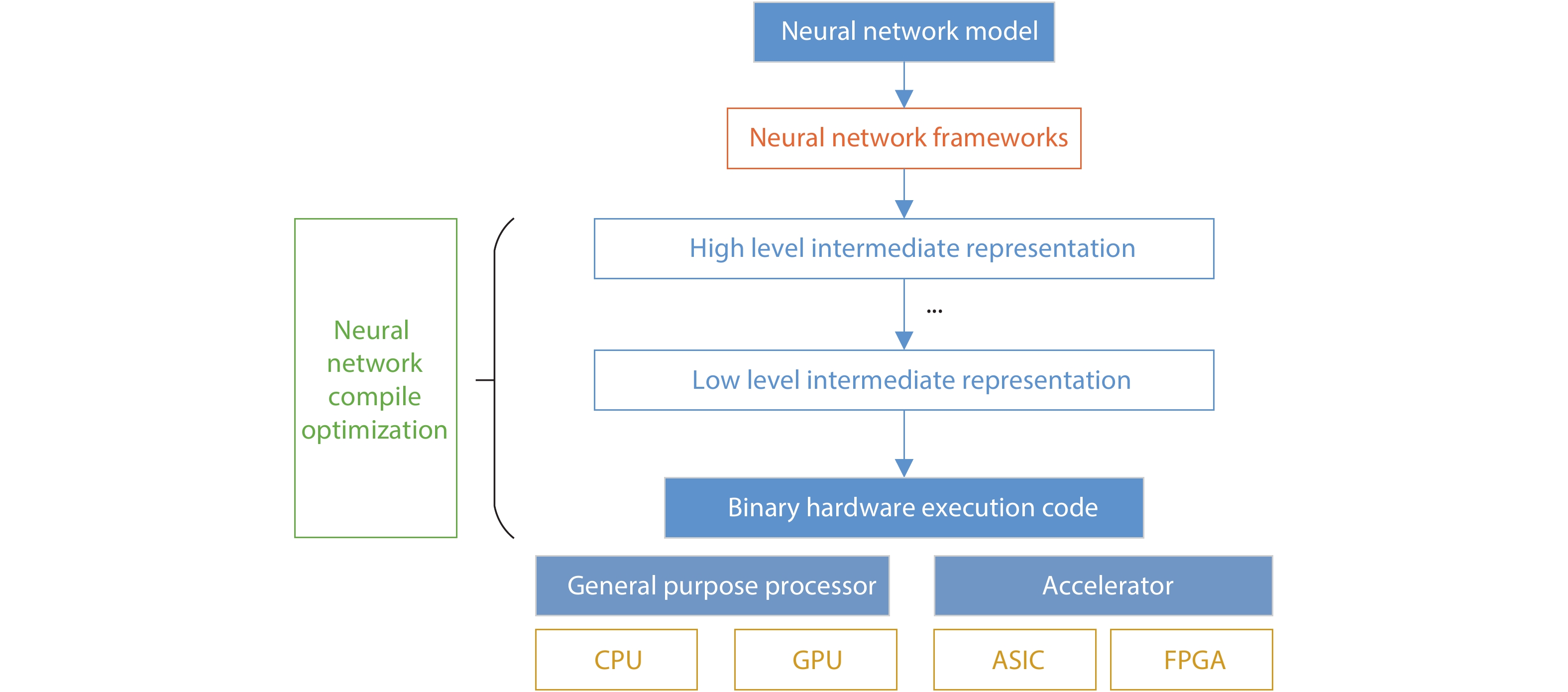
| [1] |
Huang W, Jing Z. Multi-focus image fusion using pulse coupled neural network. Pattern Recogn Lett, 2007, 28(9), 1123 doi: 10.1016/j.patrec.2007.01.013 |
| [2] |
Paik J K, Katsaggelos A K. Image restoration using a modified hopfield network. IEEE Trans Image Process, 1992, 1(1), 49 doi: 10.1109/83.128030 |
| [3] |
Li X, Zhao L, Wei L, et al. DeepSaliency: multi-task deep neural network model for salient object detection. IEEE Trans Image Process, 2016, 25, 3919 doi: 10.1109/TIP.2016.2579306 |
| [4] |
Zhu Y, Urtasun R, Salakhutdinov R, et al. segDeepM: exploiting segmentation and context in deep neural networks for object detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, 4703
|
| [5] |
Graves A, Mohamed A R, Hinton G. Speech recognition with deep recurrent neural networks. 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, 2013, 6645
|
| [6] |
Abdelhamid O, Mohamed A, Jiang H, et al. Convolutional neural networks for speech recognition. IEEE/ACM Trans Audio Speech Language Process, 2014, 22(10), 1533 doi: 10.1109/TASLP.2014.2339736 |
| [7] |
Collobert R, Weston J. A unified architecture for natural language processing. International Conference on Machine Learning, 2008
|
| [8] |
Sarikaya R, Hinton G E, Deoras A. Application of deep belief networks for natural language understanding. IEEE/ACM Trans Audio, Speech, Language Process, 2014, 22(4), 778 doi: 10.1109/TASLP.2014.2303296 |
| [9] |
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv: 1409.1556, 2014
|
| [10] |
McCulloch W S, Pitts W. A logical calculus of ideas immanent in nervous activity. Bull Math Biophys, 1943, 5(4), 115 doi: 10.1007/BF02478259 |
| [11] |
Rosenblatt F. The perceptron: a probabilistic model for information storage and organization in the brain. Psycholog Rev, 1958, 65(6), 386 doi: 10.1037/h0042519 |
| [12] |
Werbos P. Beyond regression: new tools for prediction and analysis in the behavioral sciences. Dissertation for the Doctoral Degree, Harvard University, 1974
|
| [13] |
Hinton G E, Osindero S, Teh Y. A fast learning algorithm for deep belief nets. Neur Comput, 2006, 18(7), 1527 doi: 10.1162/neco.2006.18.7.1527 |
| [14] |
Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolu-tional neural networks. Advances in Neural Information Processing Systems, 2012, 1097
|
| [15] |
He K, Zhang X, Ren S, et al. Deep residual learning for image recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, 770
|
| [16] |
Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, 1
|
| [17] |
Szegedy C, Ioffe S, Vanhoucke V, et al. Inception-v4, Inception-ResNet and the impact of residual connections on learning. National Conference on Artificial Intelligence, 2016, 4278
|
| [18] |
Yu F, Koltun V. Multi-scale context aggregation by dilated convolutions. arXiv: 1511.07122, 2015
|
| [19] |
Mamalet F, Garcia C. Simplifying convnets for fast learning. international conference on artificial neural networks. International Conference on Artificial Neural Networks, 2012, 58
|
| [20] |
Howard A G, Zhu M, Chen B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications. arXiv: 1704.04861, 2017
|
| [21] |
Cho K, Van Merrienboer B, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv: 1406.1078, 2014
|
| [22] |
|
| [23] |
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need. Advances in Neural Information Processing Systems, 2017, 5998
|
| [24] |
Devlin J, Chang M W, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv: 1810.04805, 2018
|
| [25] |
Parashar A, Rhu M, Mukkara A, et al. SCNN: An accelerator for compressed-sparse convolutional neural networks. 2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA), 2017
|
| [26] |
Han S, Mao H, Dally W J. Deep compression: compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv: 1510.00149, 2015
|
| [27] |
Lin D D, Talathi S S, Annapureddy V S. Fixed point quantization of deep convolutional networks. International Conference on Machine Learning, 2016, 2849
|
| [28] |
Xue J, Li J, Yu D, et al. Singular value decomposition based low-footprint speaker adaptation and personalization for deep neural network. IEEE International Conference on Acoustics, 2014
|
| [29] |
Park E, Ahn J, Yoo S. Weighted-entropy-based quantization for deep neural networks. IEEE Conference on Computer Vision & Pattern Recognition, 2017
|
| [30] |
Song L, Wang Y, Han Y, et al. C-Brain: A deep learning accelerator that tames the diversity of CNNs through adaptive data-level parallelization. Design Automation Conference, 2016
|
| [31] |
Kuo R J, An Y L, Wang H S, et al. Integration of self-organizing feature maps neural network and genetic K-means algorithm for market segmentation. Expert Syst Appl, 2006, 30(2), 313 doi: 10.1016/j.eswa.2005.07.036 |
| [32] |
Roska T, Bártfai G, Szolgay P, et al. A digital multiprocessor hardware accelerator board for cellular neural networks: CNN-HAC. Int J Circuit Theory Appl, 1992, 20(5), 589 doi: 10.1002/cta.4490200512 |
| [33] |
Gokhale V, Zaidy A, Chang A X M, et al. Snowflake: a model agnostic accelerator for deep convolutional neural networks. arXiv preprint arXiv: 1708.02579, 2017
|
| [34] |
Page A, Jafari A, Shea C, et al. SPARCNet: a hardware accelerator for efficient deployment of sparse convolutional networks. ACM J Emerg Technolog Comput Syst, 2017, 13(3), 1
|
| [35] |
Chen T, Chen Y, Duranton M, et al. BenchNN: On the broad potential application scope of hardware neural network accelerators. 2012 IEEE International Symposium on Workload Characterization (IISWC), 2012, 36
|
| [36] |
Farabet C, Poulet C, Han J Y, et al. CNP: An FPGA-based processor for convolutional networks. International Conference on Field Programmable Logic and Applications, 2009
|
| [37] |
Zhang S, Du Z, Zhang L, et al. Cambricon-X: An accelerator for sparse neural networks. The 49th Annual IEEE/ACM International Symposium on Microarchitecture, 2016, 20
|
| [38] |
Yu Y, Zhi T, Zhou X, et al. BSHIFT: a low cost deep neural networks accelerator. Int J Paral Program, 2019, 47, 360 doi: 10.1007/s10766-018-00624-9 |
| [39] |
Shafiee A, Nag A, Muralimanohar N, et al. ISAAC: a convolutional neural network accelerator with in-situ analog arithmetic in crossbars. 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), 2016
|
| [40] |
Chen Y H, Krishna T, Emer J S, et al. Eyeriss: an energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE J Solid-State Circuits, 2017, 52(1), 127 doi: 10.1109/JSSC.2016.2616357 |
| [41] |
Jouppi N P, Young C, Patil N, et al. In-datacenter performance analysis of a tensor processing unit. 2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA), 2017, 1
|
| [42] |
Chen Y, Chen T, Xu Z, et al. DianNao family: energy-efficient hardware accelerators for machine learning. Commun ACM, 2016, 59(11), 105 doi: 10.1145/2996864 |
| [43] |
Chen T, Du Z, Sun N, et al. DianNao: a small-footprint high-throughput accelerator for ubiquitous machine-learning. Proceedings of the 19th International Conference on Architectural Support for Programming Languages and Operating Systems, 2014
|
| [44] |
Chen Y, Luo T, Liu S, et al. Dadiannao: A machine-learning supercomputer. Proceedings of the 47th Annual IEEE/ACM International Symposium on Microarchitecture, 2014, 609
|
| [45] |
Du Z, Fasthuber R, Chen T, et al. ShiDianNao:shifting vision processing closer to the sensor. ACM/IEEE International Symposium on Computer Architecture, 2015
|
| [46] |
Liu D, Chen T, Liu S, et al. Pudiannao: A polyvalent machine learning accelerator. ACM SIGARCH Comput Architect News, 2015, 43(1), 369 doi: 10.1145/2786763.2694358 |
| [47] |
Du Z, Palem K, Lingamneni A, et al. Leveraging the error resilience of machine-learning applications for designing highly energy efficient accelerators. 2014 19th Asia and South Pacific Design Automation Conference (ASP-DAC), 2014, 201
|
| [48] |
Estrin G. Organization of computer systems: the fixed plus variable structure computer. Western Joint IRE-AIEE-ACM Computer Conference, 1960, 33
|
| [49] |
Dehon A, Wawrzynek J. Reconfigurable computing: what, why, and implications for design automation. Proceedings 1999 Design Automation Conferenc, 1999
|
| [50] |
Majumdar A, Cadambi S, Becchi M, et al. A massively parallel, energy efficient programmable accelerator for learning and classification. ACM Trans Architect Code Optim, 2012, 9(1), 1
|
| [51] |
Ansari A, Gunnam K, Ogunfunmi T, et al. An efficient reconfigurable hardware accelerator for convolutional neural networks. 2017 51st Asilomar Conference on Signals, Systems, and Computers, 2017, 1337
|
| [52] |
Ando K, Ueyoshi K, Orimo K, et al. BRein memory: a single-chip binary/ternary reconfigurable in-memory deep neural network accelerator achieving 1.4 TOPS at 0.6 W. IEEE J Solid-State Circuits, 2017, 53(4), 983 doi: 10.1109/JSSC.2017.2778702 |
| [53] |
Lee J, Kim C, Kang S H, et al. UNPU: A 50.6TOPS/W unified deep neural network accelerator with 1b-to-16b fully-variable weight bit-precision. International Solid-State Circuits Conference, 2018, 218
|
| [54] |
You W, Wu C. A reconfigurable accelerator for sparse convolutional neural networks. Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2019, 119
|
| [55] |
Liu S, Du Z, Tao J, et al. Cambricon: An instruction set architecture for neural networks. ACM SIGARCH Comput Architect News, 2016, 44(3), 393 doi: 10.1145/3007787.3001179 |
| [56] |
Zhao Y, Du Z, Guo Q, et al. Cambricon-F: machine learning computers with fractal von neumann architecture. International Symposium on Computer Architecture, 2019, 788
|
| [57] |
Abadi M, Barham P, Chen J, et al. Tensorflow: A system for large-scale machine learning. 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), 2016, 265
|
| [58] |
Jia Y, Shelhamer E, Donahue J, et al. Caffe: Convolutional architecture for fast feature embedding. Proceedings of the 22nd ACM International Conference on Multimedia, 2014, 675
|
| [59] |
Chen T, Li M, Li Y, et al. MXNet: a flexible and efficient machine learning library for heterogeneous distributed systems. arXiv: 1512.01274, 2015
|
| [60] |
Truong L, Barik R, Totoni E, et al. Latte: a language, compiler, and runtime for elegant and efficient deep neural networks. ACM SIGPLAN Notices, 2016, 51, 209
|
| [61] |
Lan H, Du Z. DLIR: an intermediate representation for deep learning processors. IFIP International Conference on Network and Parallel Computing, 2018, 169
|
| [62] |
Du W, Wu L, Chen X, et al. ZhuQue: a neural network programming model based on labeled data layout. International Symposium on Advanced Parallel Processing Technologies, 2019, 27
|
| [63] |
Fischer K, Saba E. Automatic full compilation of Julia programs and ML models to cloud TPUs. arXiv: 1810.09868, 2018
|
| [64] |
Chen T, Moreau T, Jiang Z, et al. TVM: an automated end-to-end optimizing compiler for deep learning. 13th USENIX Symposium on Operating Systems Design and Implementation, 2018, 578
|
| [65] |
Mendis C, Bosboom J, Wu K, et al. Helium: lifting high-performance stencil kernels from stripped ×86 binaries to halide DSL code. Program Language Des Implem, 2015, 50(6), 391
|
| [66] |
Song J, Zhuang Y, Chen X, et al. Compiling optimization for neural network accelerators. International Symposium on Advanced Parallel Processing Technologies, 2019, 15
|



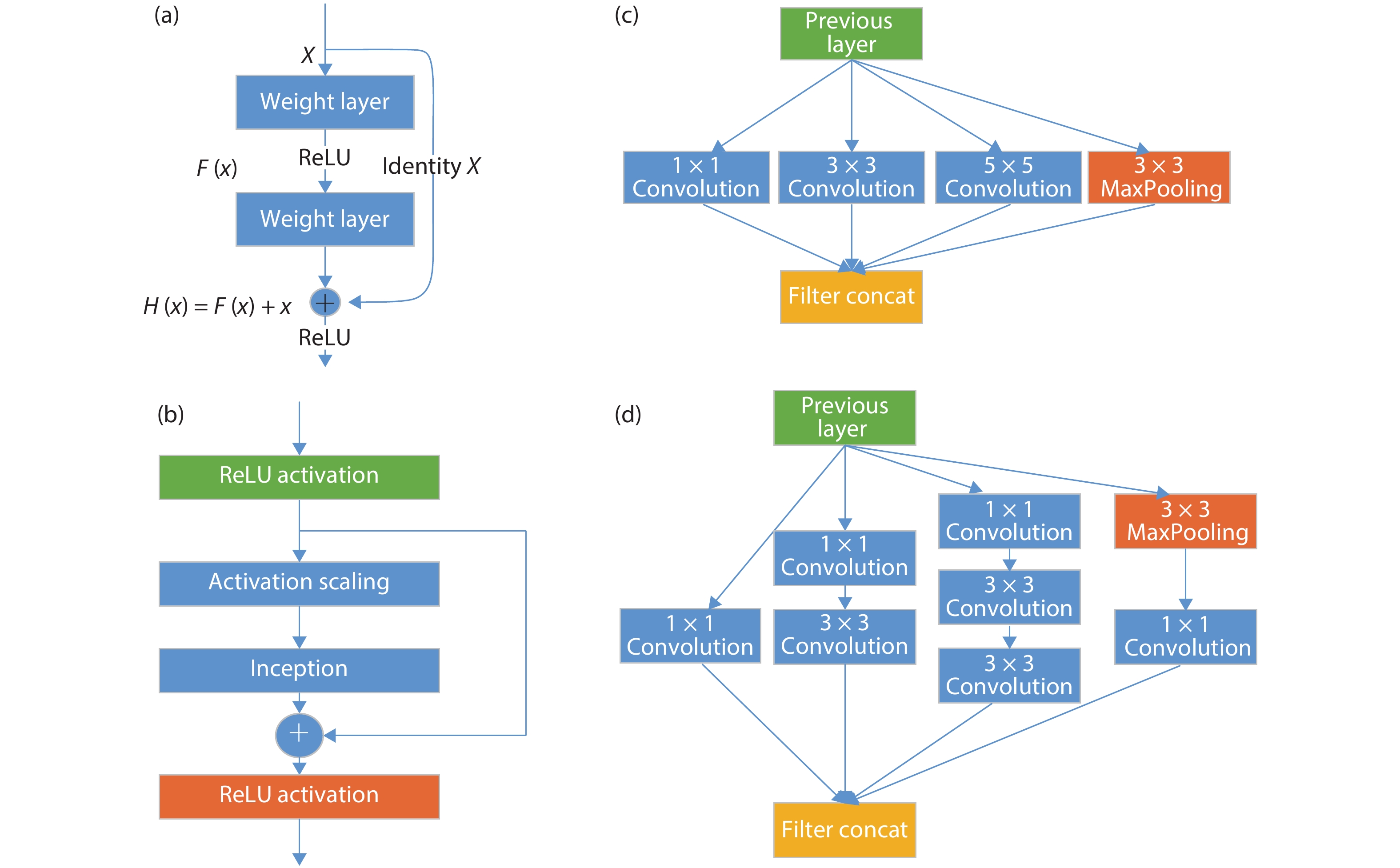
 DownLoad:
DownLoad: