient primitives for deep learning. arXiv: 14100759, 2014
|
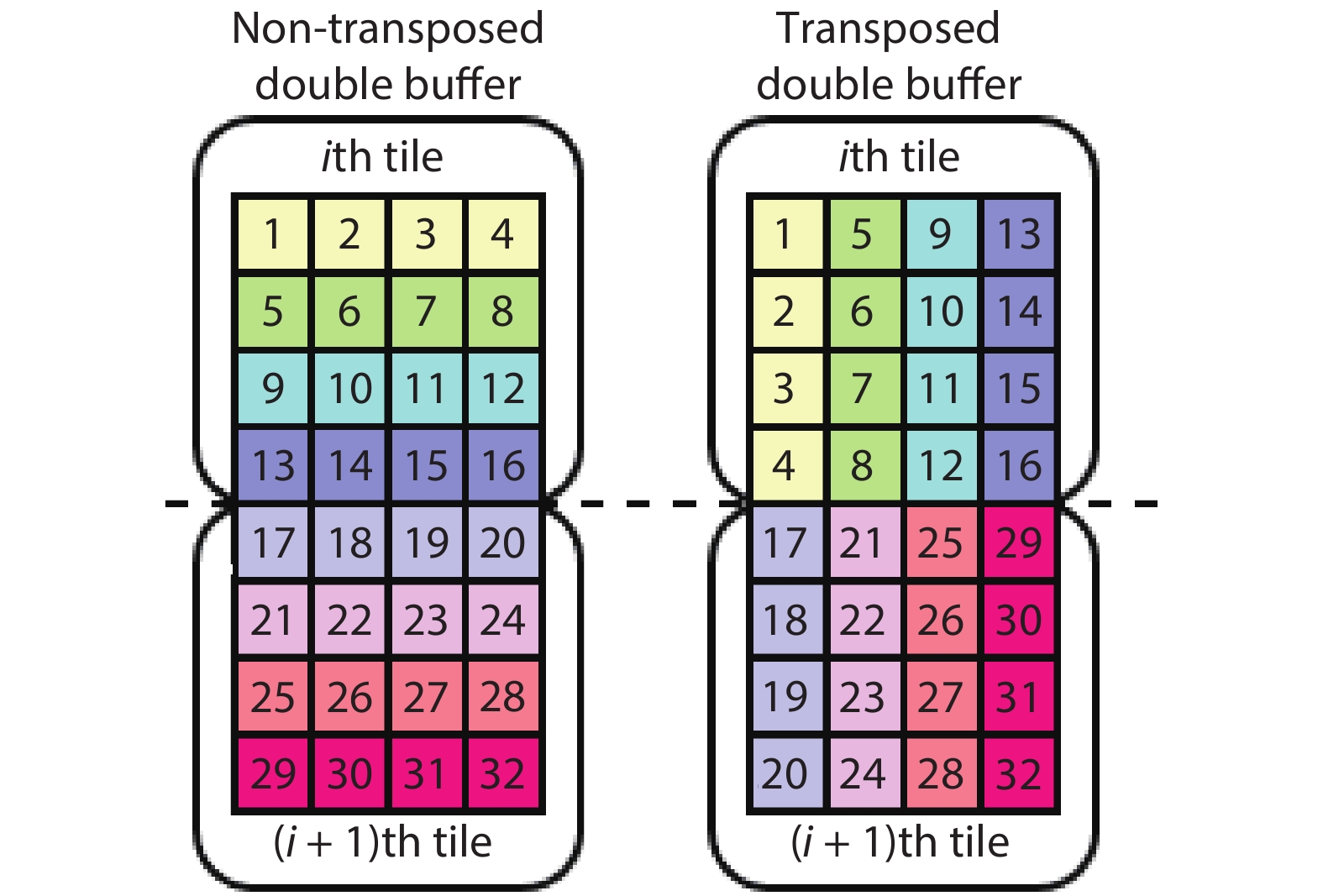
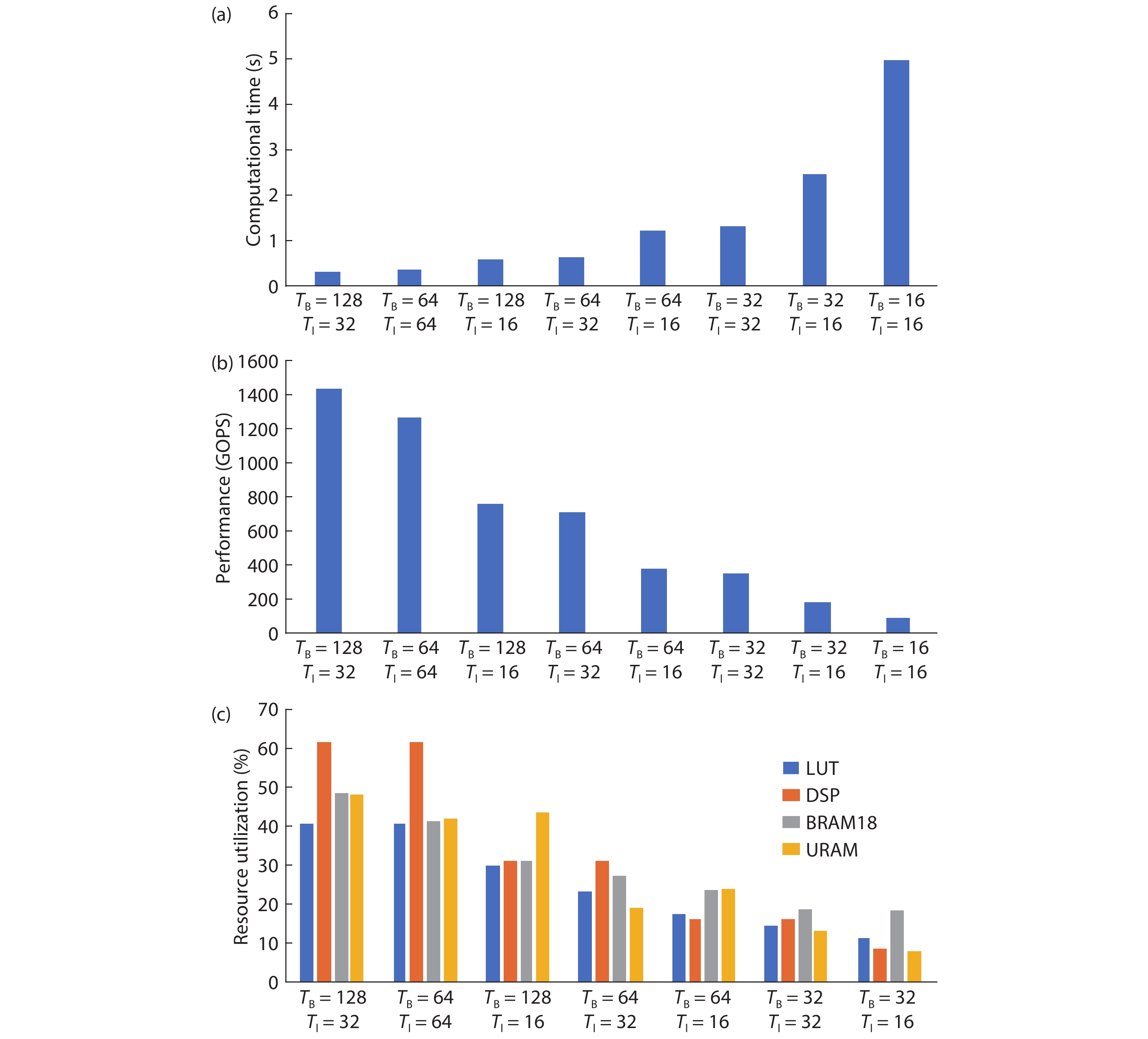
Table 1. Parameters for FPGA training.
| Parameter | Description |
| the batch size of training examples | |
| the size of channel | |
| the size of filter | |
| the kernel size of weights | |
| the height of frames | |
| the width of frames |
 DownLoad: CSV
DownLoad: CSV
| Algorithm 1: Pseudocode for training convolutional layers |
| 1 Forward propagation: |
| 2 for b = 1 to B do |
| 3 for c = 1 to C × K do |
| 4 for f = 1 to F do |
| 5 for im = 1 to H *W do |
| 6 Al+1[b][f][im] += Wl[f][c] *Al[b][c][im] |
| 7 Backward propagation: |
| 8 for b = 1 to B do |
| 9 for c = 1 to C × K do |
| 10 for f = 1 to F do |
| 11 for im = 1 to H *W do |
| 12 El[b][c][im] += Wl[f][c] *El+1[b][f][im] |
| 13 Gradient Generation: |
| 14 for b = 1 to B do |
| 15 for c = 1 to C × K do |
| 16 for f = 1 to F do |
| 17 for im = 1 to H *W do |
| 18 Gl[b][f][c] += Al[b][c][im] *El+1[b][f][im] |
DownLoad: CSV
Table 2. The network architecture in experiment.
| Layer | B | C | F | H × W | K |
| CONV1 | 128 | 3 | 128 | 32 × 32 | 3 × 3 |
| CONV2 | 128 | 128 | 128 | 32 × 32 | 3 × 3 |
| MAXPOOLING | 128 | 128 | 128 | 16 × 16 | 2 × 2 |
| CONV3 | 128 | 128 | 256 | 16 × 16 | 3 × 3 |
| CONV4 | 128 | 256 | 256 | 16 × 16 | 3 × 3 |
| MAXPOOLING | 128 | 256 | 256 | 8 × 8 | 2 × 2 |
| CONV5 | 128 | 256 | 512 | 8 × 8 | 3 × 3 |
| CONV6 | 128 | 512 | 512 | 8 × 8 | 3 × 3 |
| MAXPOOLING | 128 | 512 | 512 | 4 × 4 | 2 × 2 |
| FC | 128 | 8096 | 1024 | – | – |
| FC | 128 | 1024 | 10 | – | – |
| SSE | 128 | 10 | 10 | – | – |
DownLoad: CSV
Table 3. Performance comparison among FPGA, CPU and GPU.
| Parameter | CPU | GPU | DarkFPGA |
| Platform | Intel Xeon X5690 | GTX 1080 Ti | MAX5 Platform |
| No. of cores | 6 | 3584 | − |
| Compiler | GCC 5.4.0 | CUDA 9.0 | Maxcompiler 2019.2 |
| Flag | -Ofast | − | − |
| Frequency (GHz) | 3.47 | 1.58 | 0.2 |
| Precision | 32-bit floating point | 32-bit floating point | 8-bit fixed point |
| Technology (nm) | 32 | 28 | 16 |
| Processing time per batch (ms) | 66439 (3270) | 126 (53.4) | 331 |
| Threads | 1 (24) | − | − |
| Power (W) | 131 (204) | 187 (217) | 13.5 |
| Energy (J) | 8712 (667.1) | 23.6 (11.6) | 4.5 |
| Energy efficiency | 1x (13x) | 369x (751x) | 1936x |
DownLoad: CSV
Table 4. Performance comparison of different FPGA-based training accelerators.
| Accelerator | Platform | Config | Model dataset | LUTs (kW) | DSPs efficiency | Performance (GOPS) | Throughput (image/s) |
| F-CNN[29] FCCM 16 | Altera Stratix V | 8 FPGA | LeNet-5 MNIST | − | − | − | 7 |
| FPDeep[31] FCCM 18 | Virtex7 VC709 | 10 FPGA | AlexNet imagenet | ≈ 460 per FPGA | ≈ 2880 per FPGA | ≈ 1022 per FPGA | − |
| DiCecco et al.[33] FPGA 18 | Xilinx XCKU115 | 1 FPGA | LeNet-like CIFAR10 | ≈ 530 | ≈ 883 | − | 522 |
| Nakahara et al.[34] FPL 19 | UltraScale+ XCVU9P | 1 FPGA | VGG16 CIFAR10 | 934 | 1106 | − | 4878 |
| Sean et al.[35] FPT 19 | Zynq ZCU111 | 1 FPGA | VGG-16 CIFAR10 | 73.1 | 1037 | − | 3.3 |
| DarkFPGA | UltraScale+ XCVU9P | 1 FPGA | VGG-like CIFAR10 | 480 | 4202 | 1417 | 386.7 |
| (1) '−' means this metrics is not provided on their papers, '≈' indicate that this value is obtained by approximate estimates. (2) The accelerator from Ref. [29] didn't compute the gradients for training. (3) The power consumption of Ref. [29] measured from entire development board when our power consumption is measured from single FPGA chip. | |||||||
DownLoad: CSV
| Algorithm 2: Pseudocode of tiled matrix multiplication |
| 1 Consider that the weight matrix and gradient matrix are transferred into TI × TI tiled blocks, where input frames, output frames and error frames are transferred as 3-dimensions TB × TI × TI tiled blocks. In particular, the input frames and output frames of fully-connected layer are transferred as 2-dimensions TB × TI tiled blocks |
| 2 Convolutional forward propagation: |
| 3 for f = 1 to F/TI do |
| 4 for im = 1 to (H * W)/TI do |
| 5 for b = 1 to B/TB do |
| 6 for c = 1 to C × K/TI do |
| 7 Al+1(b)(f, im)c = Wl(f, c) × Al(b)(c, im) |
| 8 Al+1(b)(f, im) + = Al+1(b)(f, im)c |
| 9 Quantize (Al+1(b)(f, im)) |
| 10 Output Al+1(b)(f, im) |
| 11 Convolutional backward propagation: |
| 12 for c = 1 to |
| 13 for im = 1 to |
| 14 for b = 1 to |
| 15 for f = 1 to |
| 16 |
| 17 |
| 18 Output |
| 19 Convolutional gradients generations: |
| 20 for f = 1 to |
| 21 for c = 1 to |
| 22 for b = 1 to |
| 23 for im = 1 to |
| 24 |
| 25 |
| 26 |
| 27 Output |
| 28 Fully-connected forward propagation: |
| 29 for f = 1 to |
| 30 for b = 1 to |
| 31 for c = 1 to |
| 32 |
| 33 |
| 34 Output |
DownLoad: CSV
| [1] |
LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition. Proc IEEE, 1998
|
| [2] |
Russakovsky O, Deng J, Su H, et al. Imagenet large scale visual recognition challenge. IJCV, 2015
|
| [3] |
Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in Neural Information Processing Systems, 2015, 91
|
| [4] |
He K, Gkioxari G, Dollár P, et al. Mask r-cnn. Proceedings of the IEEE International Conference on Computer Vision, 2017, 2961
|
| [5] |
Jia Y, Learning semantic image representations at a large scale. PhD Thesis, UC Berkeley, 2014
|
| [6] |
Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015
|
| [7] |
Umuroglu Y, Fraser N J, Gambardella G, et al. Finn: A framework for fast, scalable binarized neural network inference. Acm/sigda International Symposium on Field-Programmable Gate Arrays, 2016
|
| [8] |
Nurvitadhi E, Venkatesh G, Sim J, et al. Can FPGAs beat GPUs in accelerating next-generation deep neural networks. ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2017
|
| [9] |
Guo K, Zeng S, Yu J, et al. A survey of FPGA-based neural network accelerator. arXiv: 171208934, 2017
|
| [10] |
Parisi G I, Kemker R, Part J L, et al. Continual lifelong learning with neural networks: A review. arXiv: 180207569, 2018
|
| [11] |
Micikevicius P, Narang S, Alben J, et al. Mixed precision training. arXiv: 171003740, 2017
|
| [12] |
Das D, Mellempudi N, Mudigere D, et al. Mixed precision training of convolutional neural networks using integer operations. arXiv: 180200930, 2018
|
| [13] |
Banner R, Hubara I, Hoffer E, et al. Scalable methods for 8-bit training of neural networks. arXiv: 180511046, 2018
|
| [14] |
De Sa C, Leszczynski M, Zhang J, et al. High-accuracy low-precision training. arXiv: 180303383, 2018
|
| [15] |
Wu S, Li G, Chen F, et al. Training and inference with integers in deep neural networks. arXiv: 180204680, 2018
|
| [16] |
Wen W, Xu C, Yan F, et al. Terngrad: Ternary gradients to reduce communication in distributed deep learning. Advances in Neural Information Processing Systems, 2017
|
| [17] |
Zhu H, Akrout M, Zheng B, et al. Benchmarking and analyzing deep neural network training. IEEE International Symposium on Workload Characterization (IISWC), 2018
|
| [18] |
Redmon J. Darknet: Open source neural networks in C. http://pjreddie.com/darknet/
|
| [19] |
Pell O, Mencer O, Tsoi K H, et al. Maximum performance computing with dataflow engines. High-performance computing using FPGAs, 2013
|
| [20] |
Luo C, Sit M K, Fan H, et al. Towards efficient deep neural network training by FPGA-based batch-level parallelism. 2019 IEEE 27th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), 2019, 45
|
| [21] |
Kingma D P, Ba J. Adam: A method for stochastic optimization. arXiv: 14126980, 2014
|
| [22] |
Qiu J, Wang J, Yao S, et al. Going deeper with embedded FPGA platform for convolutional neural network. Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2016
|
| [23] |
Suda N, Chandra V, Dasika G, et al. Throughput-optimized opencl-based FPGA accelerator for large-scale convolutional neural networks. Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2016
|
| [24] |
Motamedi M, Gysel P, Akella V, et al. Design space exploration of FPGA-based deep convolutional neural networks. ASP-DAC, 2016
|
| [25] |
Zhang C, Sun G, Fang Z, et al. Caffeine: Towards uniformed representation and acceleration for deep convolutional neural networks. IEEE Trans Comput-Aid Des Integr Circuits Syst, 2019, 38, 2072 doi: 10.1109/TCAD.2017.2785257
|
| [26] |
Ma Y, Cao Y, Vrudhula S, et al. An automatic rtl compiler for high-throughput FPGA implementation of diverse deep convolutional neural networks. 2017 27th International Conference on Field Programmable Logic and Applications (FPL), 2017, 1
|
| [27] |
Venkataramanaiah S K, Ma Y, Yin S, et al. Automatic compiler based FPGA accelerator for cnn training. 2019 29th International Conference on Field Programmable Logic and Applications (FPL), 2019, 166
|
| [28] |
Xiao Q, Liang Y, Lu L, et al. Exploring heterogeneous algorithms for accelerating deep convolutional neural networks on FPGAs. Proceedings of the 54th Annual Design Automation Conference, 2017
|
| [29] |
Zhao W, Fu H, Luk W, et al. F-CNN: An FPGA-based framework for training convolutional neural networks. IEEE 27th International Conference on Application-specific Systems, Architectures and Processors (ASAP), 2016
|
| [30] |
Geng T, Wang T, Li A, et al. A scalable framework for acceleration of cnn training on deeply-pipelined FPGA clusters with weight and workload balancing. arXiv: 190101007, 2019
|
| [31] |
Geng T, Wang T, Sanaullah A, et al. Fpdeep: Acceleration and load balancing of CNN training on FPGA clusters. IEEE 26th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), 2018
|
| [32] |
Li Y, Pedram A, Caterpillar: Coarse grain reconfigurable architecture for accelerating the training of deep neural networks. IEEE 28th International Conference on Application-Specific Systems, Architectures and Processors (ASAP), 2017
|
| [33] |
Dicecco R, Sun L, Chow P. FPGA-based training of convolutional neural networks with a reduced precision floating-point library. International Conference on Field Programmable Technology, 2018
|
| [34] |
Nakahara H, Sada Y, Shimoda M, et al. FPGA-based training accelerator utilizing sparseness of convolutional neural network. 2019 29th International Conference on Field Programmable Logic and Applications (FPL), 2019, 180
|
| [35] |
Fox S, Faraone J, Boland D, et al. Training deep neural networks in low-precision with high accuracy using FPGAs. International Conference on Field-Programmable Technology (FPT), 2019
|
| [36] |
Moss D J, Krishnan S, Nurvitadhi E, et al. A customizable matrix multiplication framework for the Intel HARPv2 Xeon+ FPGA platform: A deep learning case study. ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2018, 107
|
| [37] |
He K, Zhang X, Ren S, et al. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. Proceedings of the IEEE International Conference on Computer Vision, 2015, 1026
|
| [38] |
Zhou S, Wu Y, Ni Z, et al. Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients. arXiv preprint arXiv: 160606160, 2016
|
| [39] |
Matsumoto M, Nishimura T. Mersenne twister: a 623-dimensionally equidistributed uniform pseudo-random number generator. ACM Trans Model Comput Simul, 1998, 8(1), 3 doi: 10.1145/272991.272995
|
| [40] |
Performance guide of using nchw image data format. [Online]. Available: https://www.tensorflow.org/guide/performance/overview
|
| [41] |
Ma Y, Cao Y, Vrudhula S, et al. Optimizing loop operation and dataflow in FPGA acceleration of deep convolutional neural networks. Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2017
|
| [42] |
Steinkraus D, Buck I, Simard P. Using GPUs for machine learning algorithms. Eighth International Conference on Document Analysis and Recognition (ICDAR), 2005
|
| [43] |
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv: 14091556, 2014
|
| [44] |
Wei X, Yu C H, Zhang P, et al. Automated systolic array architecture synthesis for high throughput cnn inference on FPGAs. Proceedings of the 54th Annual Design Automation Conference, 2017,
|
| [45] |
Krishnan S, Ratusziak P, Johnson C, et al. Accelerator templates and runtime support for variable precision CNN. CISC Workshop, 2017
|
| [46] |
Abadi M, Barham P, Chen J, et al. TensorFlow: a system for large-scale machine learning. OSDI, 2016, 265
|
| [47] |
Chetlur S, Woolley C, Vandermersch P, et al. cuDNN: Efficient primitives for deep learning. arXiv: 14100759, 2014
|









Article views: 6623 Times PDF downloads: 133 Times Cited by: 0 Times
Received: 07 November 2019 Revised: 19 December 2019 Online: Accepted Manuscript: 04 January 2020Uncorrected proof: 06 January 2020Published: 11 February 2020
| Citation: |
Cheng Luo, Man-Kit Sit, Hongxiang Fan, Shuanglong Liu, Wayne Luk, Ce Guo. Towards efficient deep neural network training by FPGA-based batch-level parallelism[J]. Journal of Semiconductors, 2020, 41(2): 022403. doi: 10.1088/1674-4926/41/2/022403
****
C Luo, M K Sit, H X Fan, S L Liu, W Luk, C Guo, Towards efficient deep neural network training by FPGA-based batch-level parallelism[J]. J. Semicond., 2020, 41(2): 022403. doi: 10.1088/1674-4926/41/2/022403.

|
| [1] |
LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition. Proc IEEE, 1998
|
| [2] |
Russakovsky O, Deng J, Su H, et al. Imagenet large scale visual recognition challenge. IJCV, 2015
|
| [3] |
Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in Neural Information Processing Systems, 2015, 91
|
| [4] |
He K, Gkioxari G, Dollár P, et al. Mask r-cnn. Proceedings of the IEEE International Conference on Computer Vision, 2017, 2961
|
| [5] |
Jia Y, Learning semantic image representations at a large scale. PhD Thesis, UC Berkeley, 2014
|
| [6] |
Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015
|
| [7] |
Umuroglu Y, Fraser N J, Gambardella G, et al. Finn: A framework for fast, scalable binarized neural network inference. Acm/sigda International Symposium on Field-Programmable Gate Arrays, 2016
|
| [8] |
Nurvitadhi E, Venkatesh G, Sim J, et al. Can FPGAs beat GPUs in accelerating next-generation deep neural networks. ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2017
|
| [9] |
Guo K, Zeng S, Yu J, et al. A survey of FPGA-based neural network accelerator. arXiv: 171208934, 2017
|
| [10] |
Parisi G I, Kemker R, Part J L, et al. Continual lifelong learning with neural networks: A review. arXiv: 180207569, 2018
|
| [11] |
Micikevicius P, Narang S, Alben J, et al. Mixed precision training. arXiv: 171003740, 2017
|
| [12] |
Das D, Mellempudi N, Mudigere D, et al. Mixed precision training of convolutional neural networks using integer operations. arXiv: 180200930, 2018
|
| [13] |
Banner R, Hubara I, Hoffer E, et al. Scalable methods for 8-bit training of neural networks. arXiv: 180511046, 2018
|
| [14] |
De Sa C, Leszczynski M, Zhang J, et al. High-accuracy low-precision training. arXiv: 180303383, 2018
|
| [15] |
Wu S, Li G, Chen F, et al. Training and inference with integers in deep neural networks. arXiv: 180204680, 2018
|
| [16] |
Wen W, Xu C, Yan F, et al. Terngrad: Ternary gradients to reduce communication in distributed deep learning. Advances in Neural Information Processing Systems, 2017
|
| [17] |
Zhu H, Akrout M, Zheng B, et al. Benchmarking and analyzing deep neural network training. IEEE International Symposium on Workload Characterization (IISWC), 2018
|
| [18] |
Redmon J. Darknet: Open source neural networks in C. http://pjreddie.com/darknet/
|
| [19] |
Pell O, Mencer O, Tsoi K H, et al. Maximum performance computing with dataflow engines. High-performance computing using FPGAs, 2013
|
| [20] |
Luo C, Sit M K, Fan H, et al. Towards efficient deep neural network training by FPGA-based batch-level parallelism. 2019 IEEE 27th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), 2019, 45
|
| [21] |
Kingma D P, Ba J. Adam: A method for stochastic optimization. arXiv: 14126980, 2014
|
| [22] |
Qiu J, Wang J, Yao S, et al. Going deeper with embedded FPGA platform for convolutional neural network. Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2016
|
| [23] |
Suda N, Chandra V, Dasika G, et al. Throughput-optimized opencl-based FPGA accelerator for large-scale convolutional neural networks. Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2016
|
| [24] |
Motamedi M, Gysel P, Akella V, et al. Design space exploration of FPGA-based deep convolutional neural networks. ASP-DAC, 2016
|
| [25] |
Zhang C, Sun G, Fang Z, et al. Caffeine: Towards uniformed representation and acceleration for deep convolutional neural networks. IEEE Trans Comput-Aid Des Integr Circuits Syst, 2019, 38, 2072 doi: 10.1109/TCAD.2017.2785257
|
| [26] |
Ma Y, Cao Y, Vrudhula S, et al. An automatic rtl compiler for high-throughput FPGA implementation of diverse deep convolutional neural networks. 2017 27th International Conference on Field Programmable Logic and Applications (FPL), 2017, 1
|
| [27] |
Venkataramanaiah S K, Ma Y, Yin S, et al. Automatic compiler based FPGA accelerator for cnn training. 2019 29th International Conference on Field Programmable Logic and Applications (FPL), 2019, 166
|
| [28] |
Xiao Q, Liang Y, Lu L, et al. Exploring heterogeneous algorithms for accelerating deep convolutional neural networks on FPGAs. Proceedings of the 54th Annual Design Automation Conference, 2017
|
| [29] |
Zhao W, Fu H, Luk W, et al. F-CNN: An FPGA-based framework for training convolutional neural networks. IEEE 27th International Conference on Application-specific Systems, Architectures and Processors (ASAP), 2016
|
| [30] |
Geng T, Wang T, Li A, et al. A scalable framework for acceleration of cnn training on deeply-pipelined FPGA clusters with weight and workload balancing. arXiv: 190101007, 2019
|
| [31] |
Geng T, Wang T, Sanaullah A, et al. Fpdeep: Acceleration and load balancing of CNN training on FPGA clusters. IEEE 26th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), 2018
|
| [32] |
Li Y, Pedram A, Caterpillar: Coarse grain reconfigurable architecture for accelerating the training of deep neural networks. IEEE 28th International Conference on Application-Specific Systems, Architectures and Processors (ASAP), 2017
|
| [33] |
Dicecco R, Sun L, Chow P. FPGA-based training of convolutional neural networks with a reduced precision floating-point library. International Conference on Field Programmable Technology, 2018
|
| [34] |
Nakahara H, Sada Y, Shimoda M, et al. FPGA-based training accelerator utilizing sparseness of convolutional neural network. 2019 29th International Conference on Field Programmable Logic and Applications (FPL), 2019, 180
|
| [35] |
Fox S, Faraone J, Boland D, et al. Training deep neural networks in low-precision with high accuracy using FPGAs. International Conference on Field-Programmable Technology (FPT), 2019
|
| [36] |
Moss D J, Krishnan S, Nurvitadhi E, et al. A customizable matrix multiplication framework for the Intel HARPv2 Xeon+ FPGA platform: A deep learning case study. ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2018, 107
|
| [37] |
He K, Zhang X, Ren S, et al. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. Proceedings of the IEEE International Conference on Computer Vision, 2015, 1026
|
| [38] |
Zhou S, Wu Y, Ni Z, et al. Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients. arXiv preprint arXiv: 160606160, 2016
|
| [39] |
Matsumoto M, Nishimura T. Mersenne twister: a 623-dimensionally equidistributed uniform pseudo-random number generator. ACM Trans Model Comput Simul, 1998, 8(1), 3 doi: 10.1145/272991.272995
|
| [40] |
Performance guide of using nchw image data format. [Online]. Available: https://www.tensorflow.org/guide/performance/overview
|
| [41] |
Ma Y, Cao Y, Vrudhula S, et al. Optimizing loop operation and dataflow in FPGA acceleration of deep convolutional neural networks. Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2017
|
| [42] |
Steinkraus D, Buck I, Simard P. Using GPUs for machine learning algorithms. Eighth International Conference on Document Analysis and Recognition (ICDAR), 2005
|
| [43] |
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv: 14091556, 2014
|
| [44] |
Wei X, Yu C H, Zhang P, et al. Automated systolic array architecture synthesis for high throughput cnn inference on FPGAs. Proceedings of the 54th Annual Design Automation Conference, 2017,
|
| [45] |
Krishnan S, Ratusziak P, Johnson C, et al. Accelerator templates and runtime support for variable precision CNN. CISC Workshop, 2017
|
| [46] |
Abadi M, Barham P, Chen J, et al. TensorFlow: a system for large-scale machine learning. OSDI, 2016, 265
|
| [47] |
Chetlur S, Woolley C, Vandermersch P, et al. cuDNN: Efficient primitives for deep learning. arXiv: 14100759, 2014
|

 WeChat ID
WeChat ID
Journal of Semiconductors © 2017 All Rights Reserved 京ICP备05085259号-2