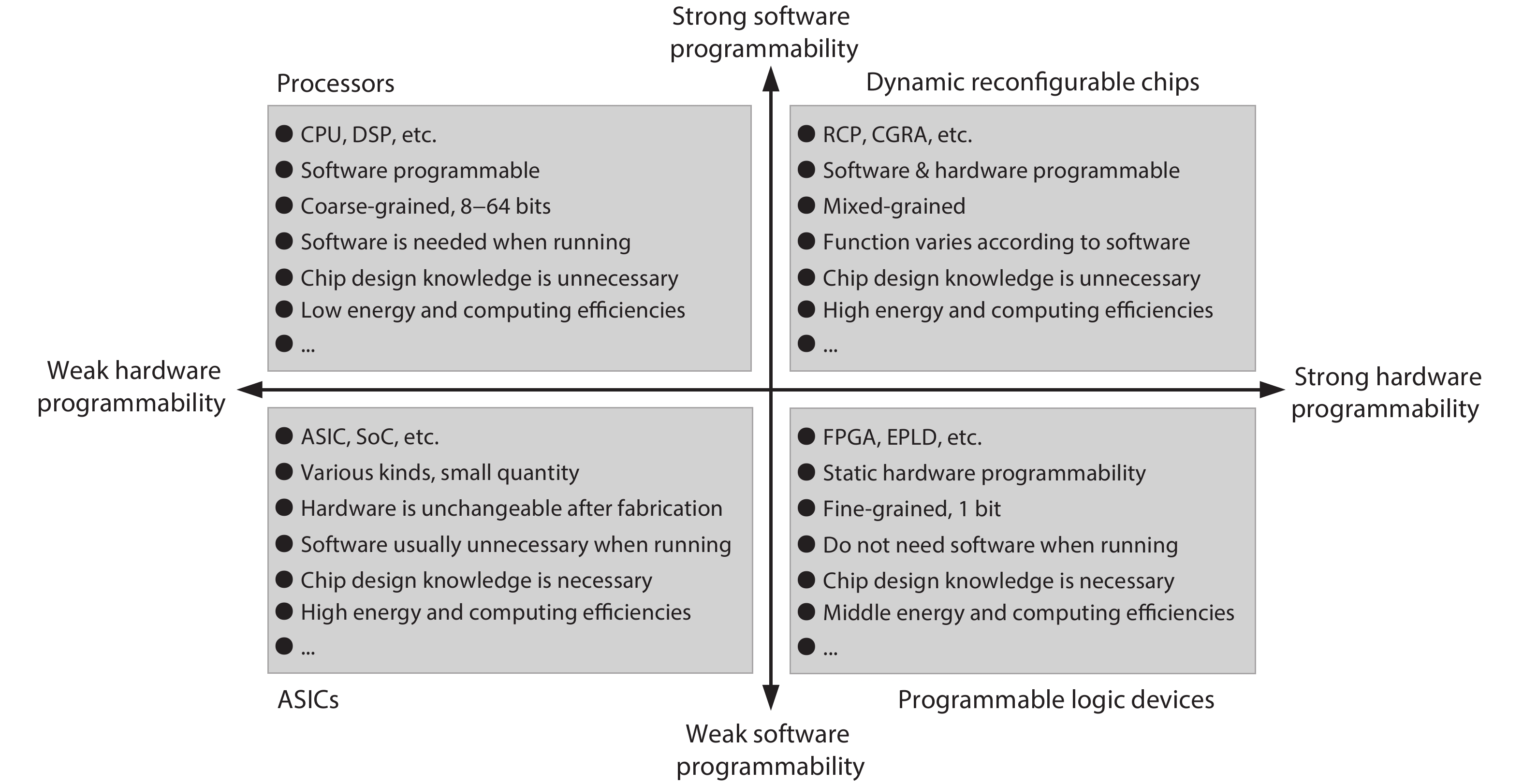
Today, integrated circuit technology is approaching the physical limit. From performance and energy consumption perspective, reconfigurable computing is regarded as the most promising technology for future computing systems with excellent feature in computing and energy efficiency. From the perspective of computing performance, compared with single thread performance stagnation of general purpose processors (GPPS), reconfigurable computing may customize hardware according to application requirements, so as to achieve higher performance and lower energy consumption. From the perspective of economics, a microchip based on reconfigurable computing technology has post-silicon reconfigurability, which can be applied in different fields, so as to better share the cost of non-recurring engineering (NRE). High computing and energy efficiency together with unique reconfigurability make reconfigurable computing one of the most important technologies of artificial intelligent microchips.
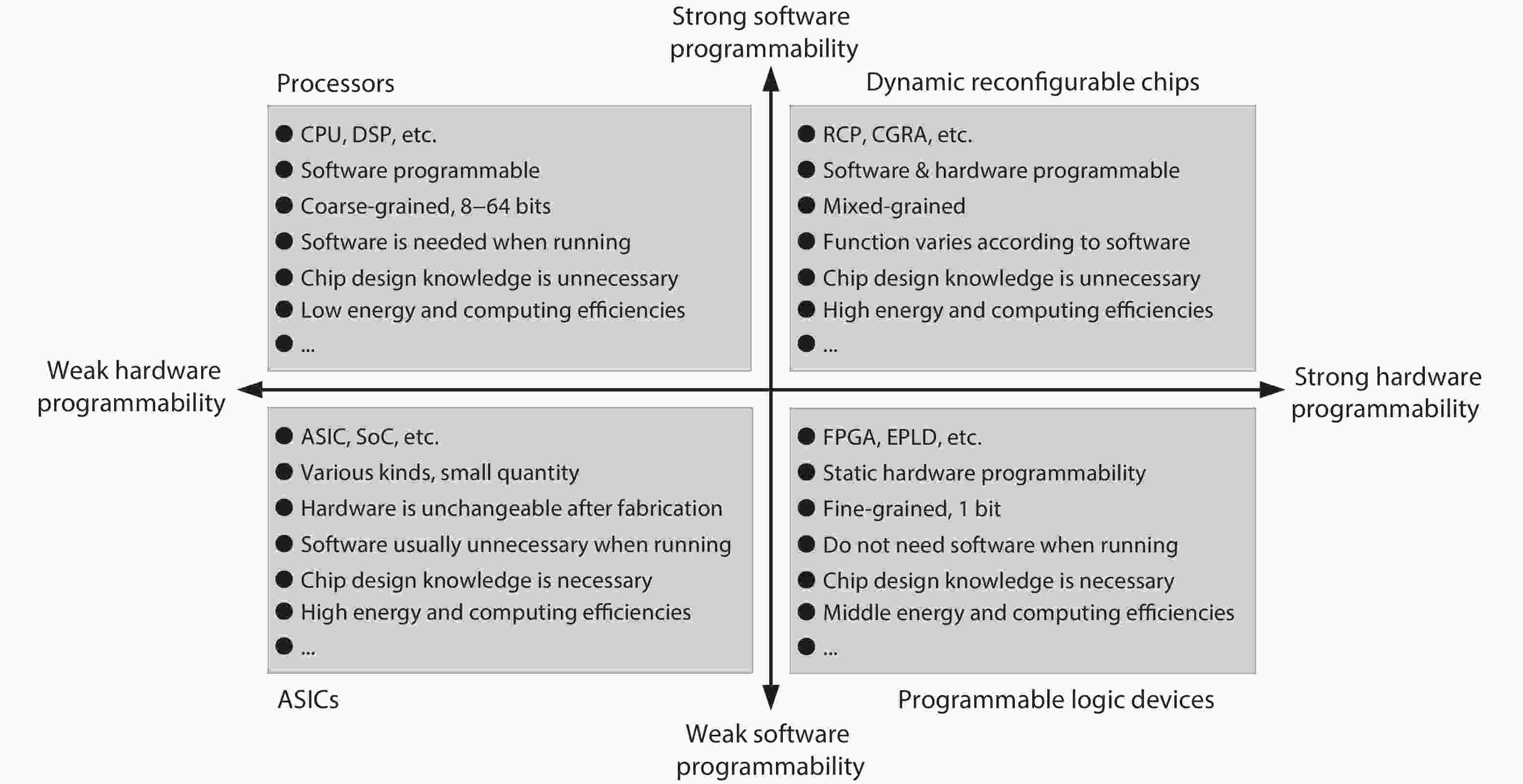
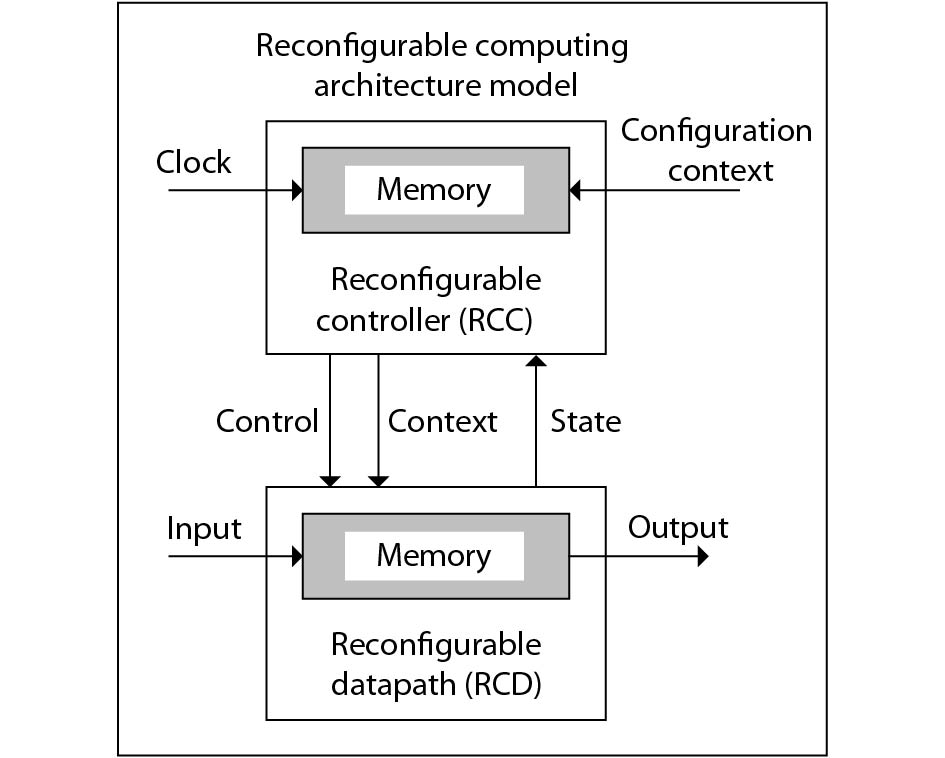
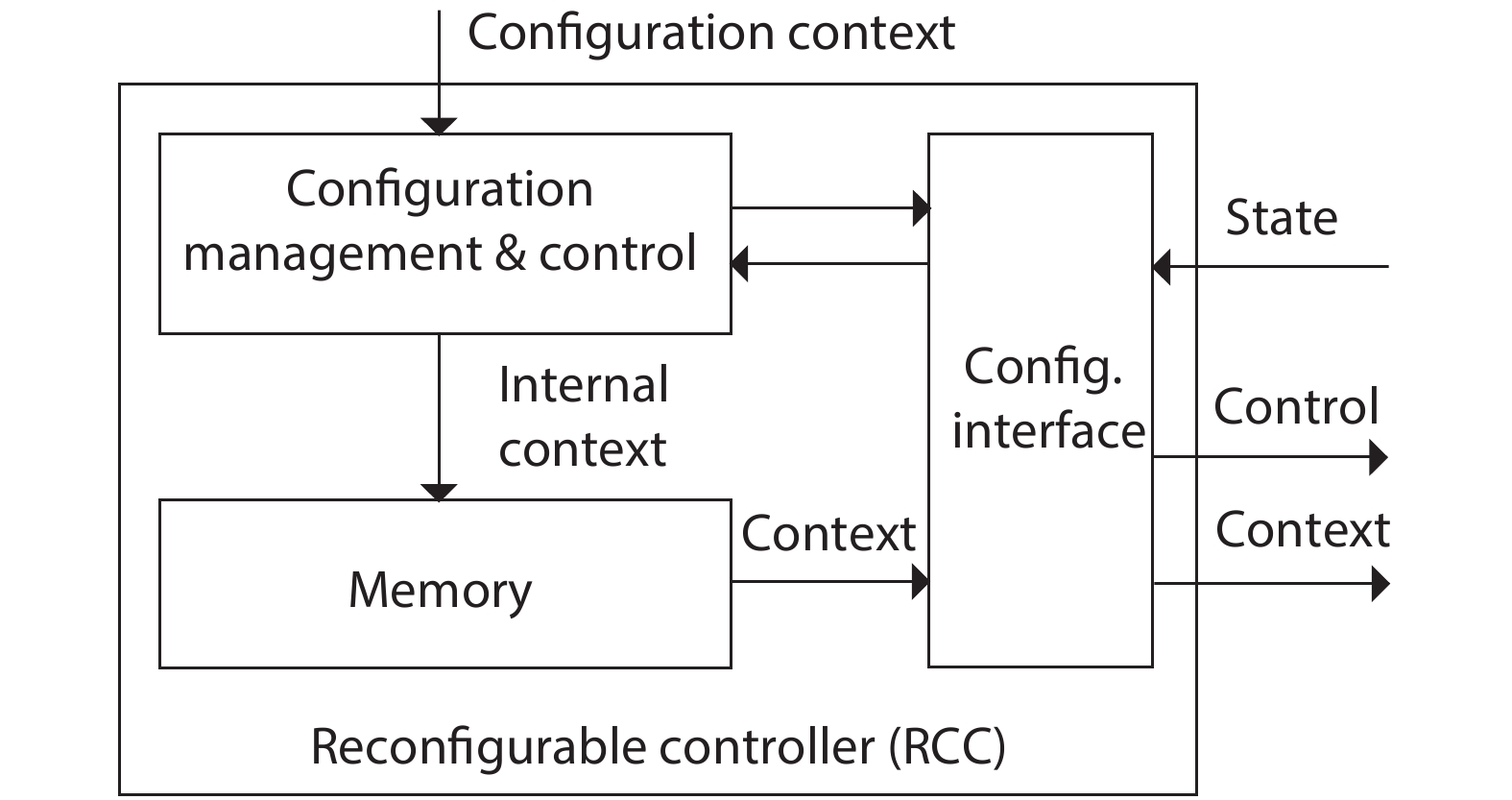
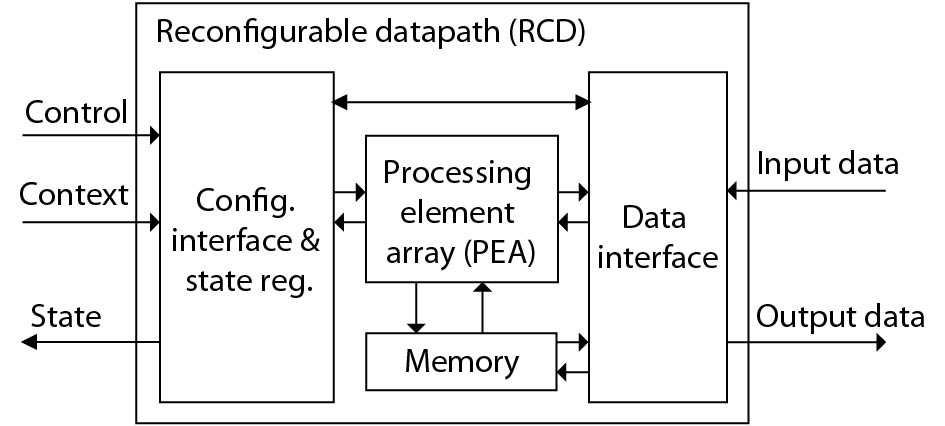
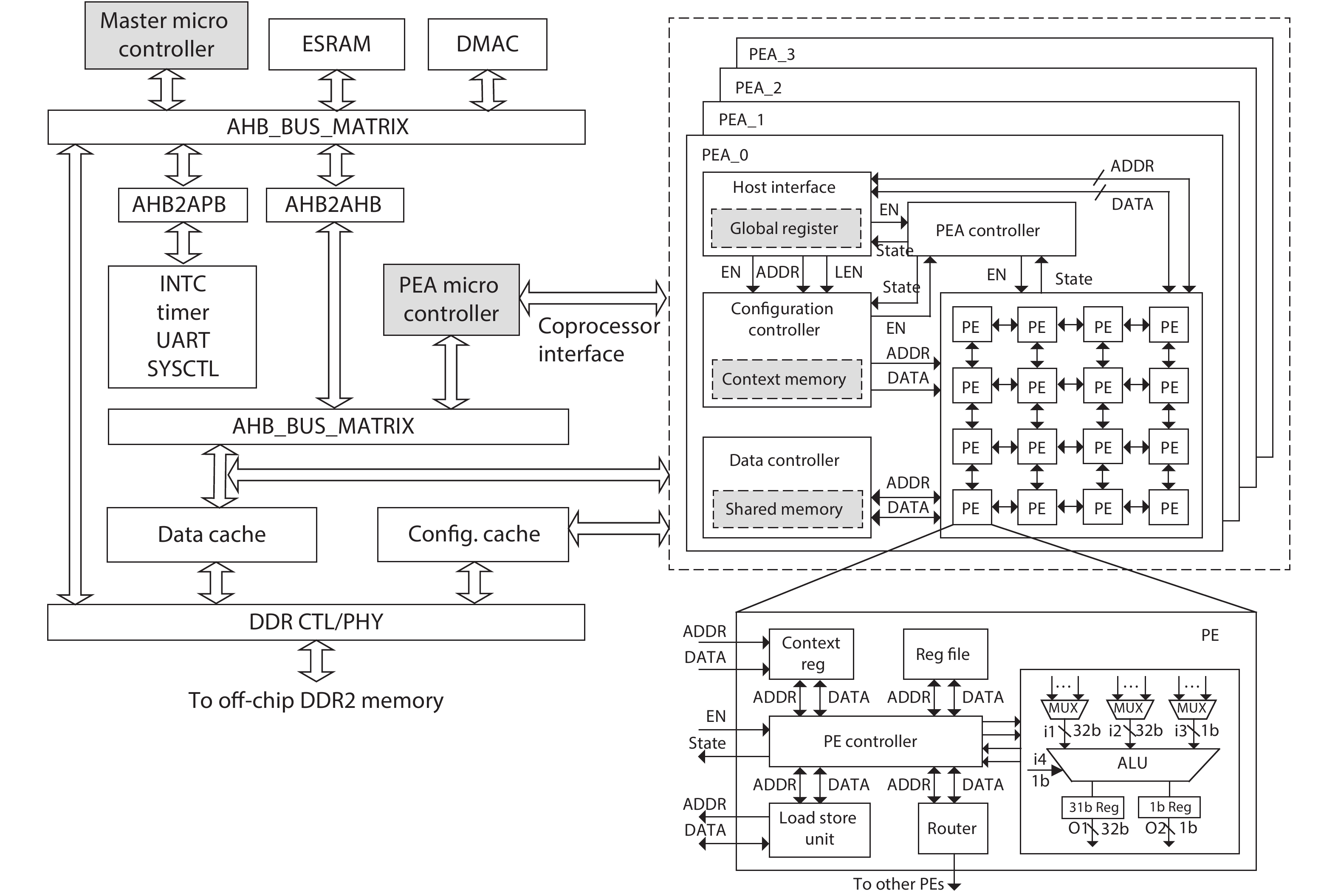
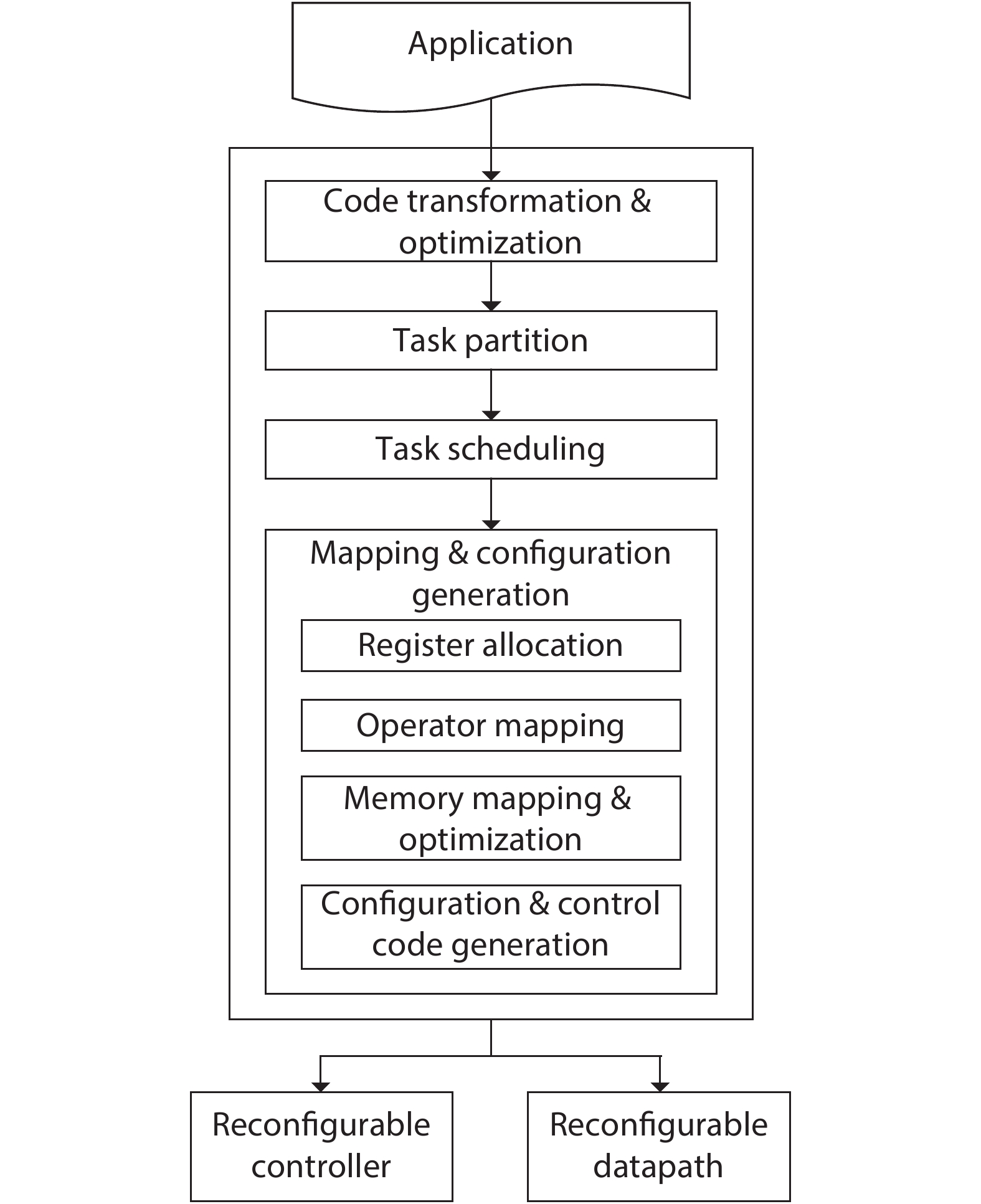
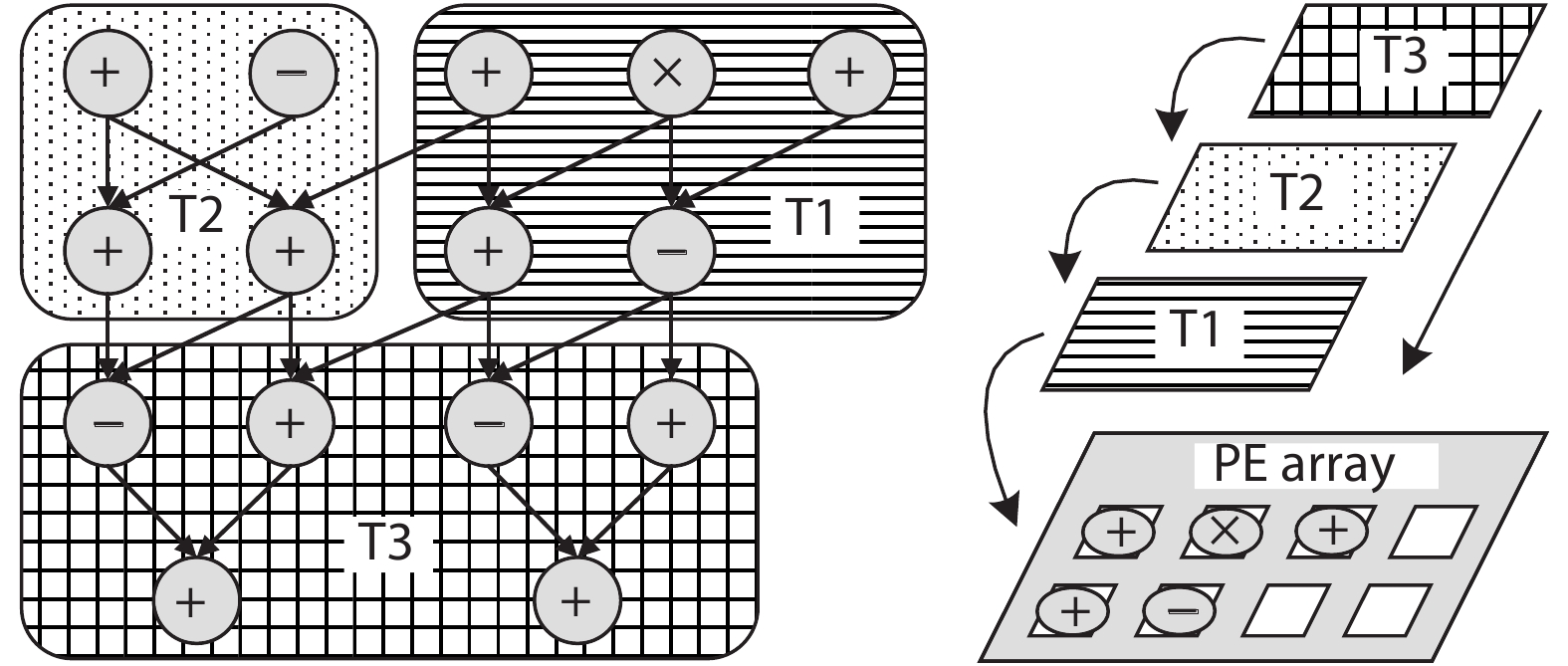
As a computing paradigm that combines temporal and spatial computations, dynamic reconfigurable computing provides superiorities of flexibility, energy efficiency and area efficiency, attracting interest from both academia and industry. However, dynamic reconfigurable computing is not yet mature because of several unsolved problems. This work introduces the concept, architecture, and compilation techniques of dynamic reconfigurable computing. It also discusses the existing major challenges and points out its potential applications.



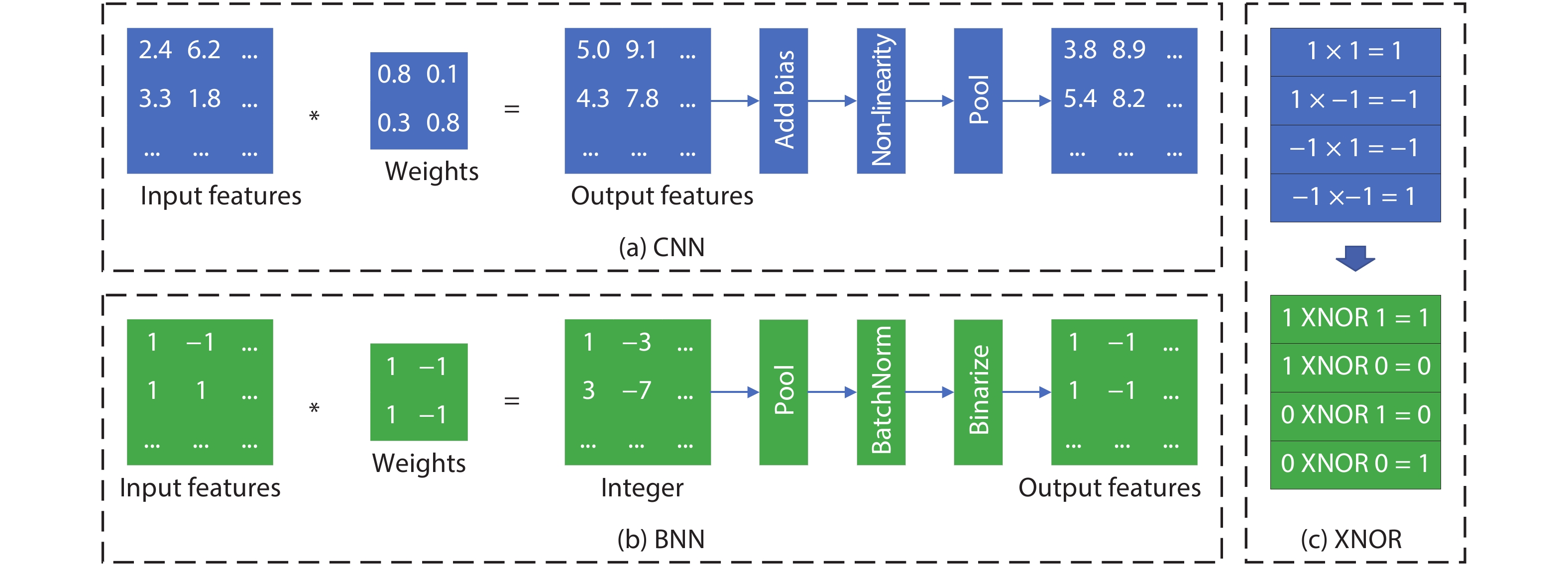
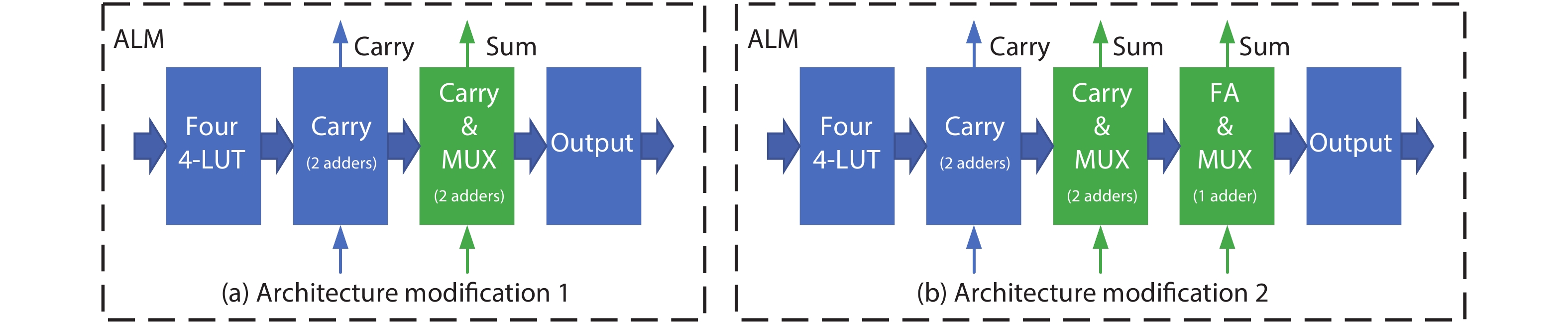
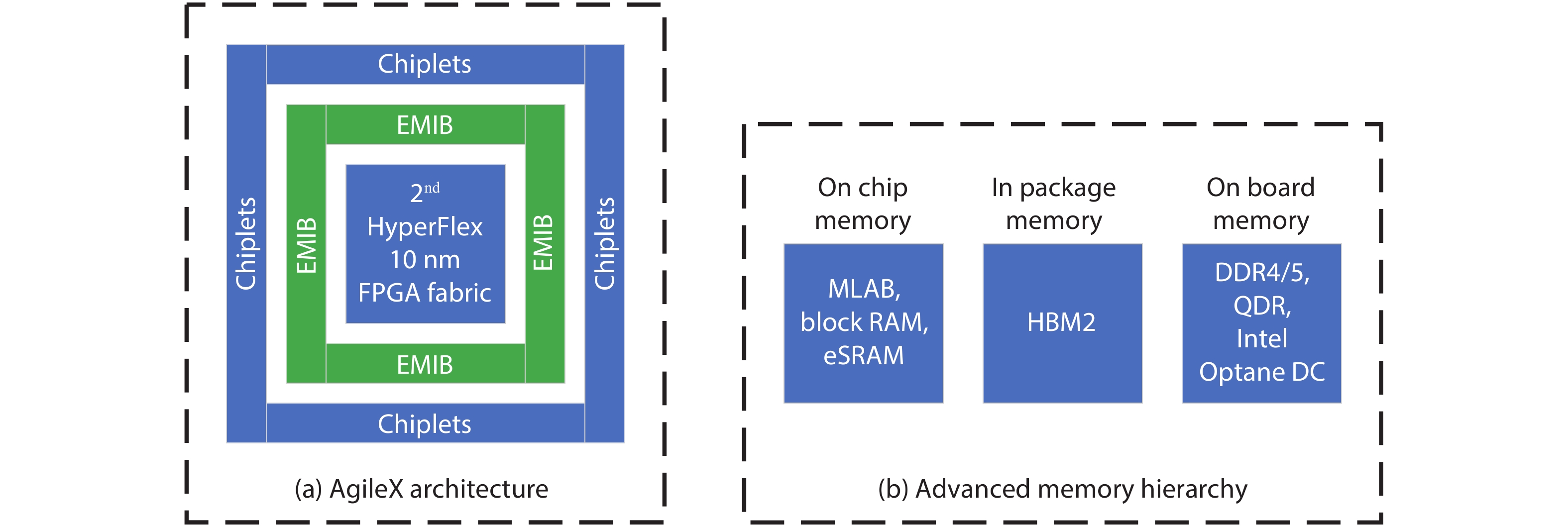
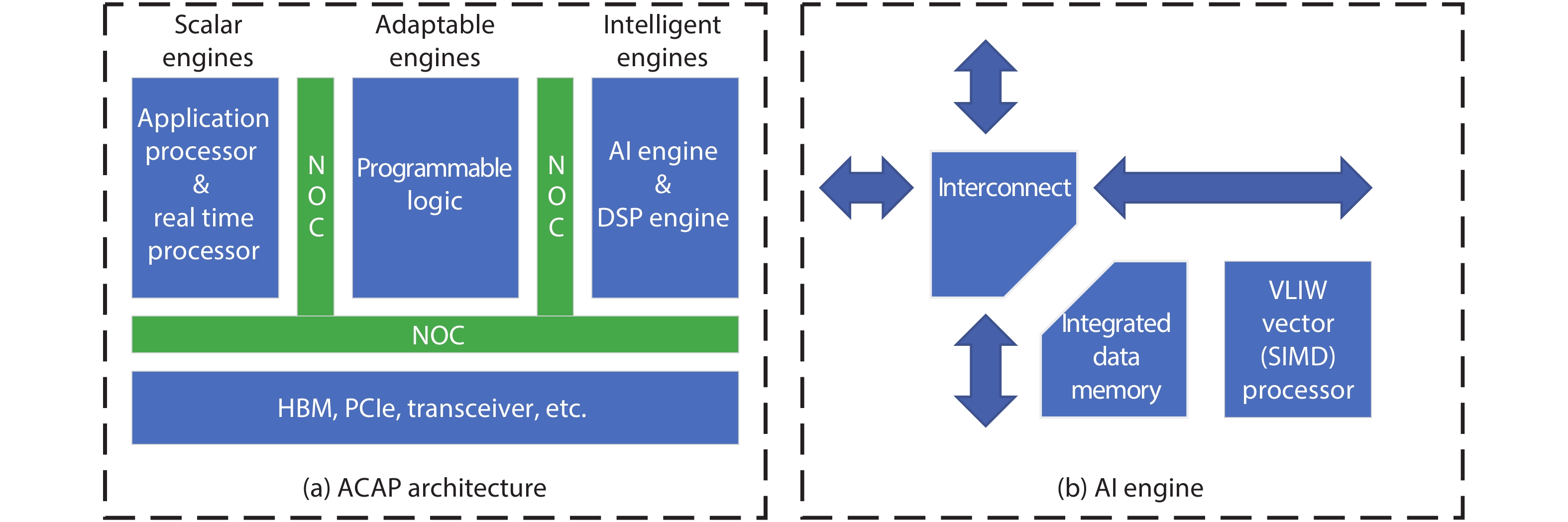
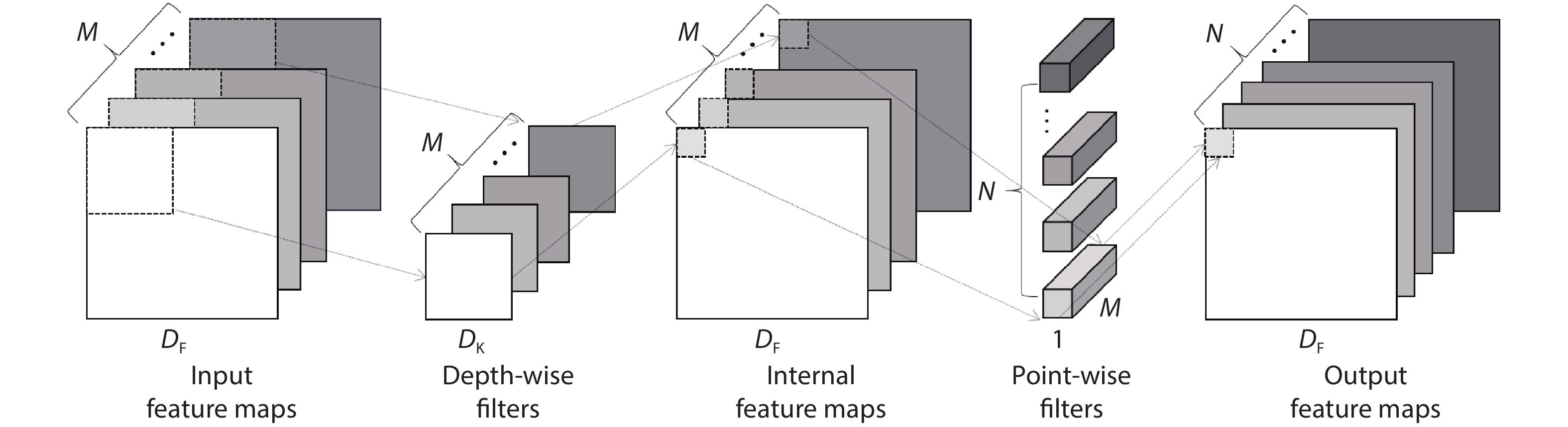
FPGA is an appealing platform to accelerate DNN. We survey a range of FPGA chip designs for AI. For DSP module, one type of design is to support low-precision operation, such as 9-bit or 4-bit multiplication. The other type of design of DSP is to support floating point multiply-accumulates (MACs), which guarantee high-accuracy of DNN. For ALM (adaptive logic module) module, one type of design is to support low-precision MACs, three modifications of ALM includes extra carry chain, or 4-bit adder, or shadow multipliers which increase the density of on-chip MAC operation. The other enhancement of ALM or CLB (configurable logic block) is to support BNN (binarized neural network) which is ultra-reduced precision version of DNN. For memory modules which can store weights and activations of DNN, three types of memory are proposed which are embedded memory, in-package HBM (high bandwidth memory) and off-chip memory interfaces, such as DDR4/5. Other designs are new architecture and specialized AI engine. Xilinx ACAP in 7 nm is the first industry adaptive compute acceleration platform. Its AI engine can provide up to 8X silicon compute density. Intel AgileX in 10 nm works coherently with Intel own CPU, which increase computation performance, reduced overhead and latency.


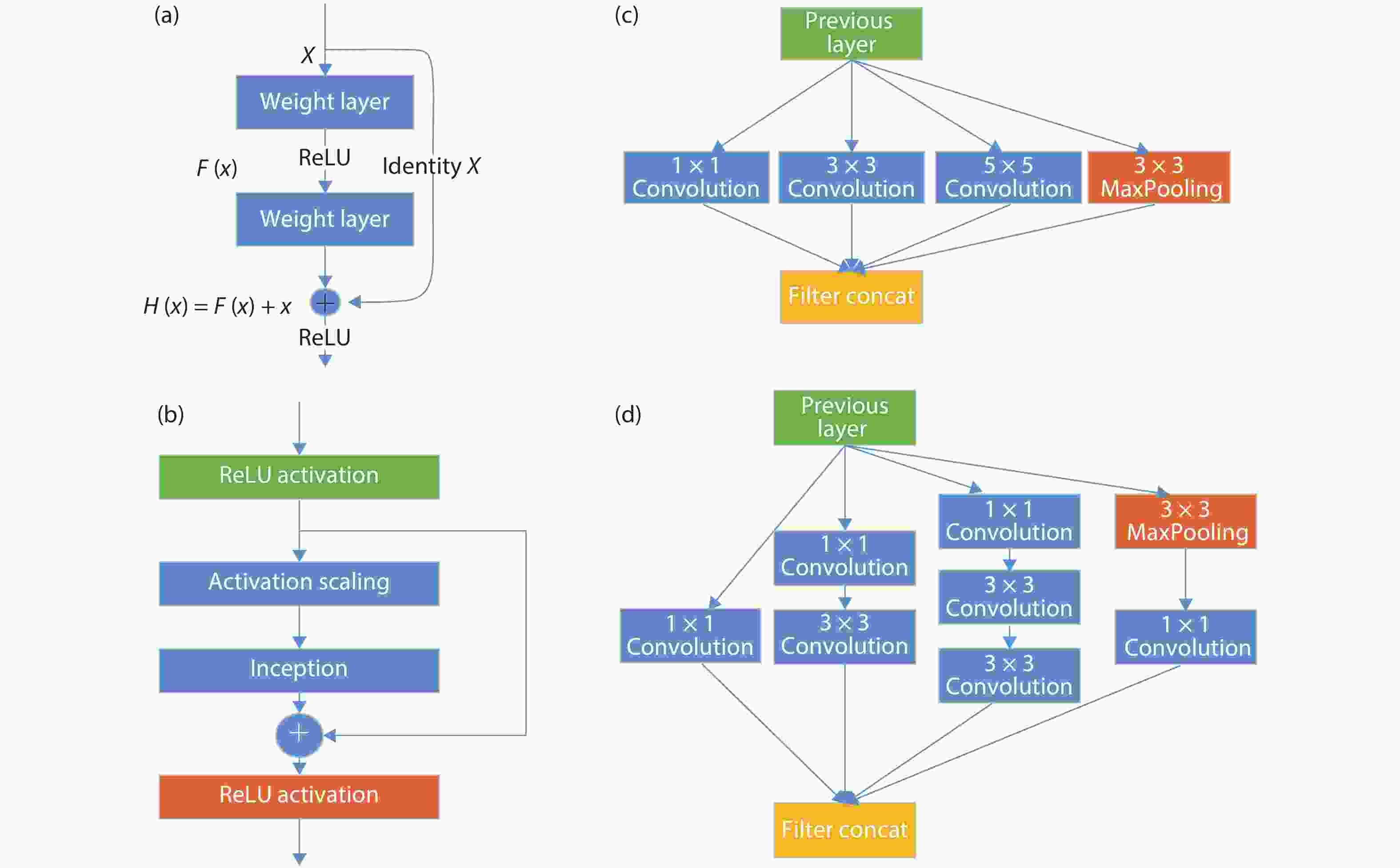
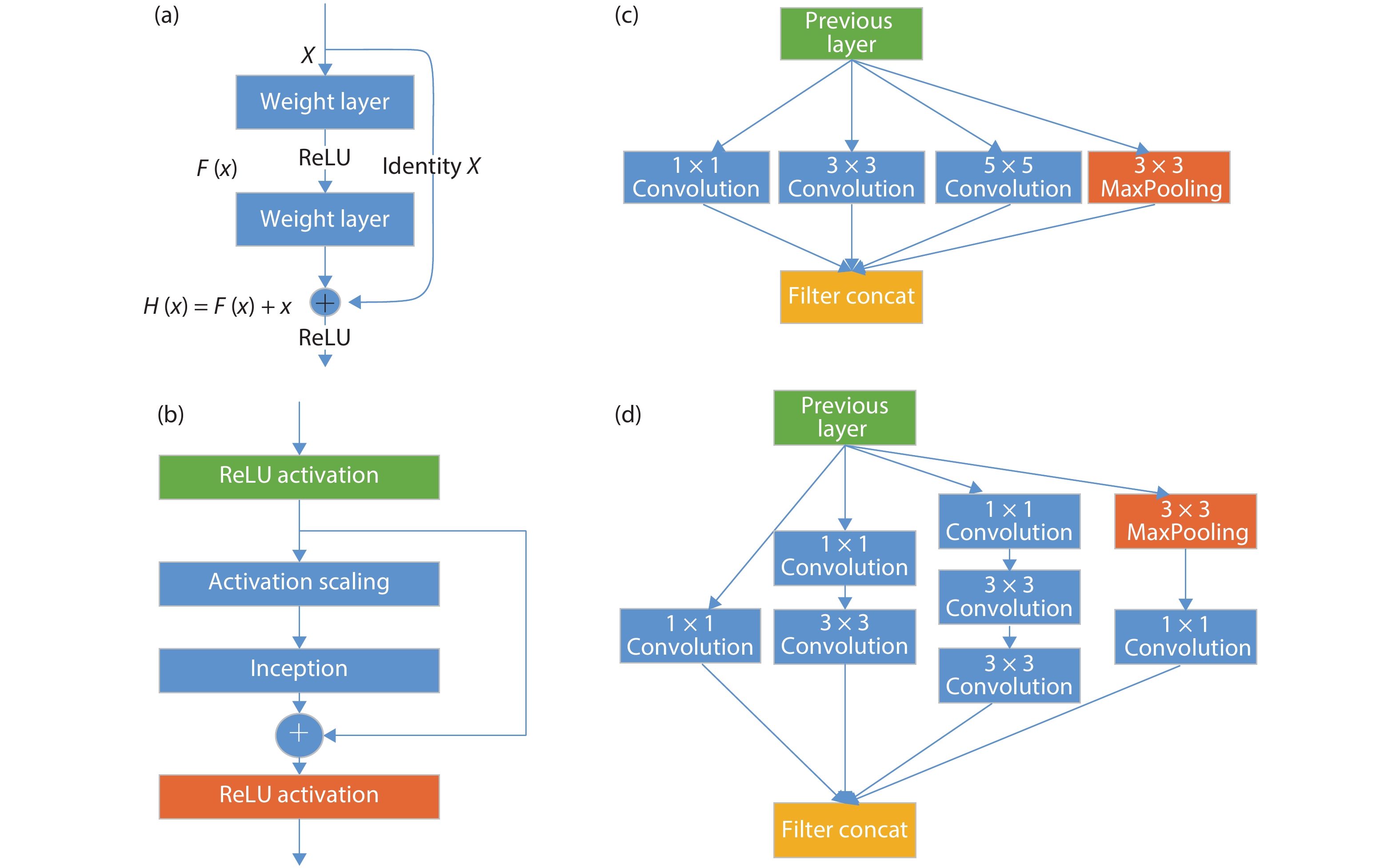
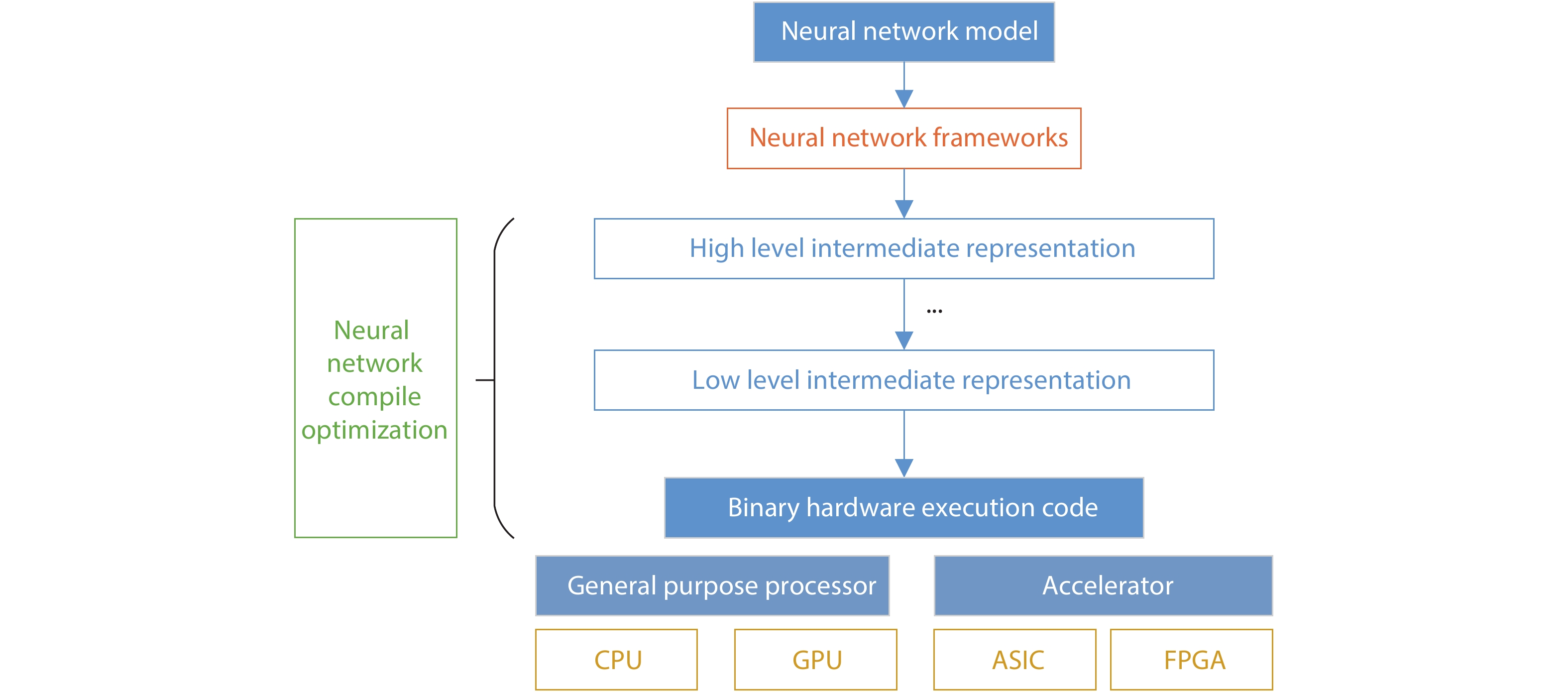
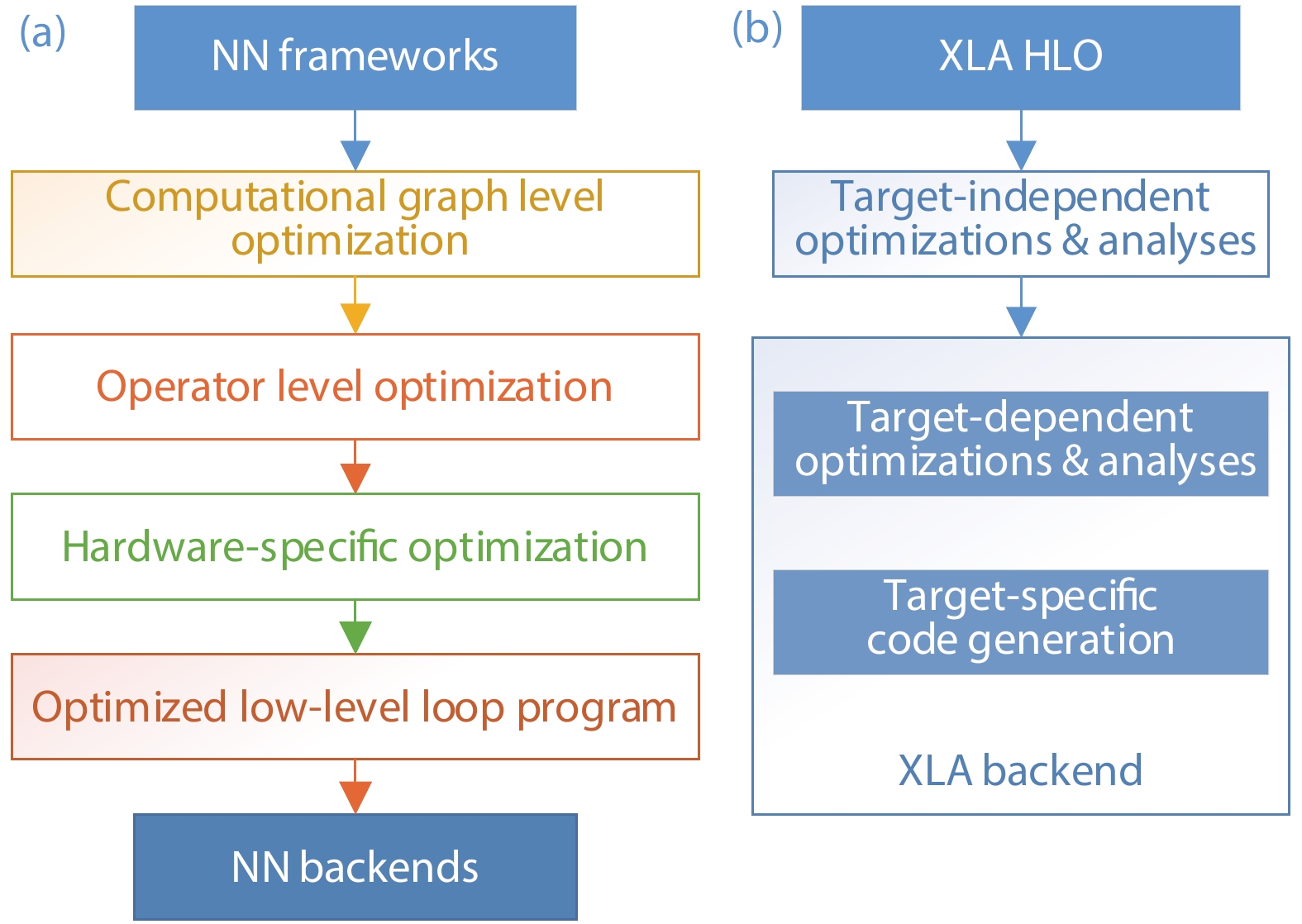
Recent years, the deep learning algorithm has been widely deployed from cloud servers to terminal units. And researchers proposed various neural network accelerators and software development environments. In this article, we have reviewed the representative neural network accelerators. As an entirety, the corresponding software stack must consider the hardware architecture of the specific accelerator to enhance the end-to-end performance. And we summarize the programming environments of neural network accelerators and optimizations in software stack. Finally, we comment the future trend of neural network accelerator and programming environments.

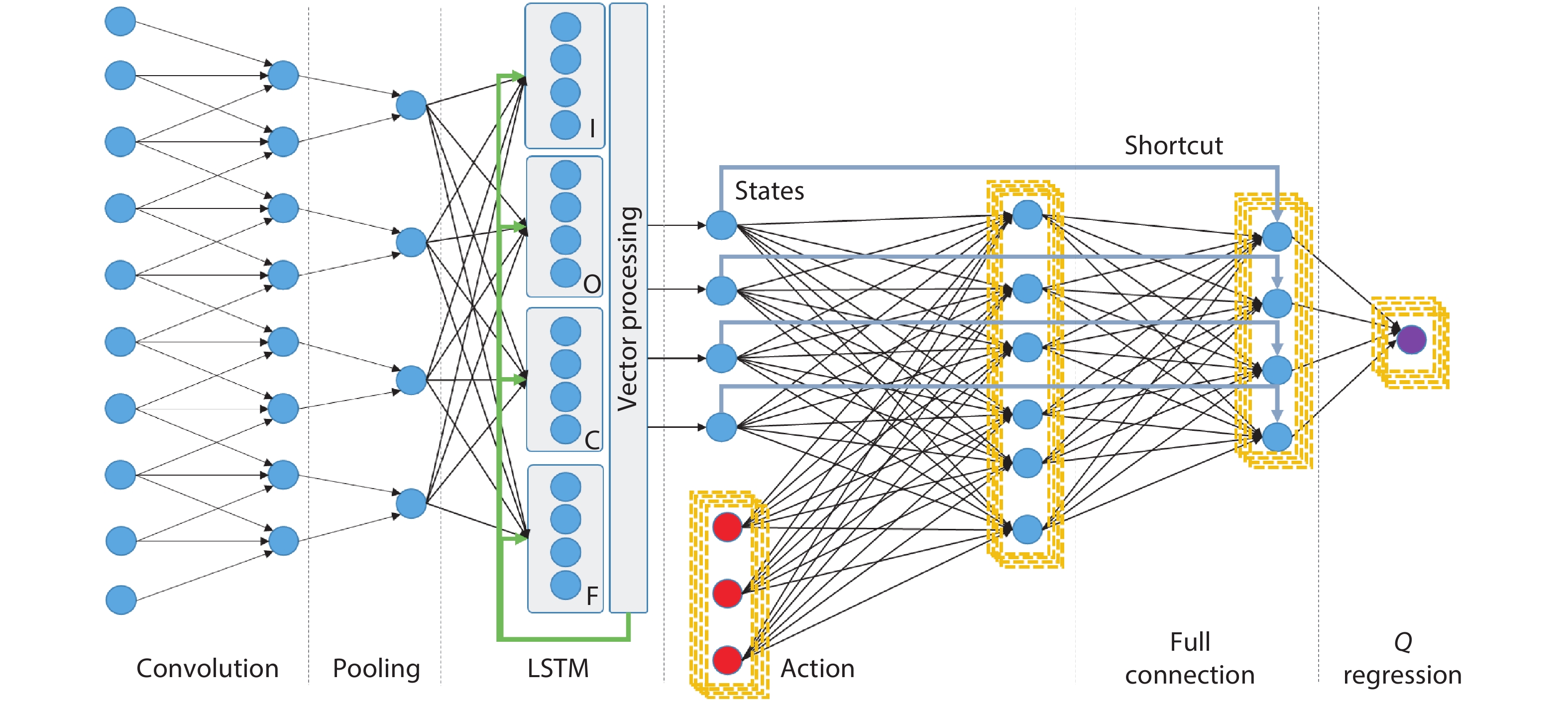
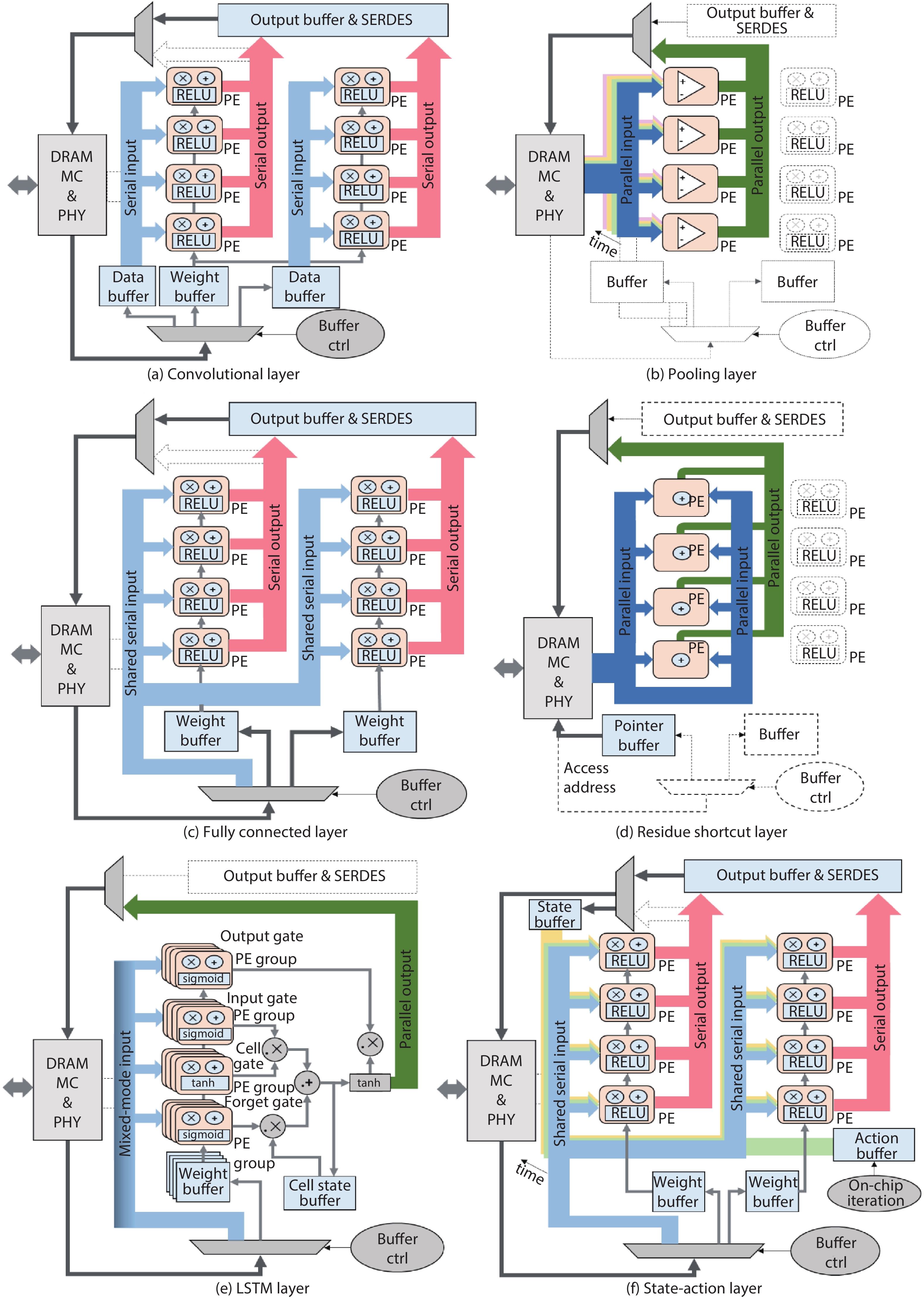
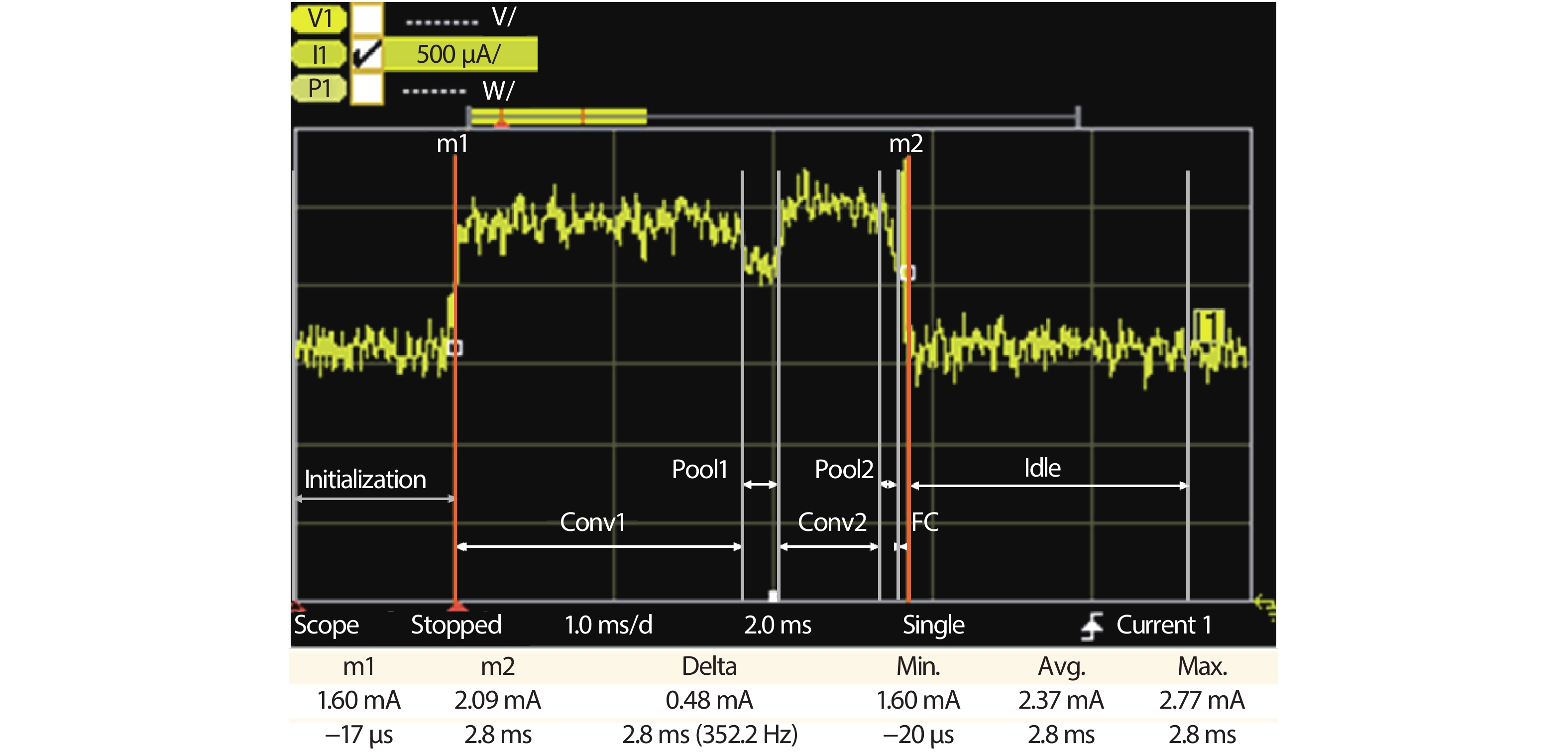
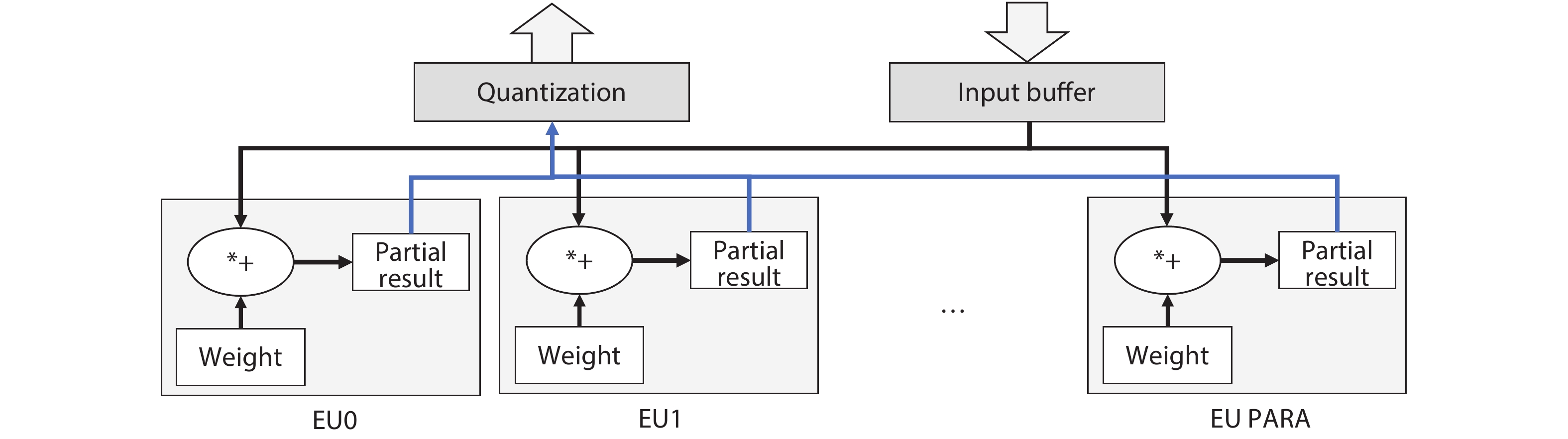
Driven by continuous scaling of nanoscale semiconductor technologies, the past years have witnessed the progressive advancement of machine learning techniques and applications. Recently, dedicated machine learning accelerators, especially for neural networks, have attracted the research interests of computer architects and VLSI designers. State-of-the-art accelerators increase performance by deploying a huge amount of processing elements, however still face the issue of degraded resource utilization across hybrid and non-standard algorithmic kernels. In this work, we exploit the properties of important neural network kernels for both perception and control to propose a reconfigurable dataflow processor, which adjusts the patterns of data flowing, functionalities of processing elements and on-chip storages according to network kernels. In contrast to state-of-the-art fine-grained data flowing techniques, the proposed coarse-grained dataflow reconfiguration approach enables extensive sharing of computing and storage resources. Three hybrid networks for MobileNet, deep reinforcement learning and sequence classification are constructed and analyzed with customized instruction sets and toolchain. A test chip has been designed and fabricated under UMC 65 nm CMOS technology, with the measured power consumption of 7.51 mW under 100 MHz frequency on a die size of 1.8 × 1.8 mm2.

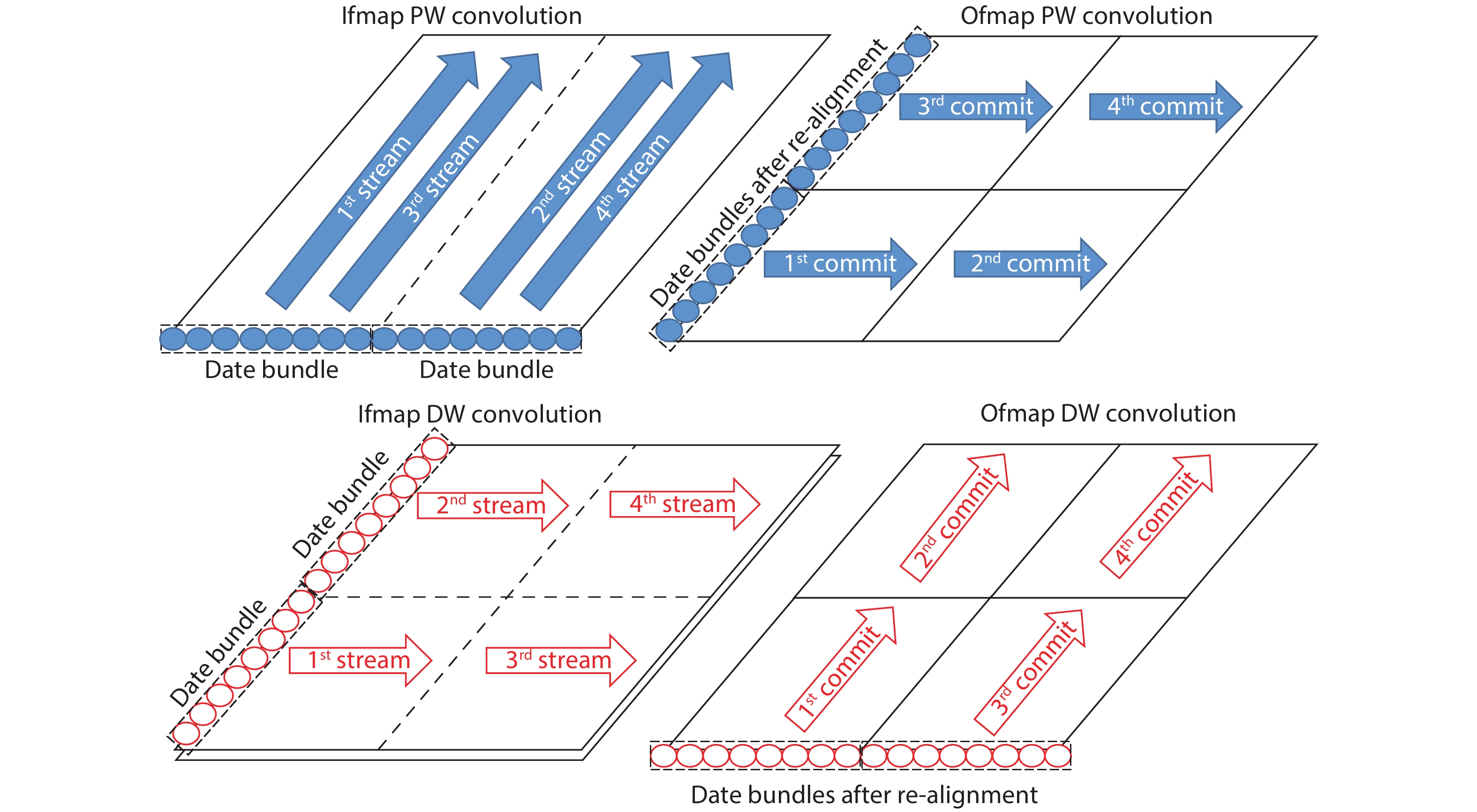
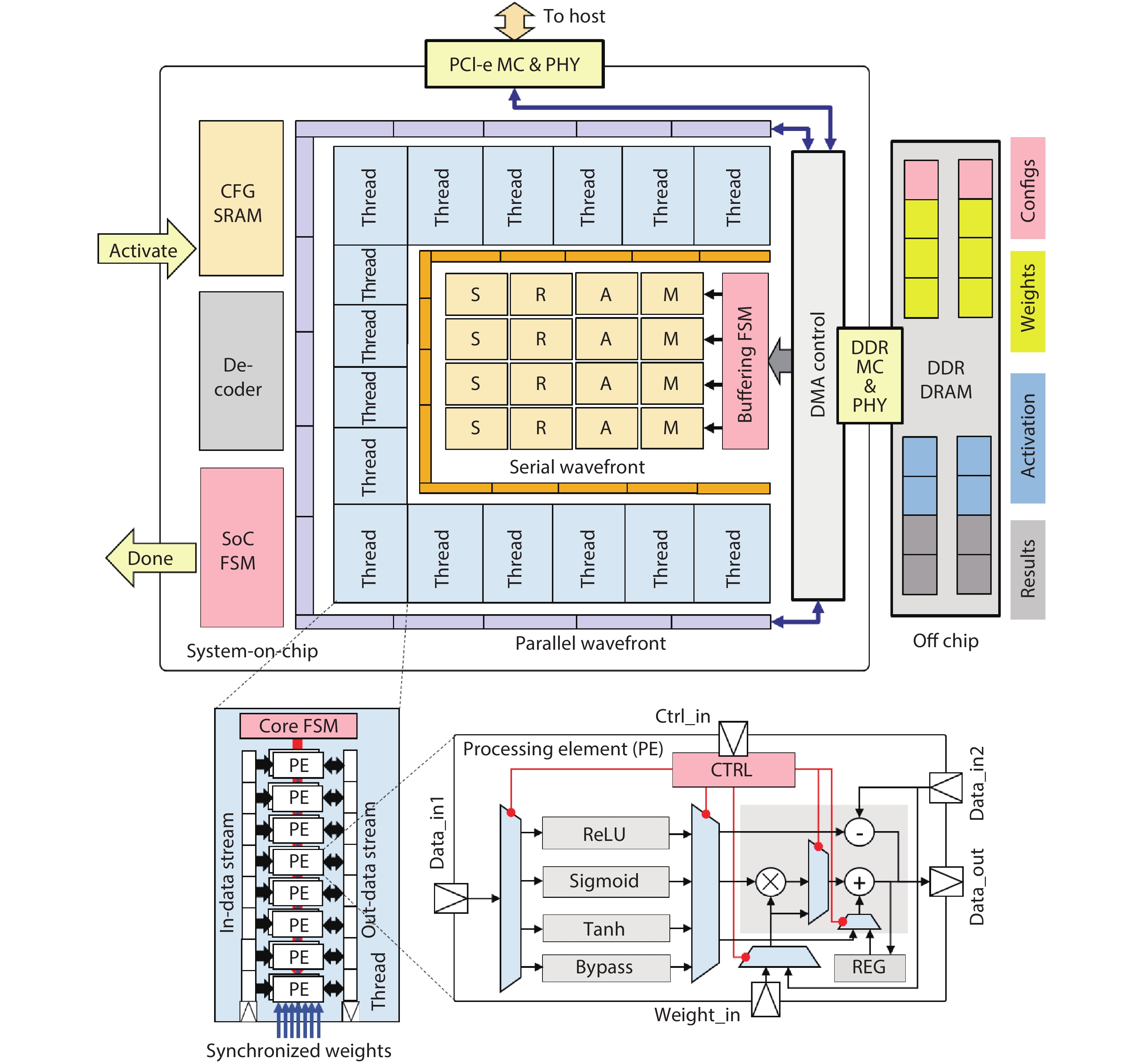
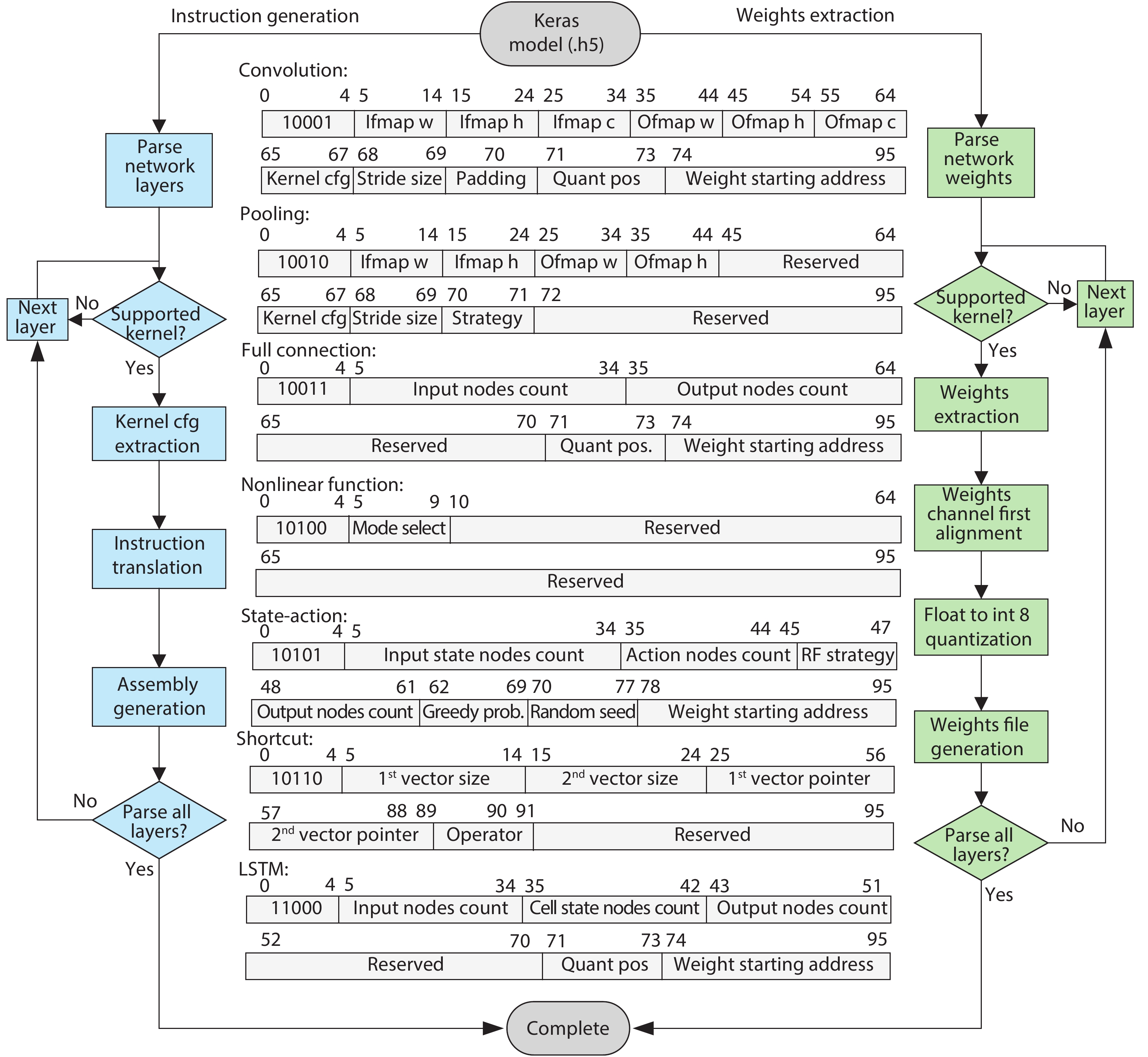

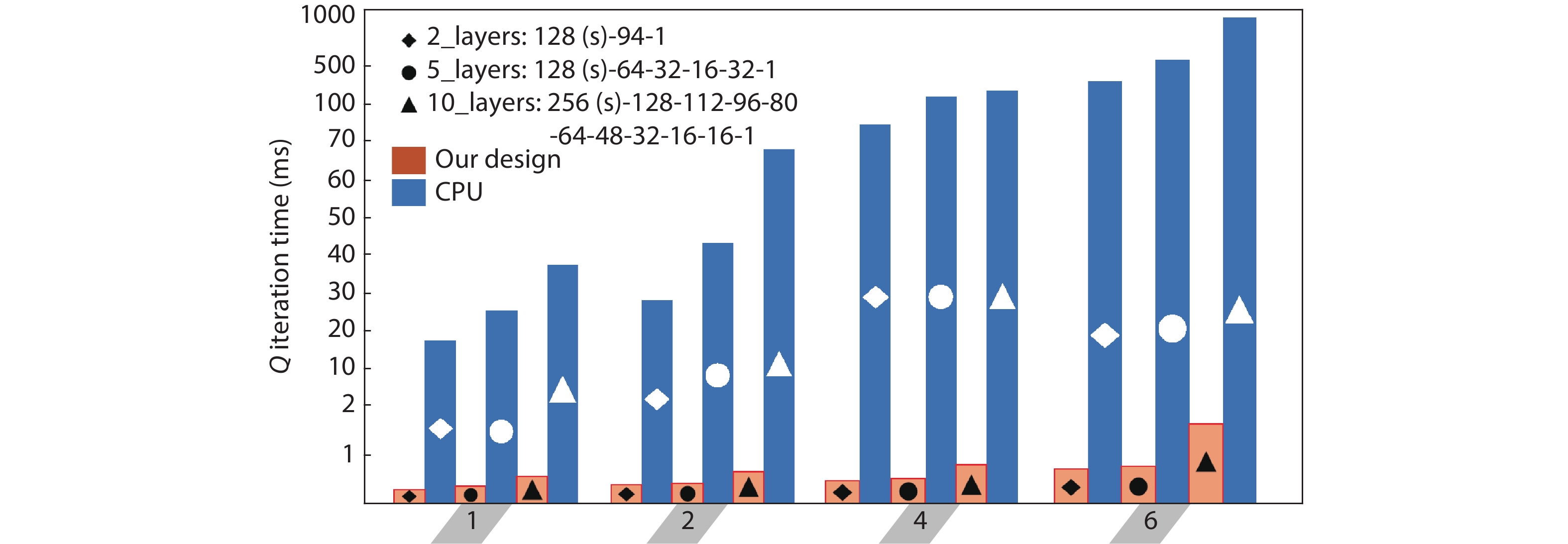



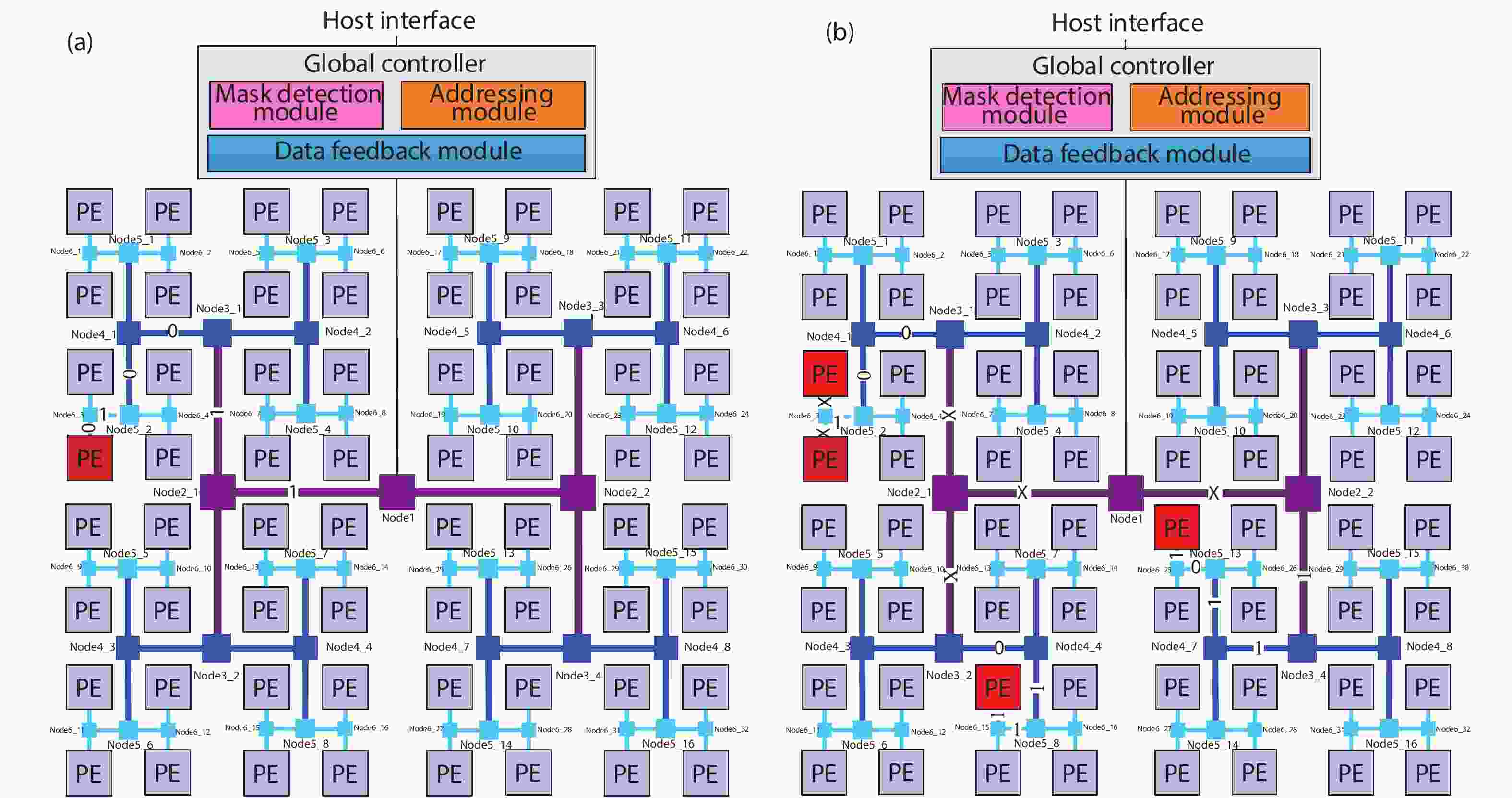
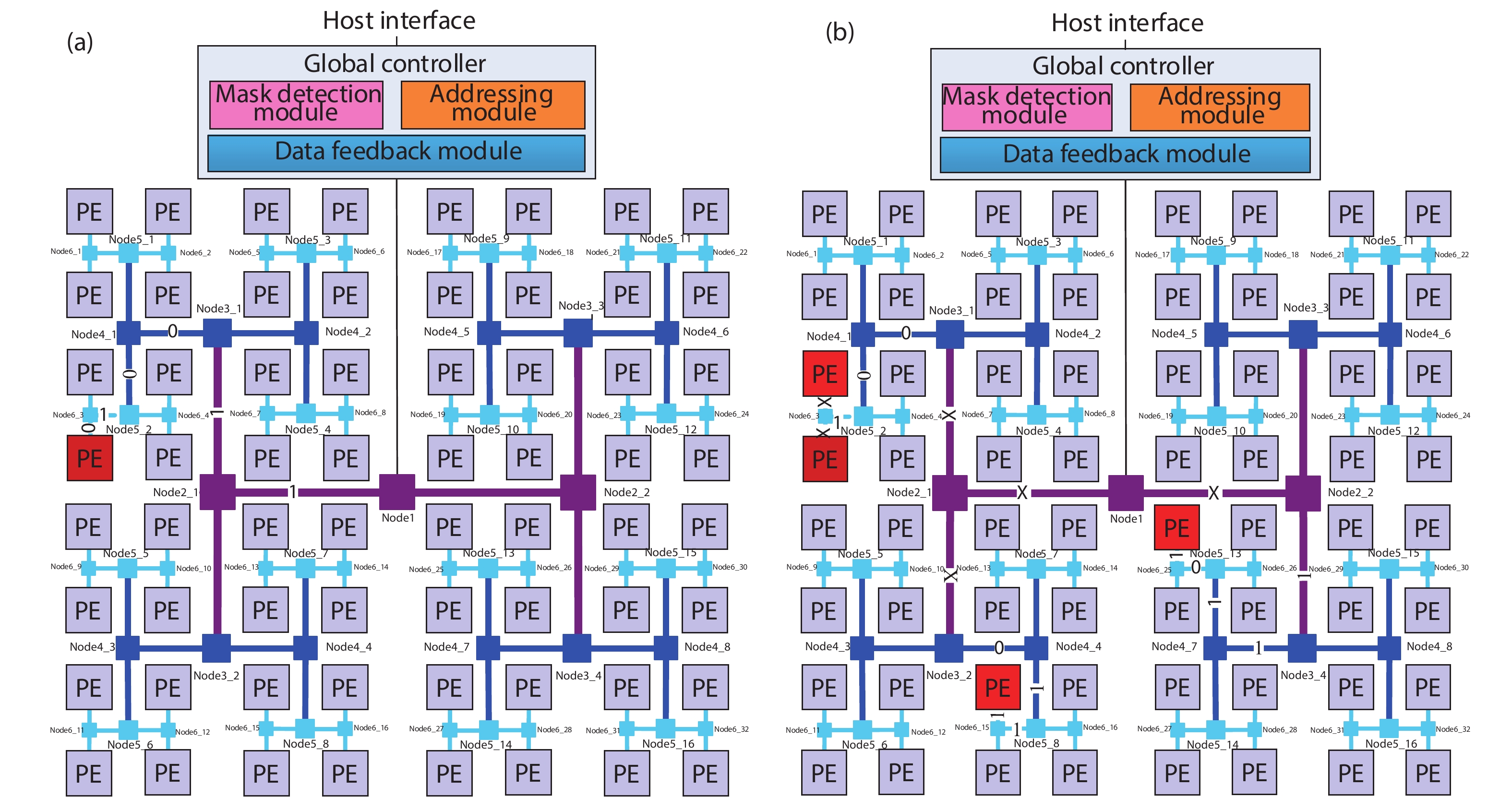
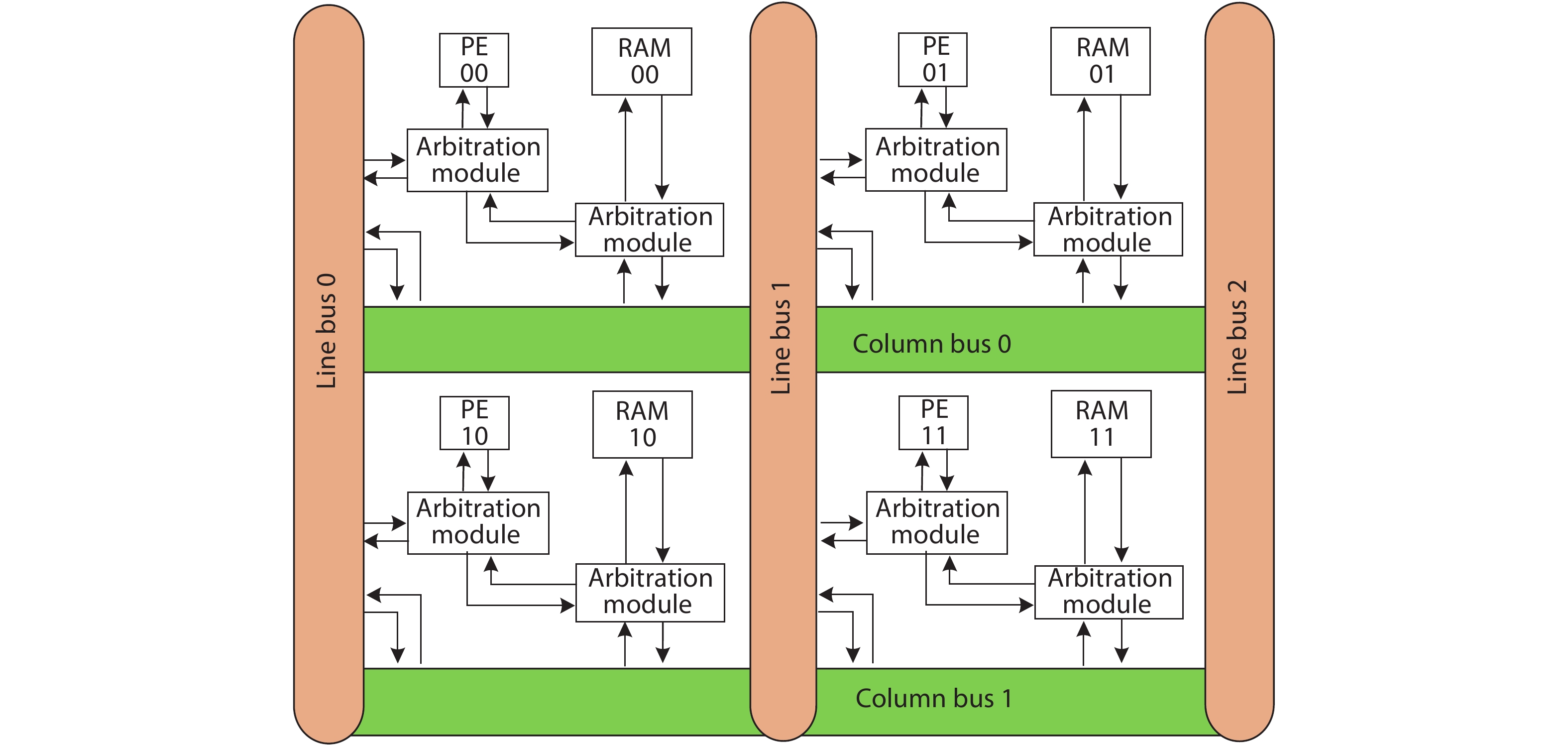
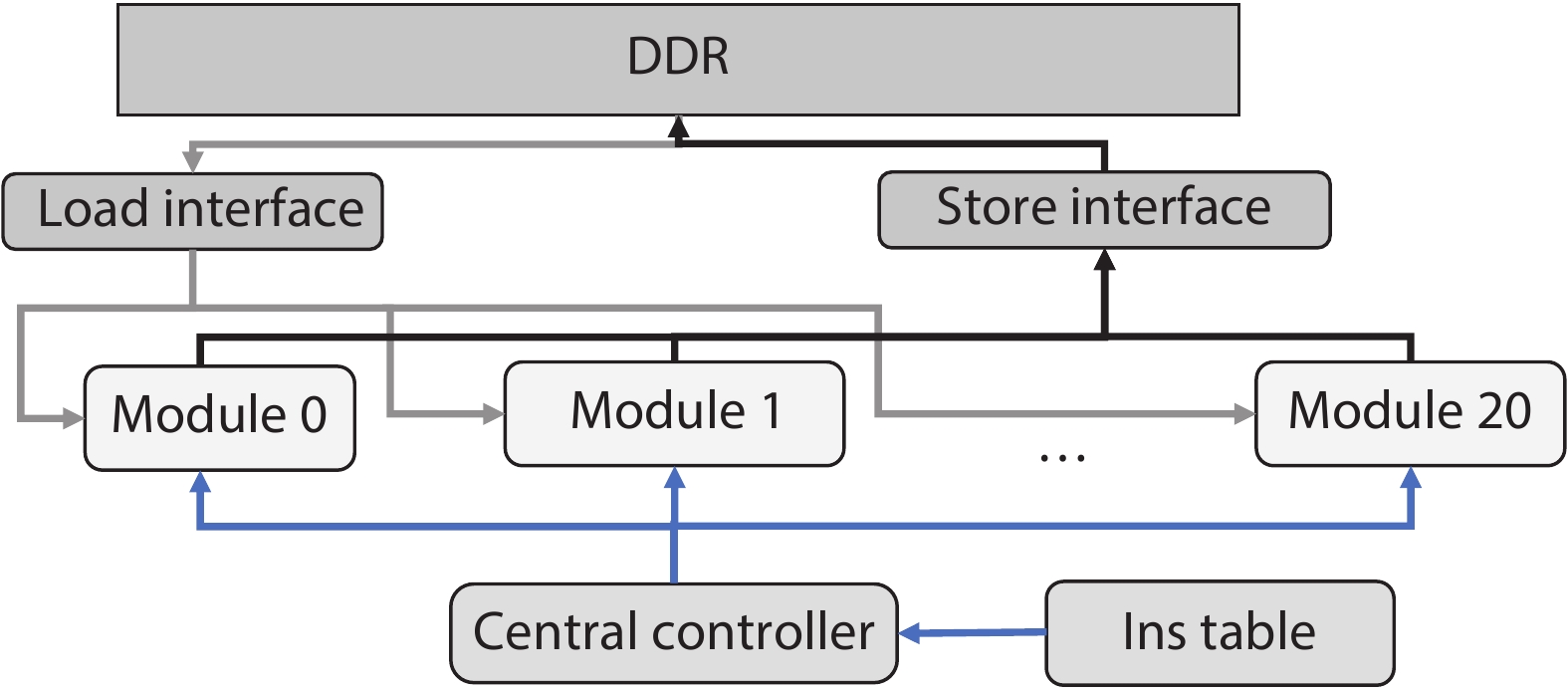
In order to accommodate the variety of algorithms with different performance in specific application and improve power efficiency, reconfigurable architecture has become an effective methodology in academia and industry. However, existing architectures suffer from performance bottleneck due to slow updating of contexts and inadequate flexibility. This paper presents an H-tree based reconfiguration mechanism (HRM) with Huffman-coding-like and mask addressing method in a homogeneous processing element (PE) array, which supports both programmable and data-driven modes. The proposed HRM can transfer reconfiguration instructions/contexts to a particular PE or associated PEs simultaneously in one clock cycle in unicast, multicast and broadcast mode, and shut down the unnecessary PE/PEs according to the current configuration. To verify the correctness and efficiency, we implement it in RTL synthesis and FPGA prototype. Compared to prior works, the experiment results show that the HRM has improved the work frequency by an average of 23.4%, increased the updating speed by 2×, and reduced the area by 36.9%; HRM can also power off the unnecessary PEs which reduced 51% of dynamic power dissipation in certain application configuration. Furthermore, in the data-driven mode, the system frequency can reach 214 MHz, which is 1.68× higher compared with the programmable mode.
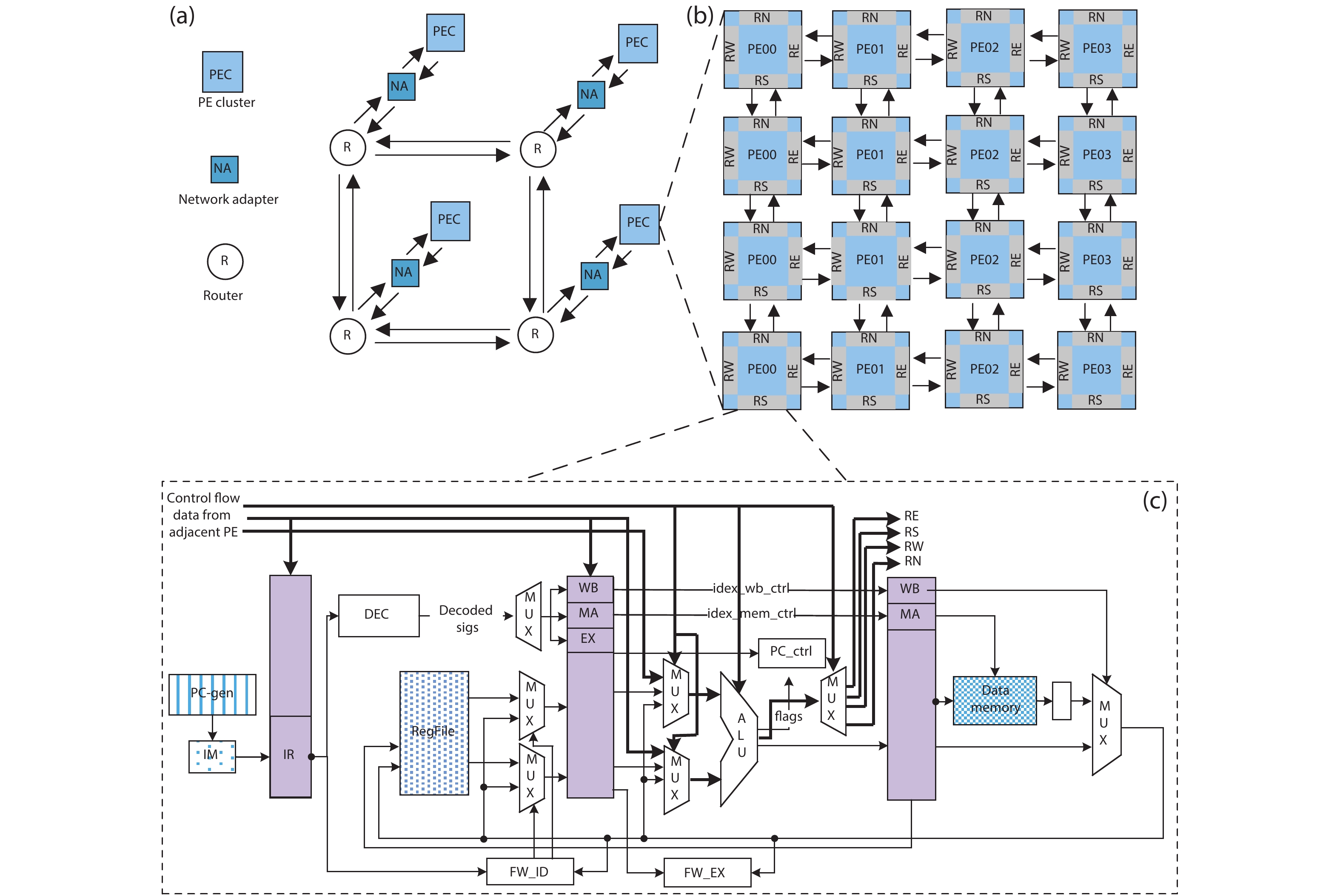





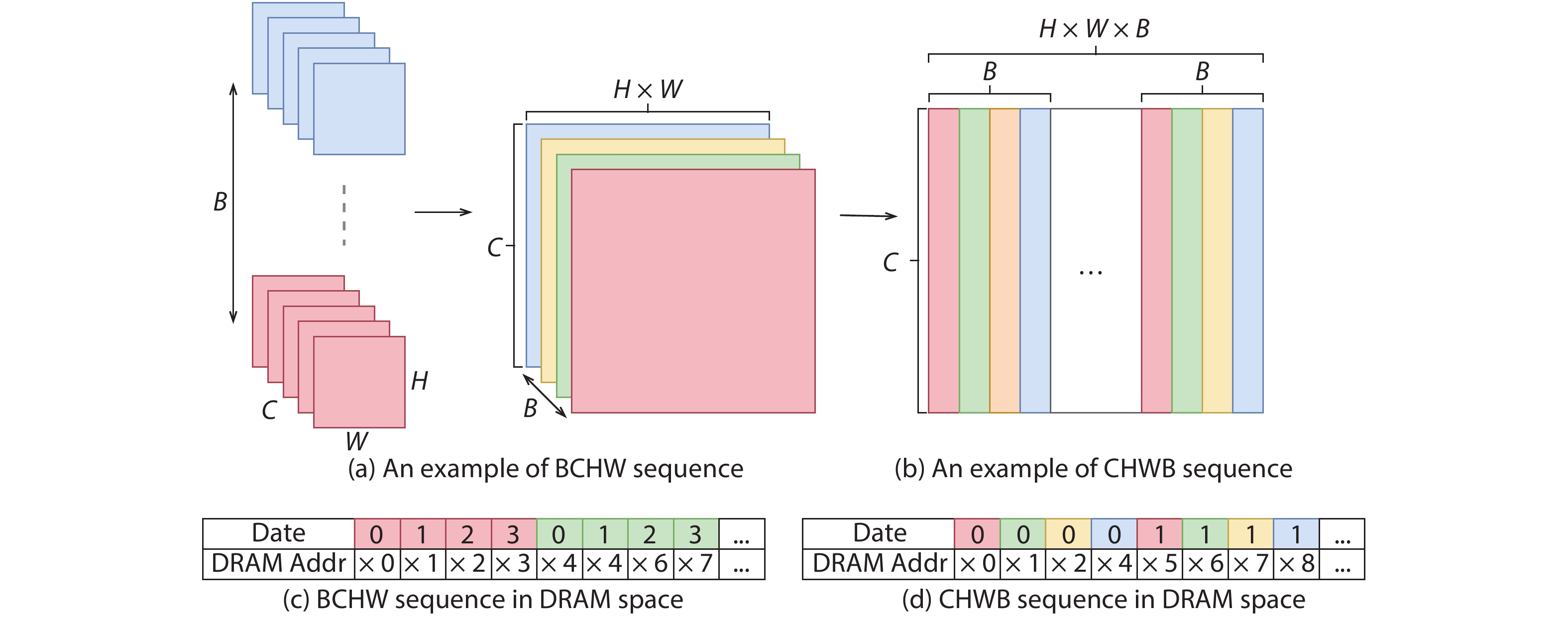
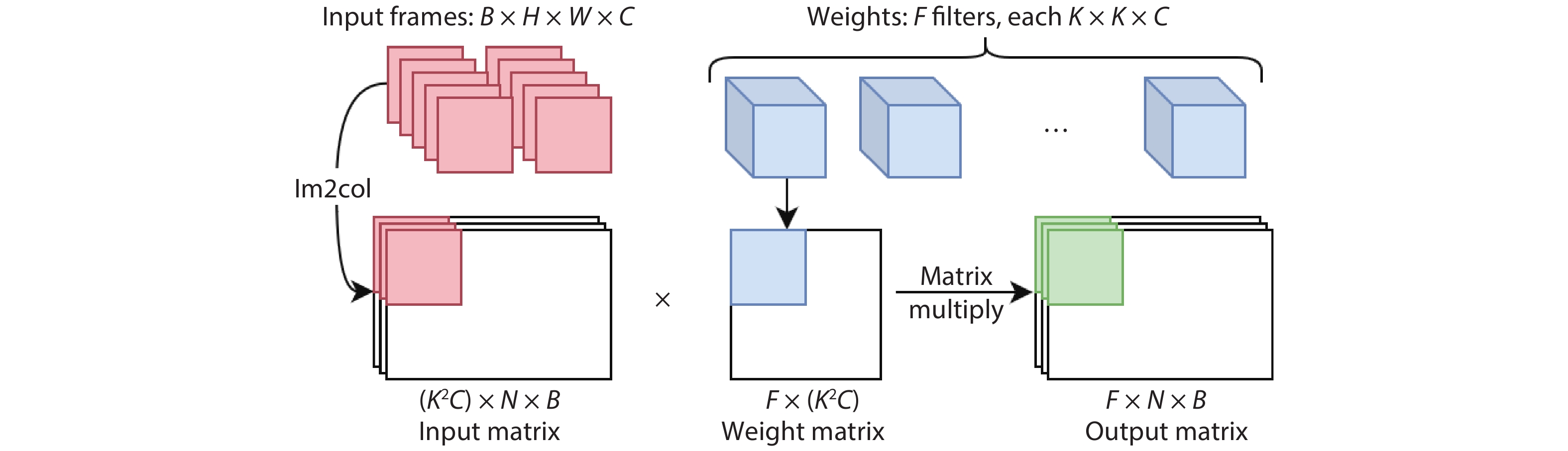
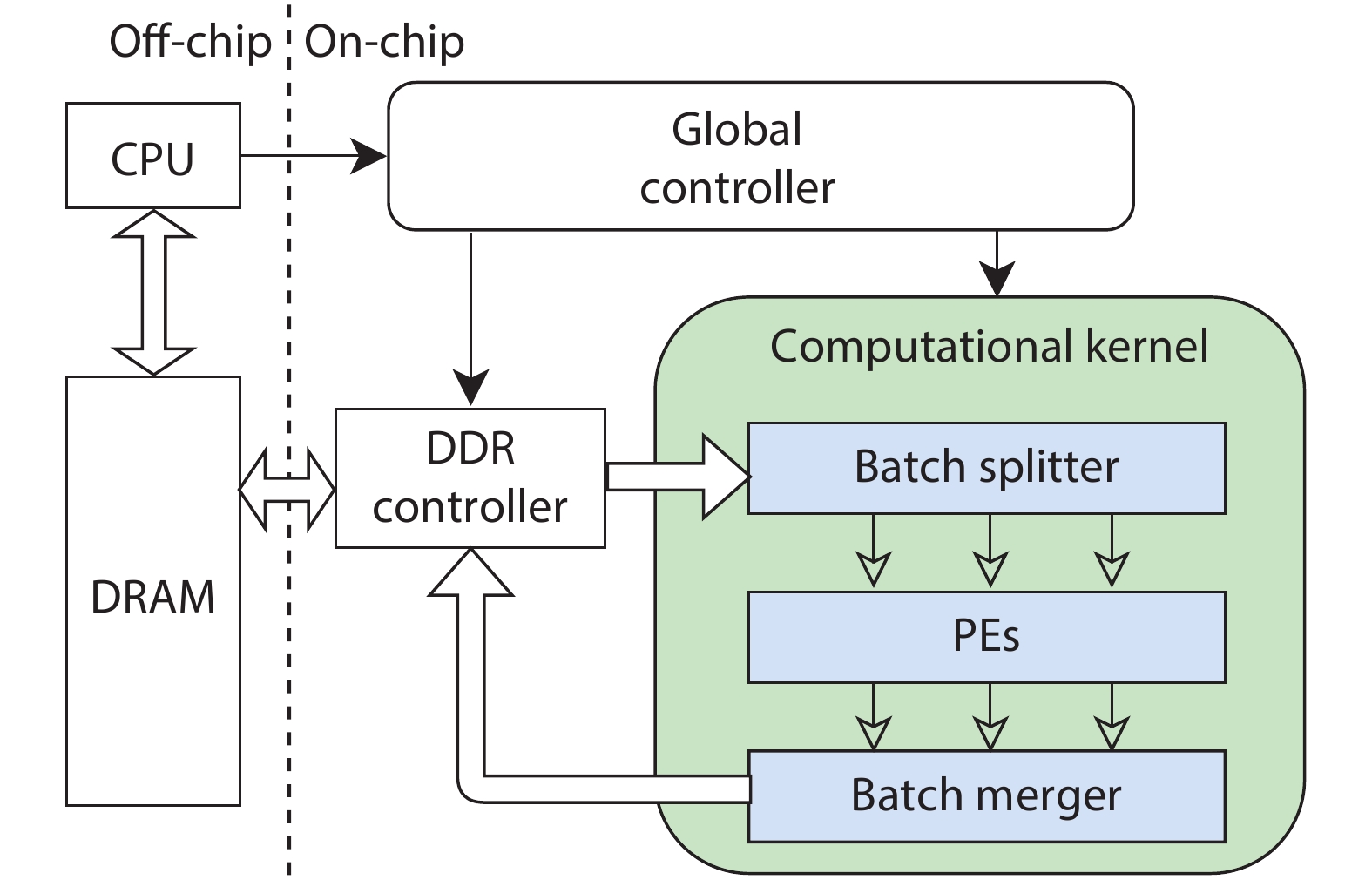
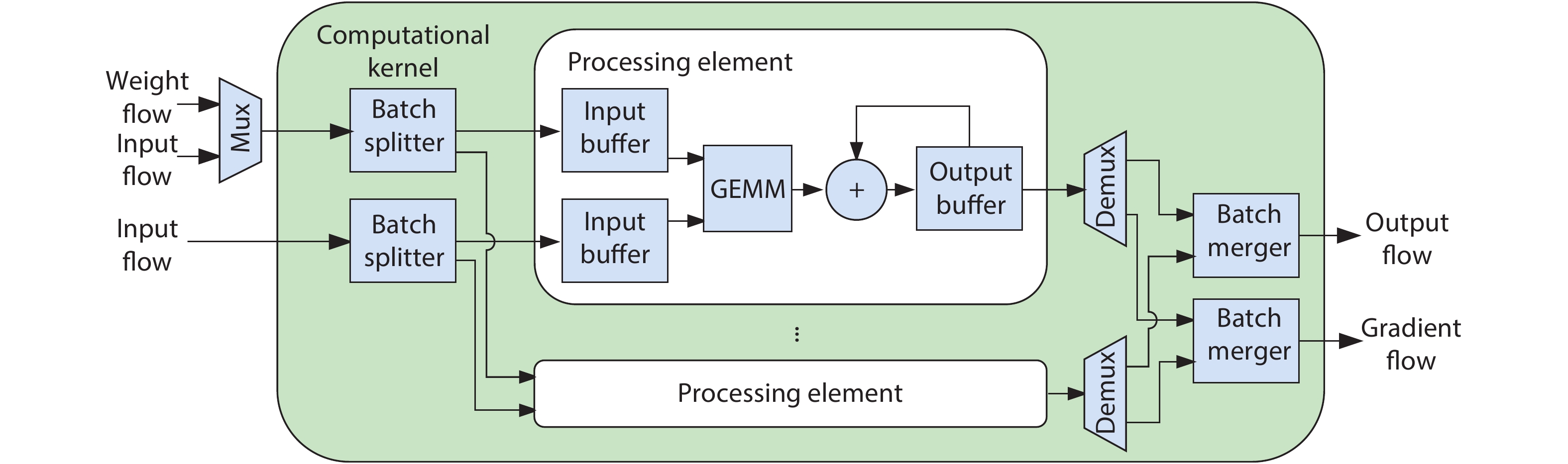
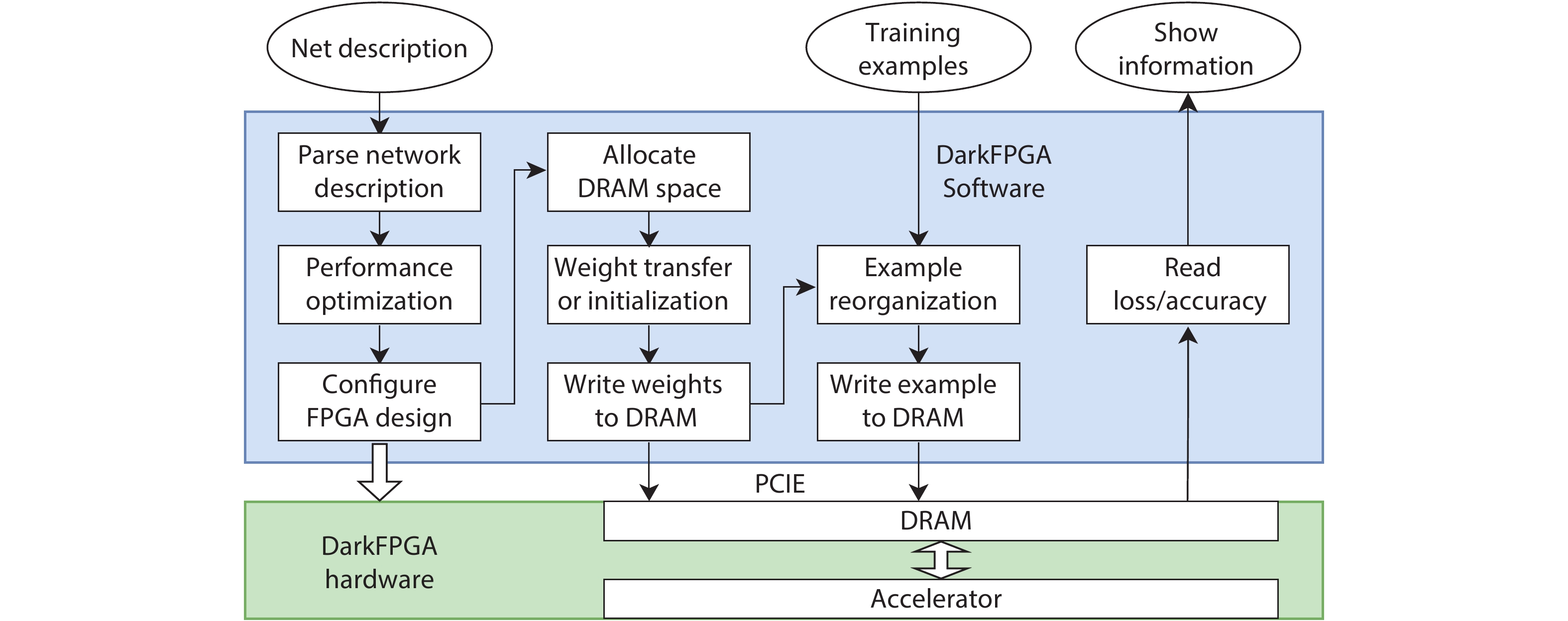
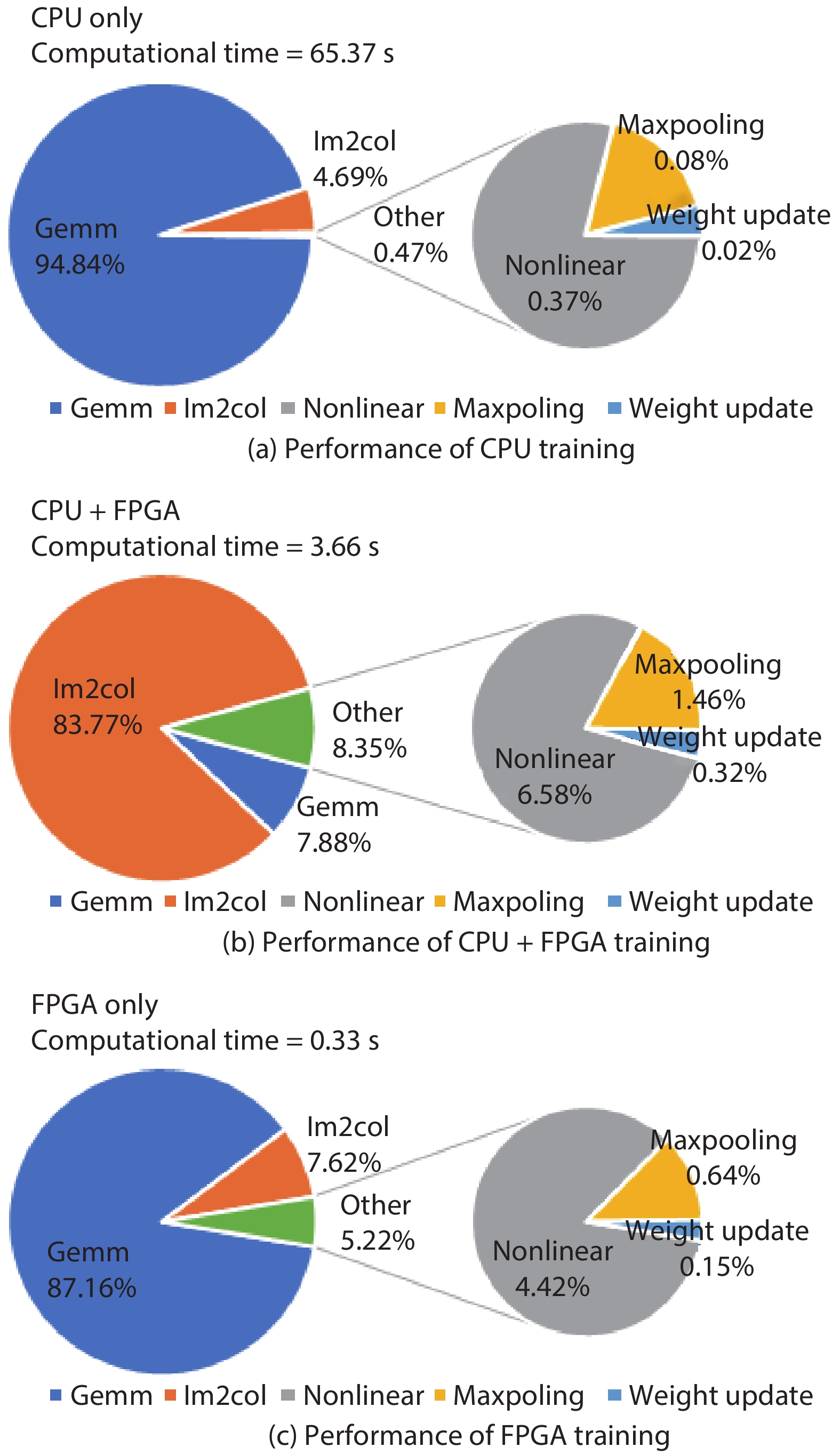
Training deep neural networks (DNNs) requires a significant amount of time and resources to obtain acceptable results, which severely limits its deployment in resource-limited platforms. This paper proposes DarkFPGA, a novel customizable framework to efficiently accelerate the entire DNN training on a single FPGA platform. First, we explore batch-level parallelism to enable efficient FPGA-based DNN training. Second, we devise a novel hardware architecture optimised by a batch-oriented data pattern and tiling techniques to effectively exploit parallelism. Moreover, an analytical model is developed to determine the optimal design parameters for the DarkFPGA accelerator with respect to a specific network specification and FPGA resource constraints. Our results show that the accelerator is able to perform about 10 times faster than CPU training and about a third of the energy consumption than GPU training using 8-bit integers for training VGG-like networks on the CIFAR dataset for the Maxeler MAX5 platform.
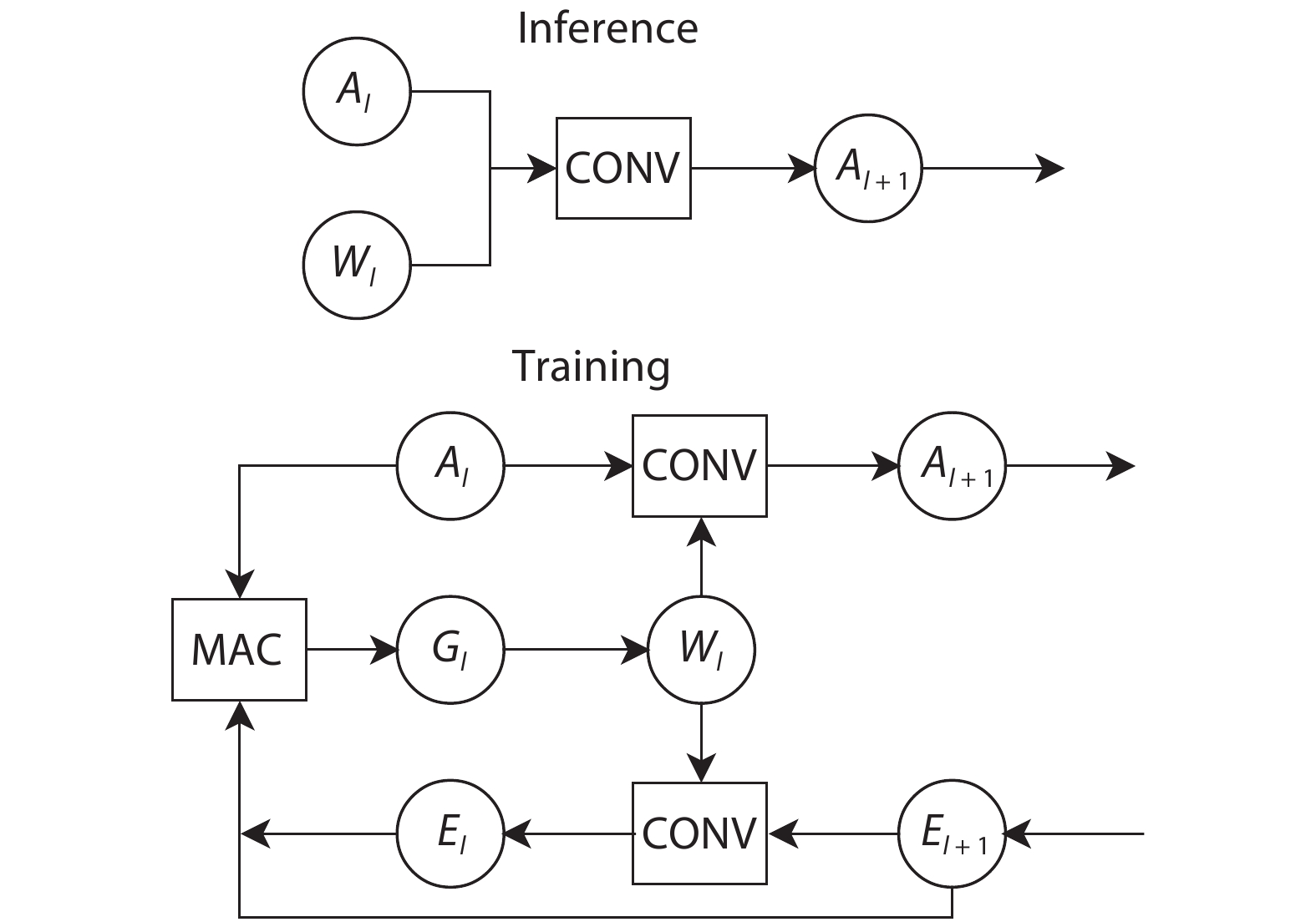



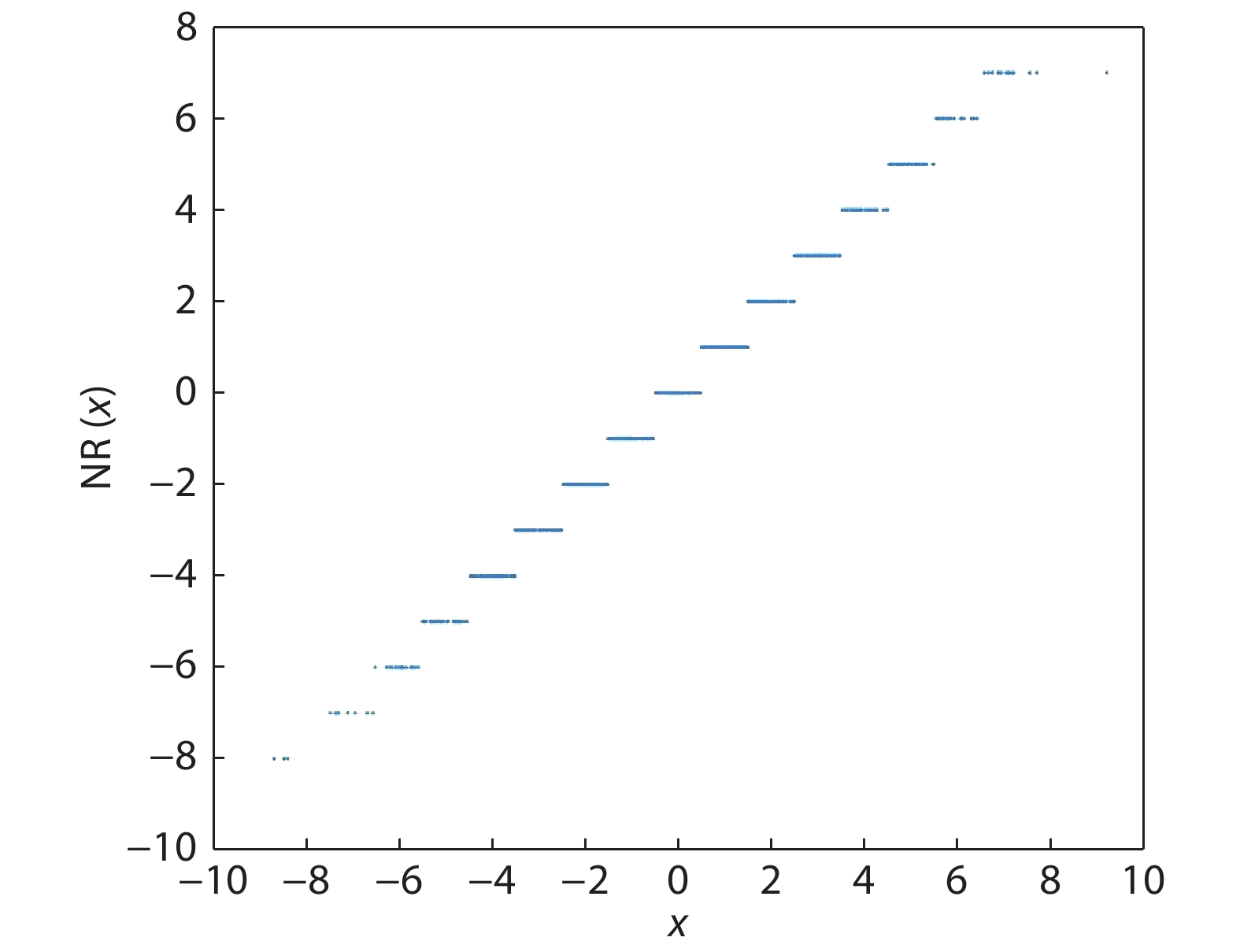
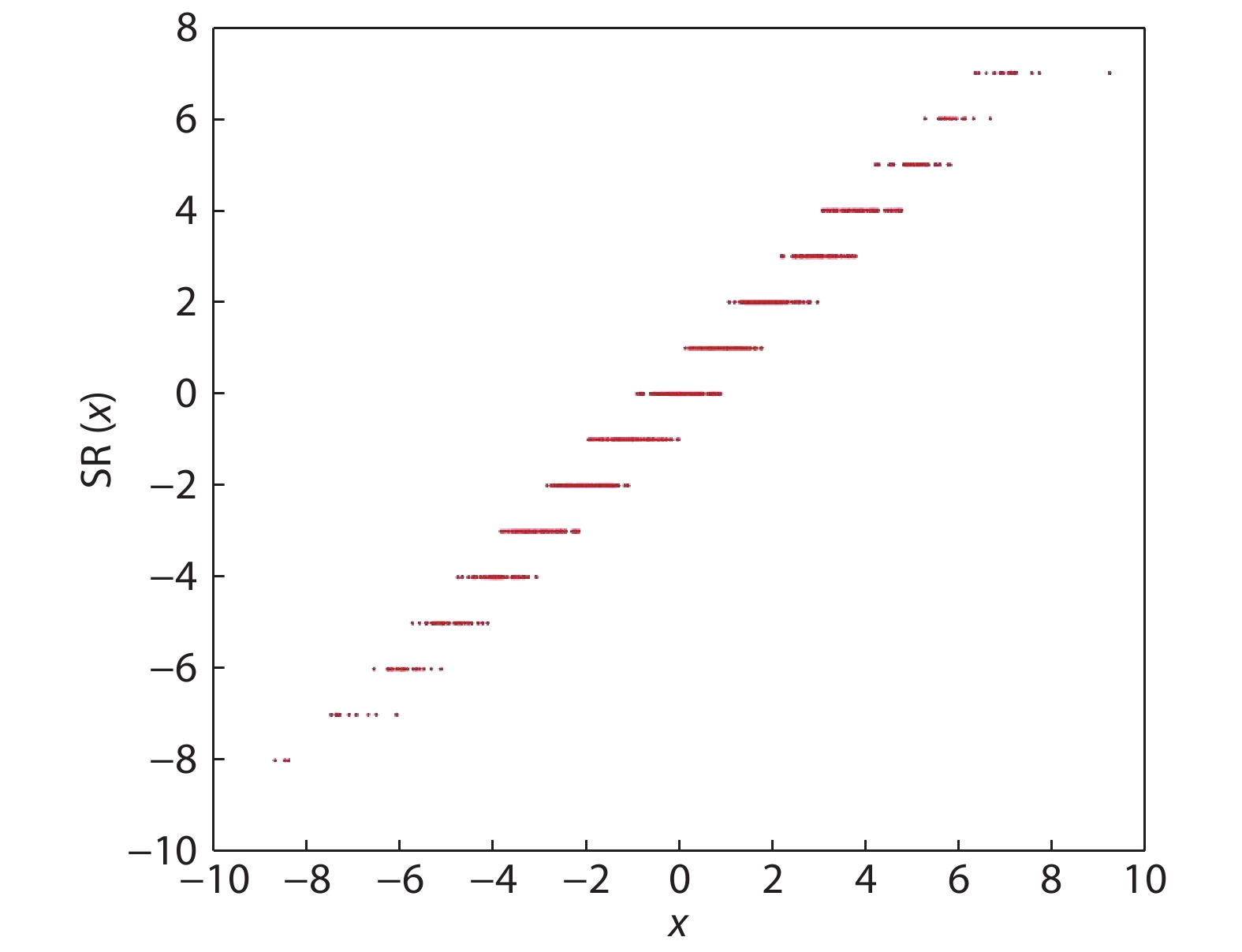
The high performance of the state-of-the-art deep neural networks (DNNs) is acquired at the cost of huge consumption of computing resources. Quantization of networks is recently recognized as a promising solution to solve the problem and significantly reduce the resource usage. However, the previous quantization works have mostly focused on the DNN inference, and there were very few works to address on the challenges of DNN training. In this paper, we leverage dynamic fixed-point (DFP) quantization algorithm and stochastic rounding (SR) strategy to develop a fully quantized 8-bit neural networks targeting low bitwidth training. The experiments show that, in comparison to the full-precision networks, the accuracy drop of our quantized convolutional neural networks (CNNs) can be less than 2%, even when applied to deep models evaluated on ImageNet dataset. Additionally, our 8-bit GNMT translation network can achieve almost identical BLEU to full-precision network. We further implement a prototype on FPGA and the synthesis shows that the low bitwidth training scheme can reduce the resource usage significantly.


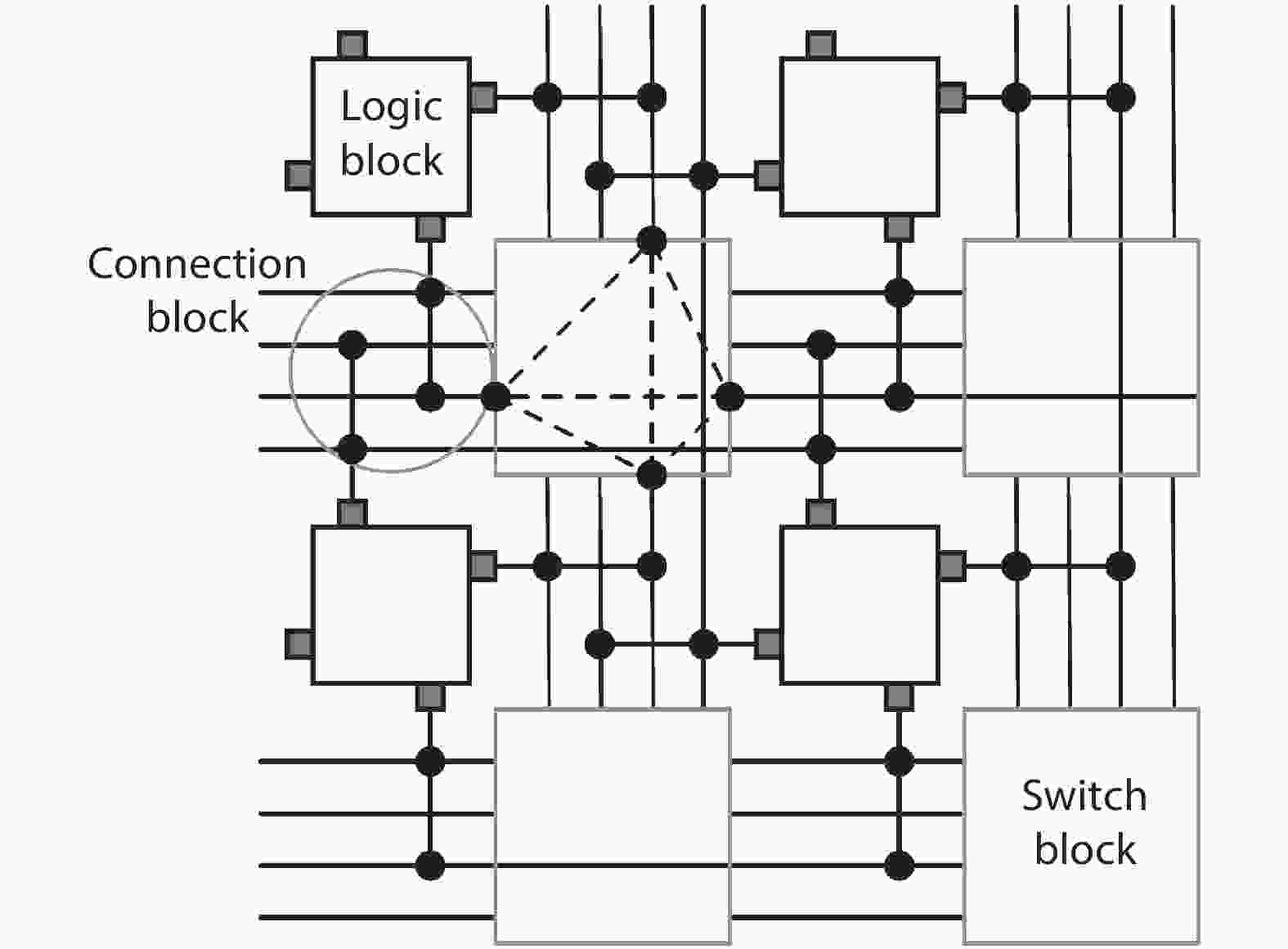
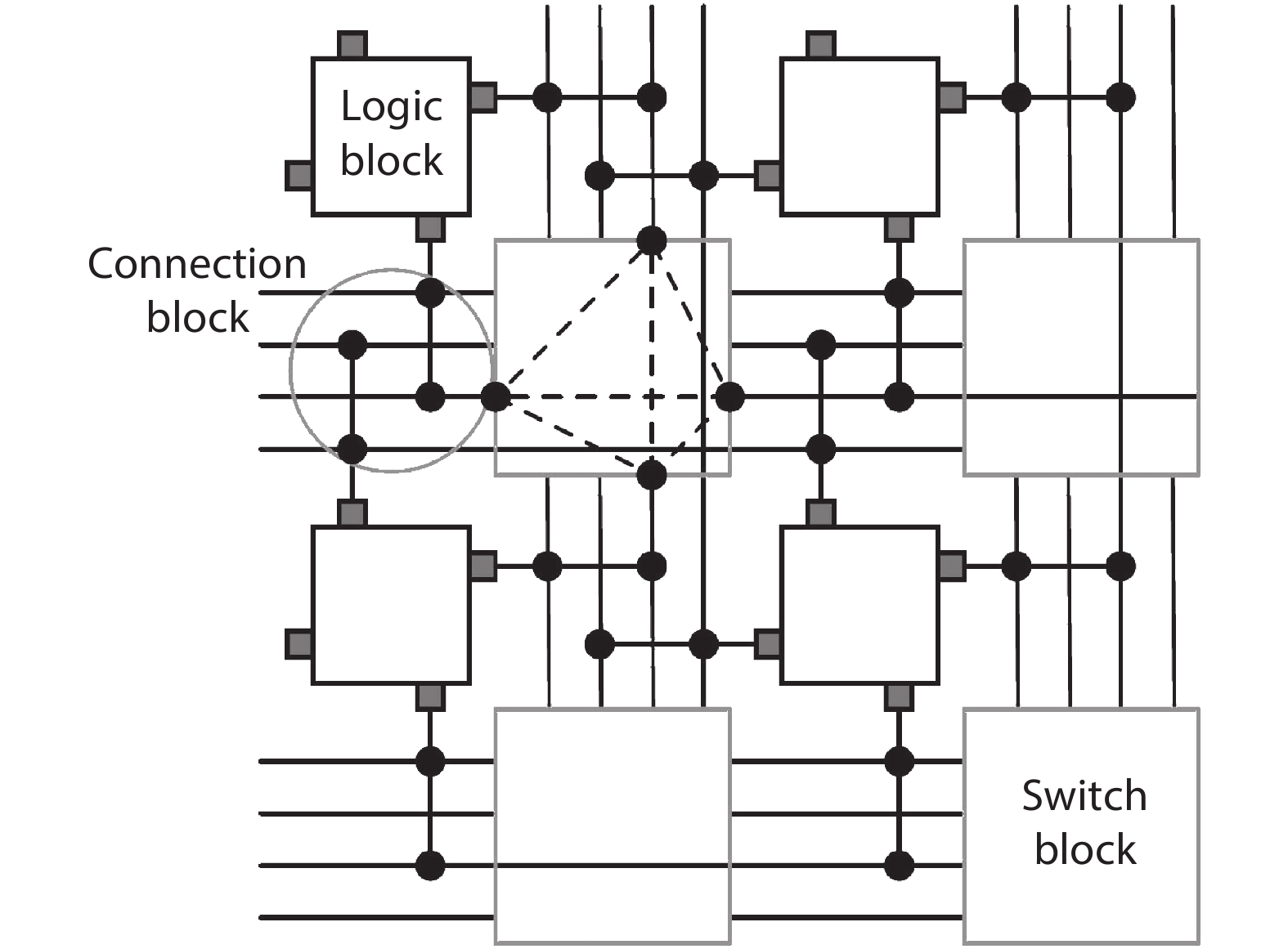
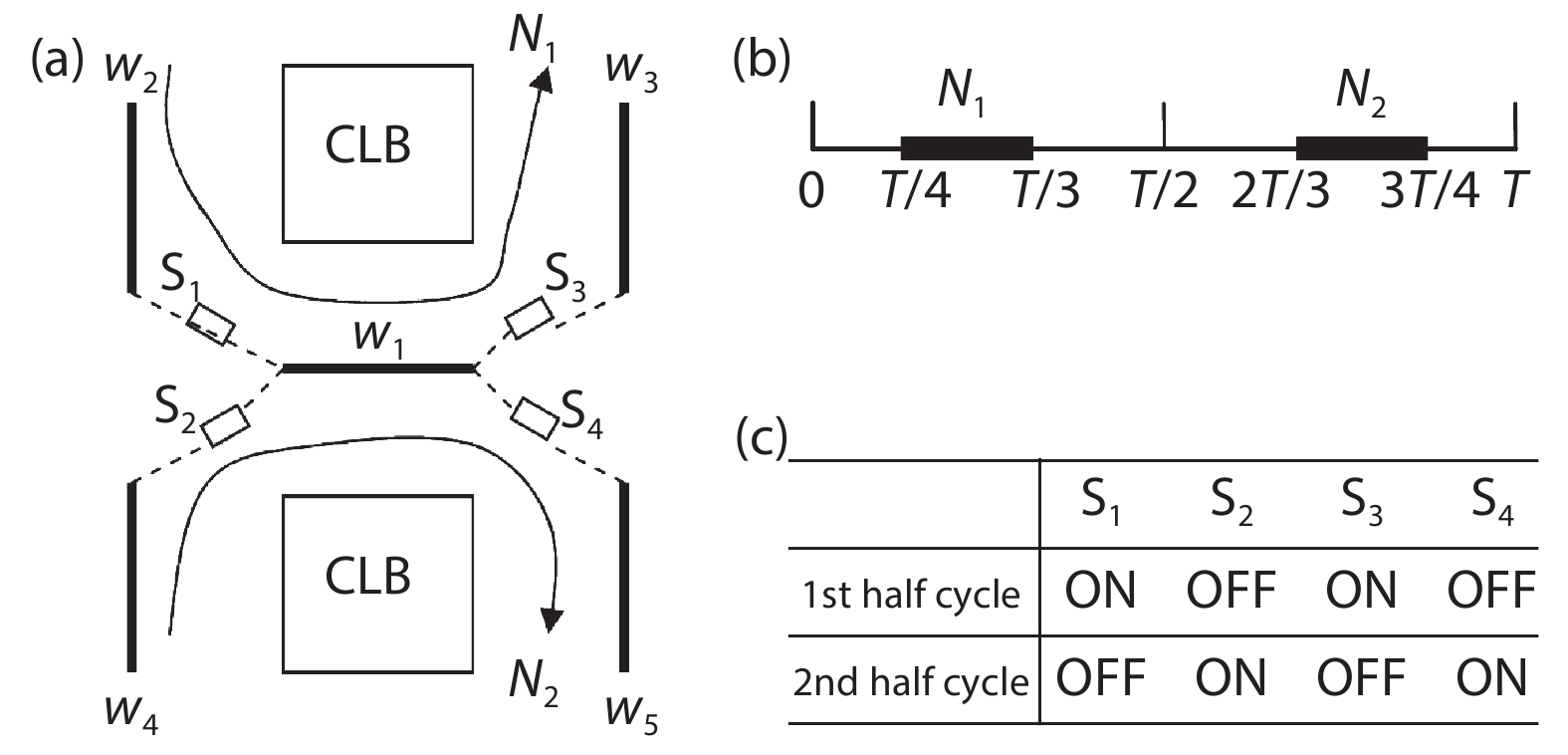
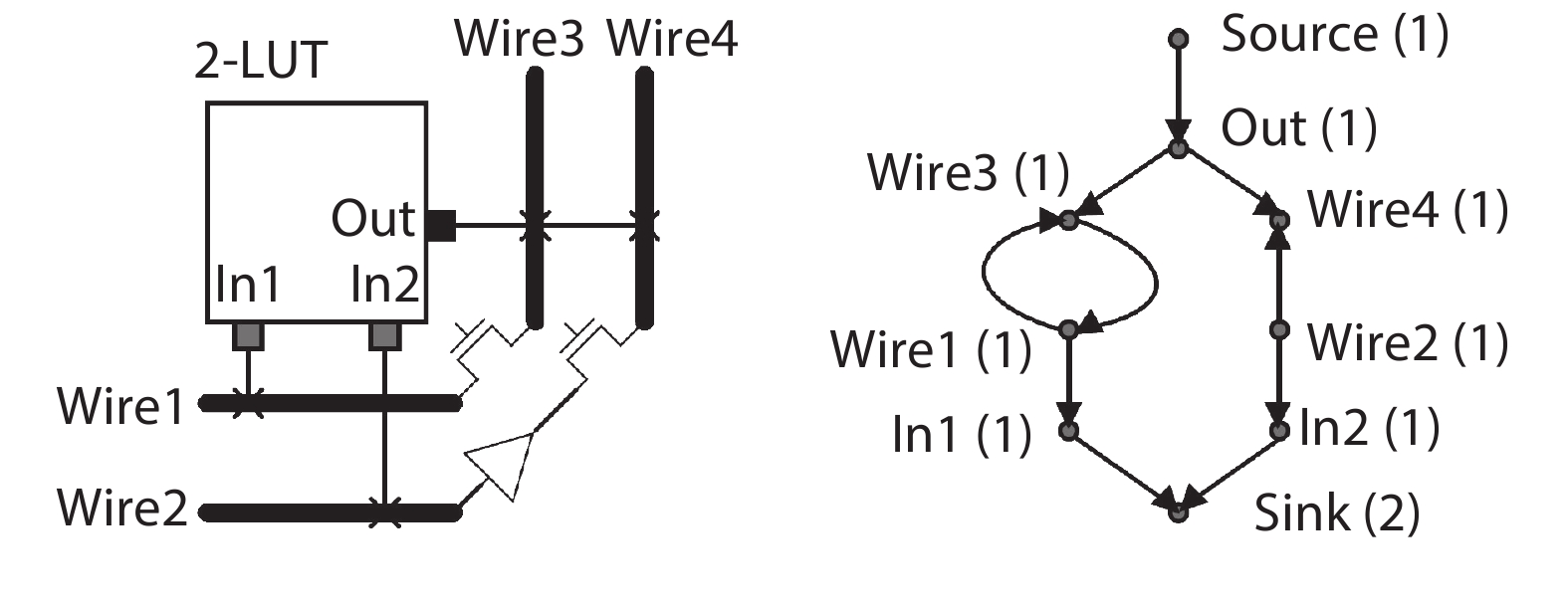
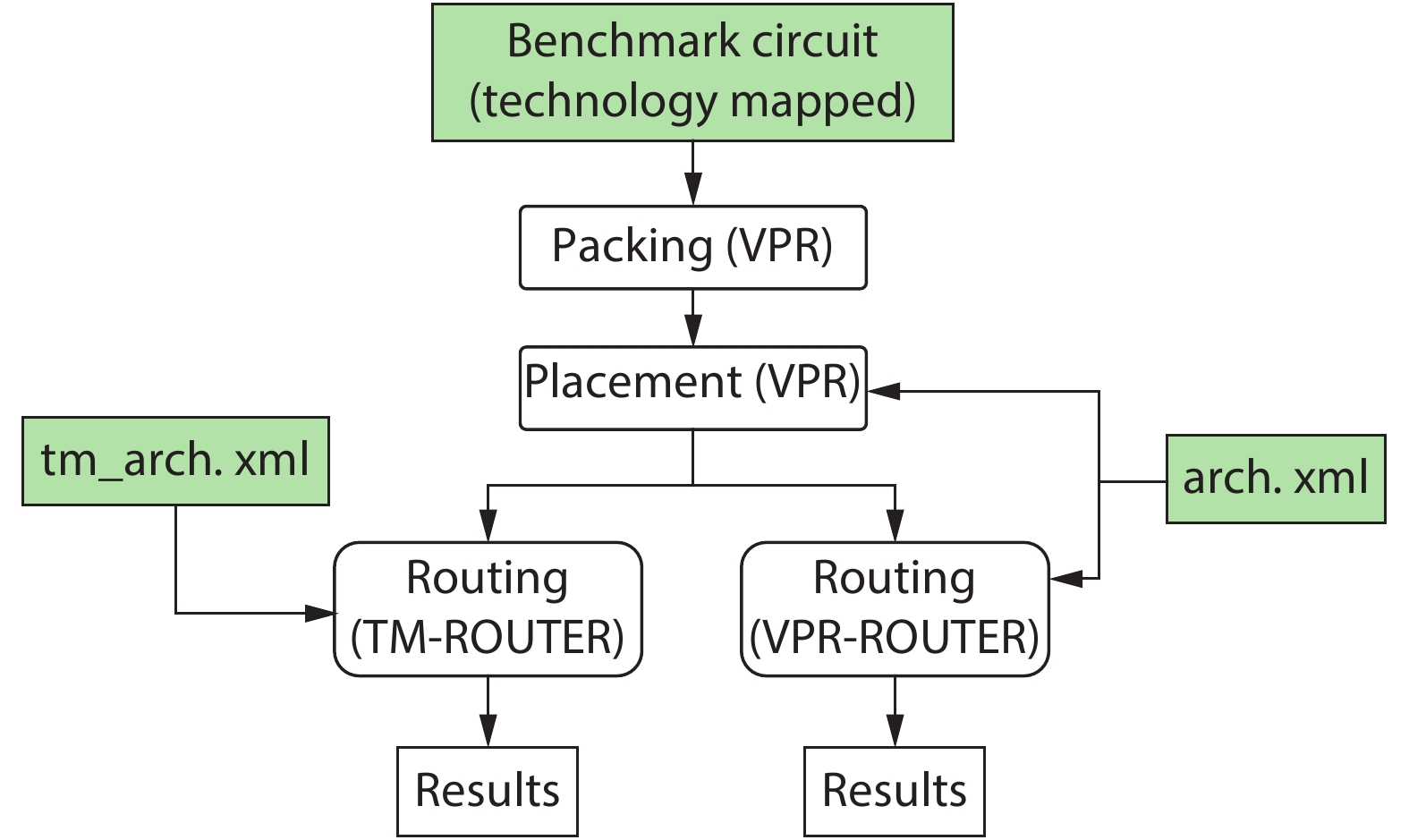
Previous studies show that interconnects occupy a large portion of the timing budget and area in FPGAs. In this work, we propose a time-multiplexing technique on FPGA interconnects. In order to fully exploit this interconnect architecture, we propose a time-multiplexed routing algorithm that can actively identify qualified nets and schedule them to multiplexable wires. We validate the algorithm by using the router to implement 20 benchmark circuits to time-multiplexed FPGAs. We achieve a 38% smaller minimum channel width and 3.8% smaller circuit critical path delay compared with the state-of-the-art architecture router when a wire can be time-multiplexed six times in a cycle.




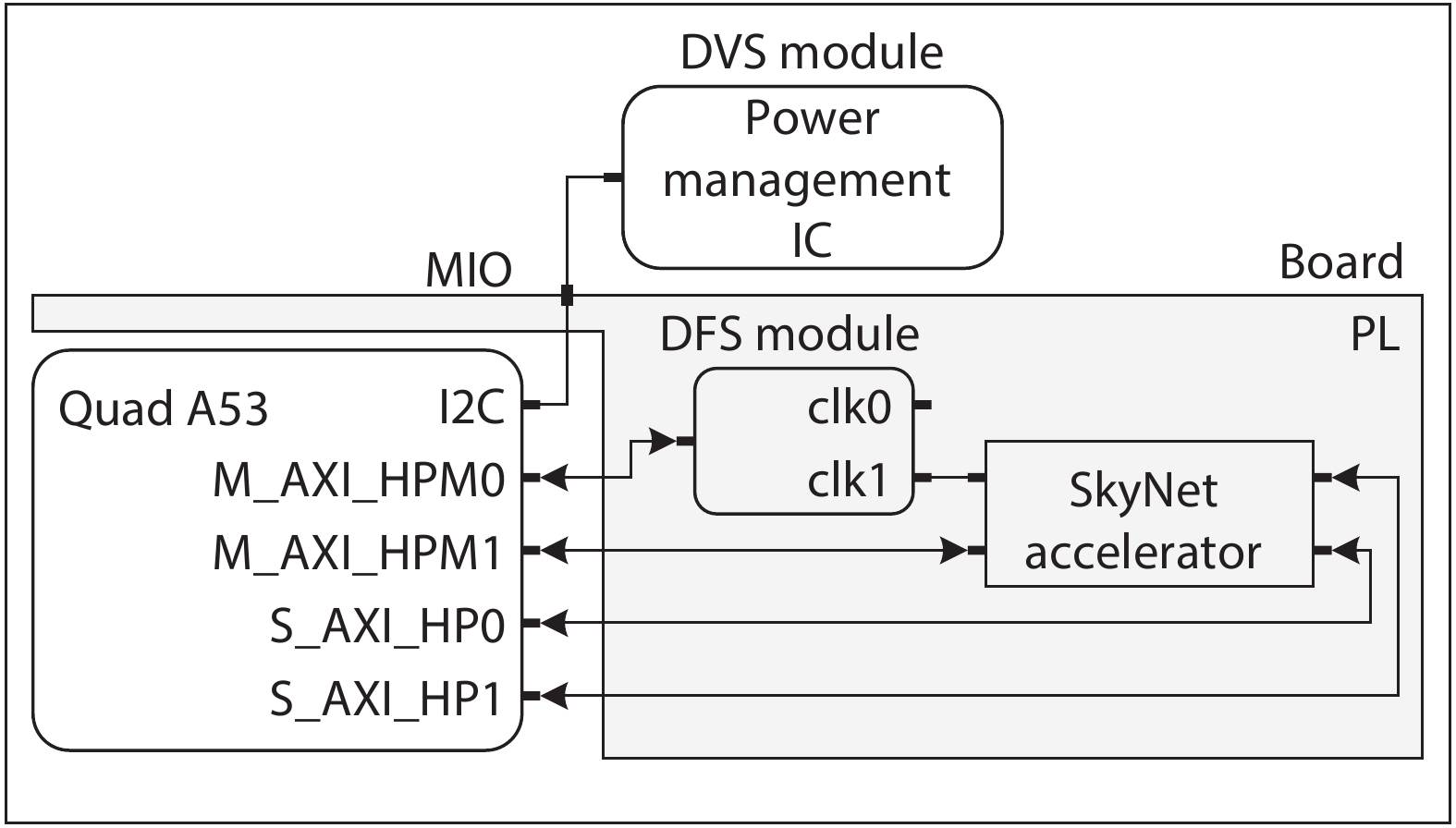
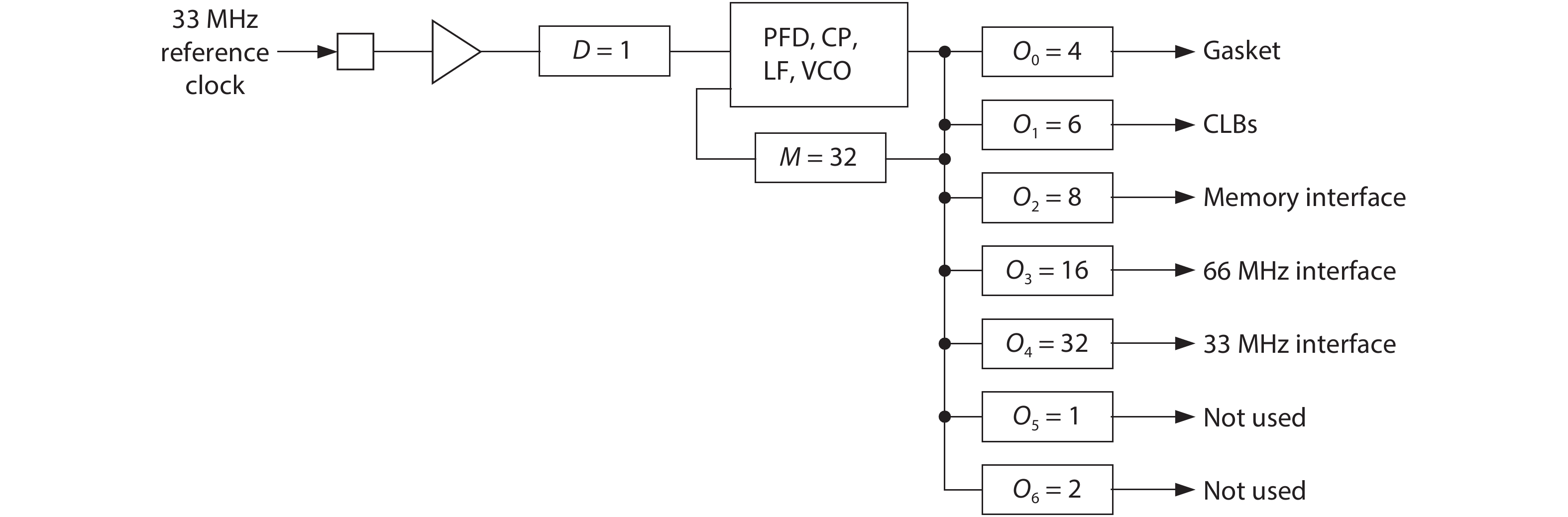
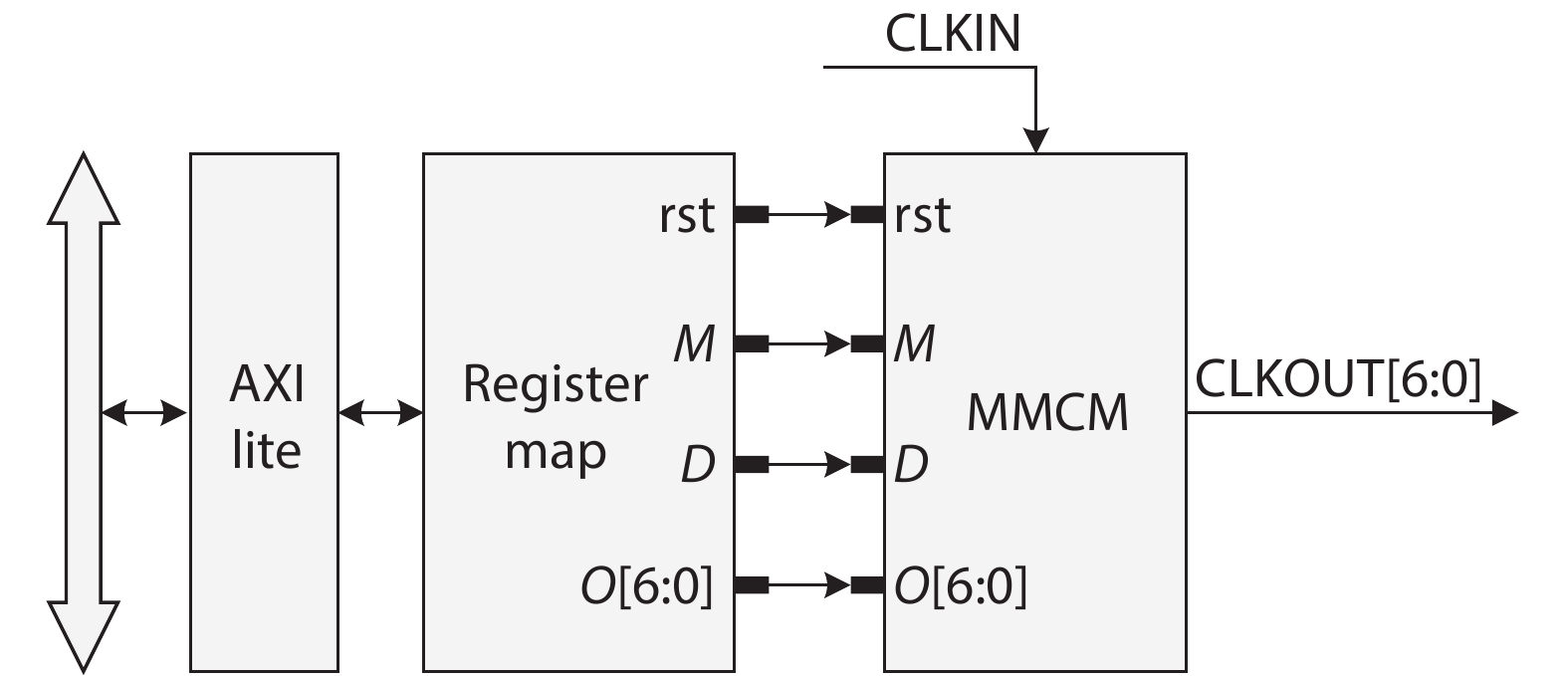
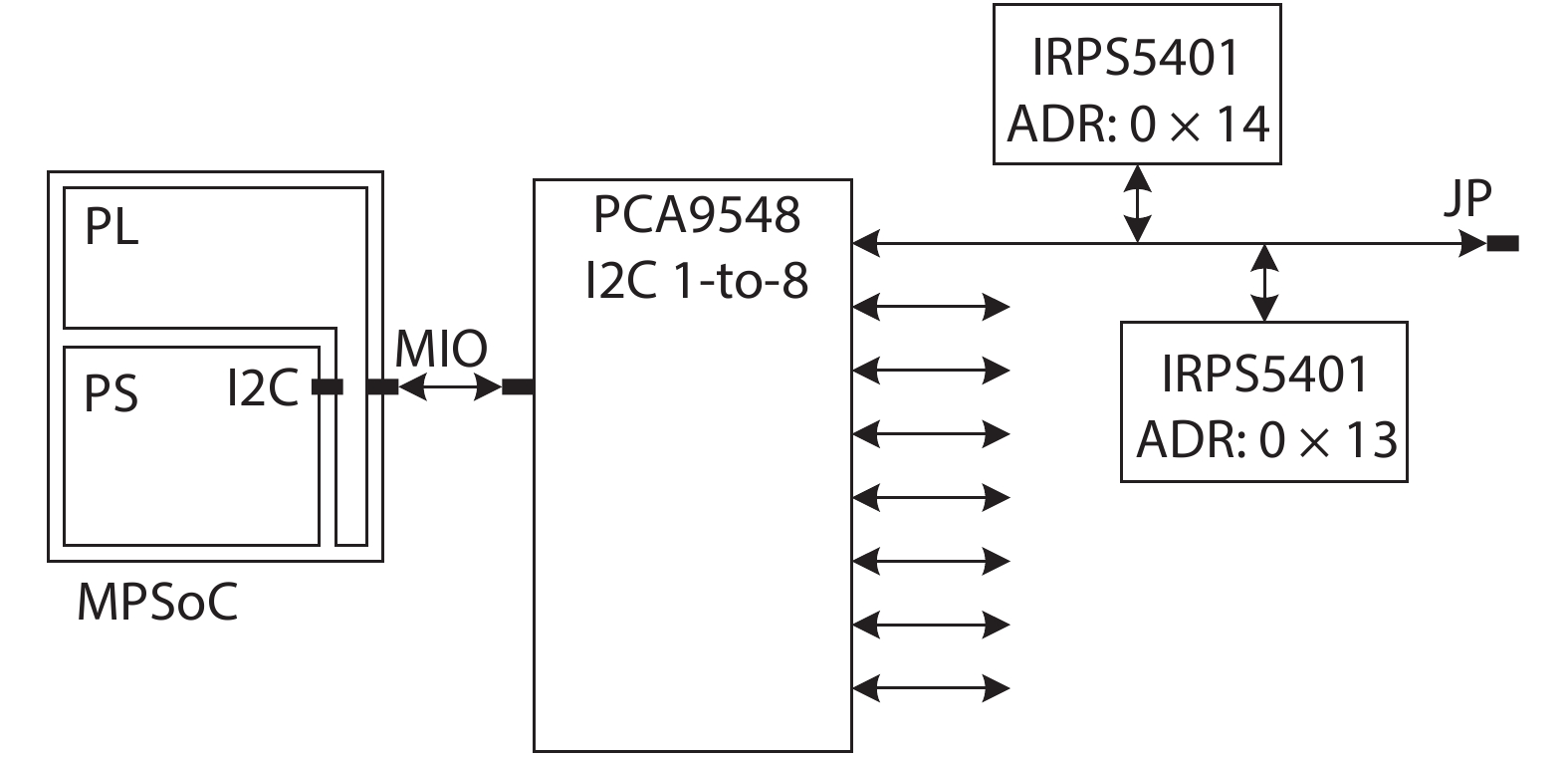
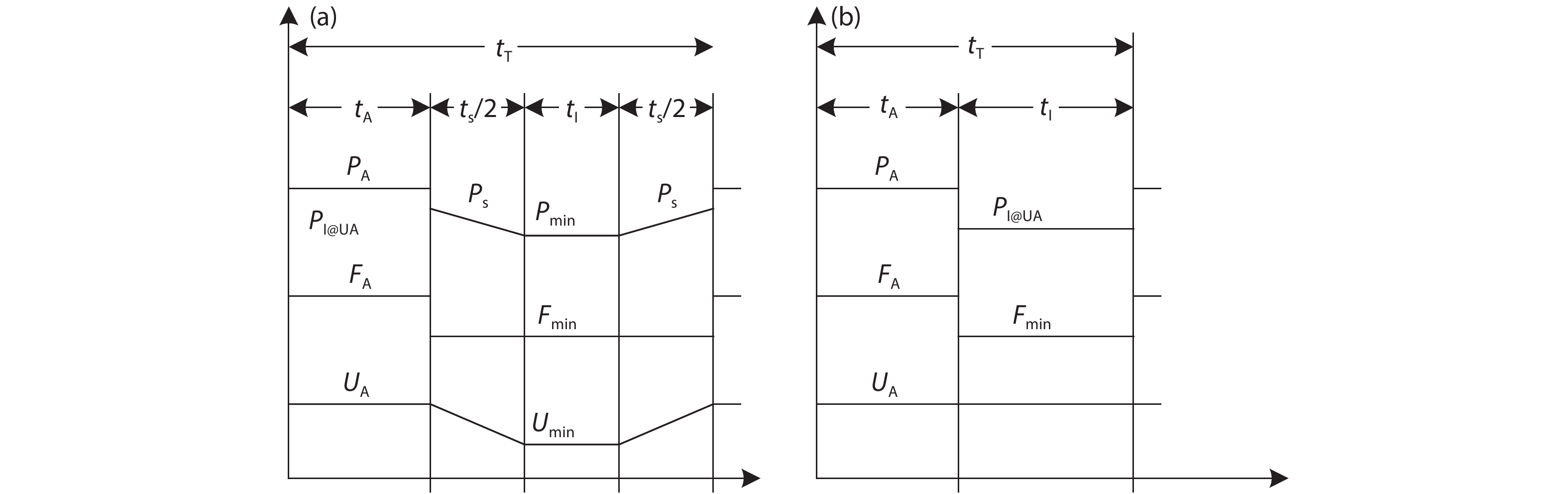
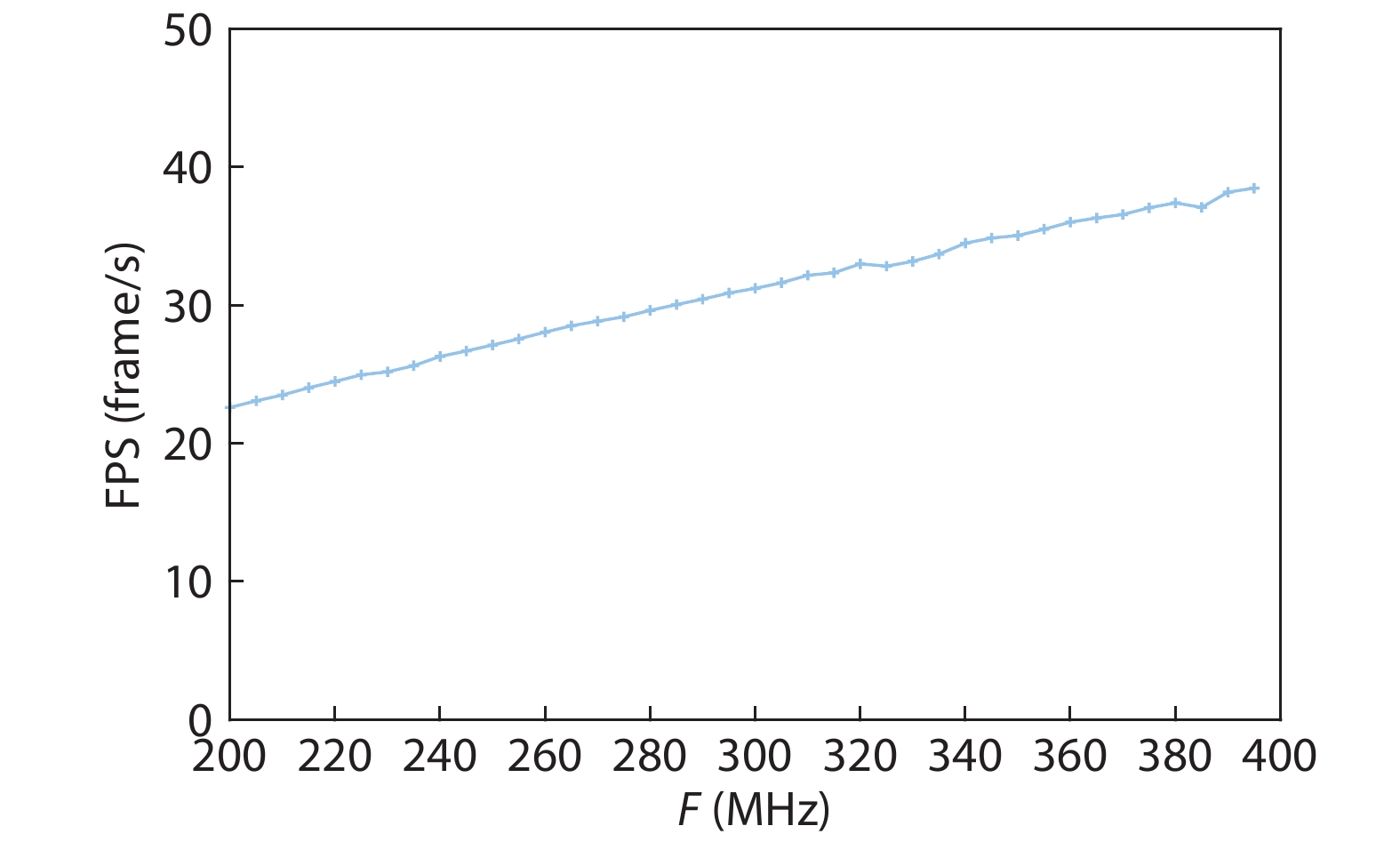
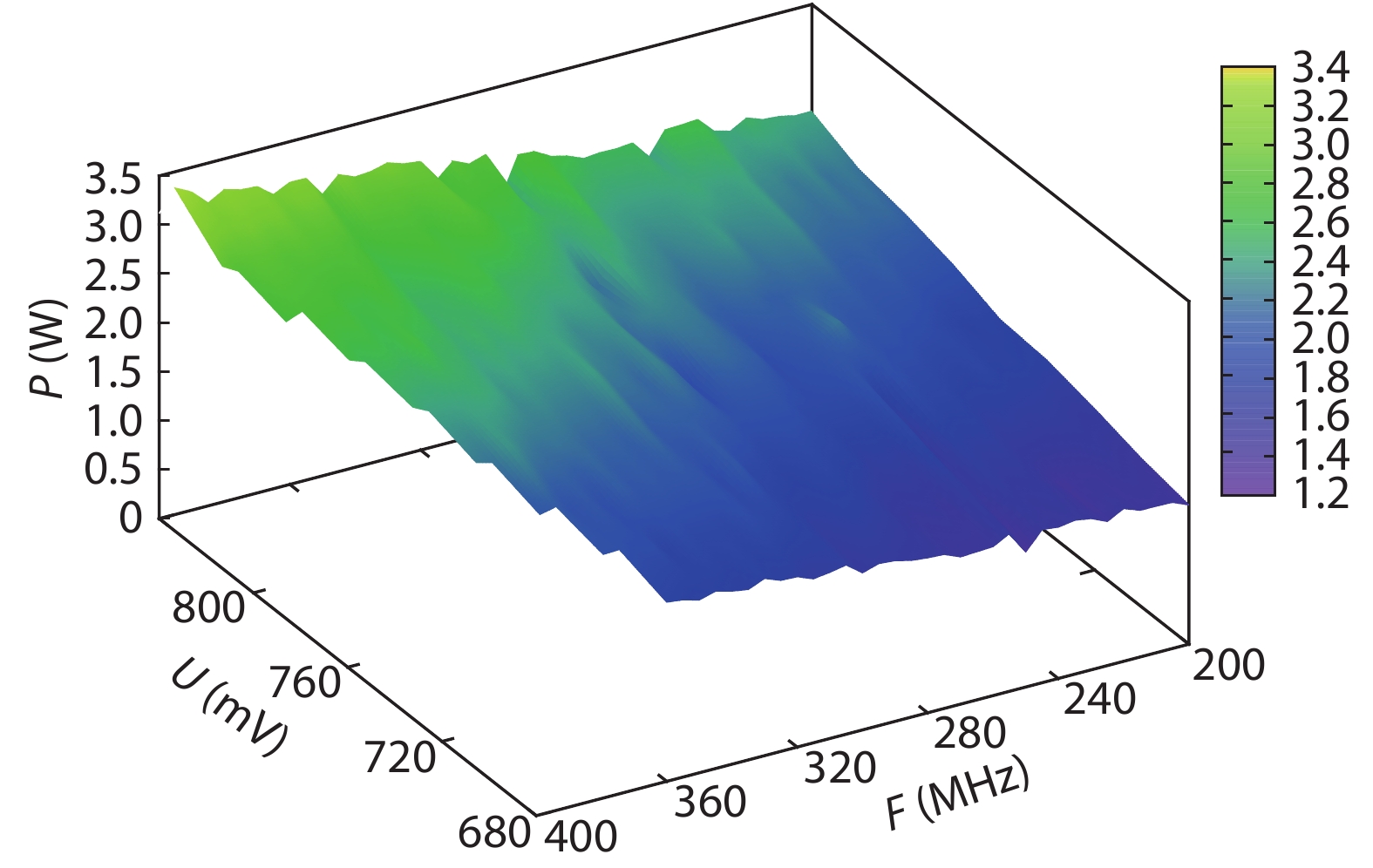
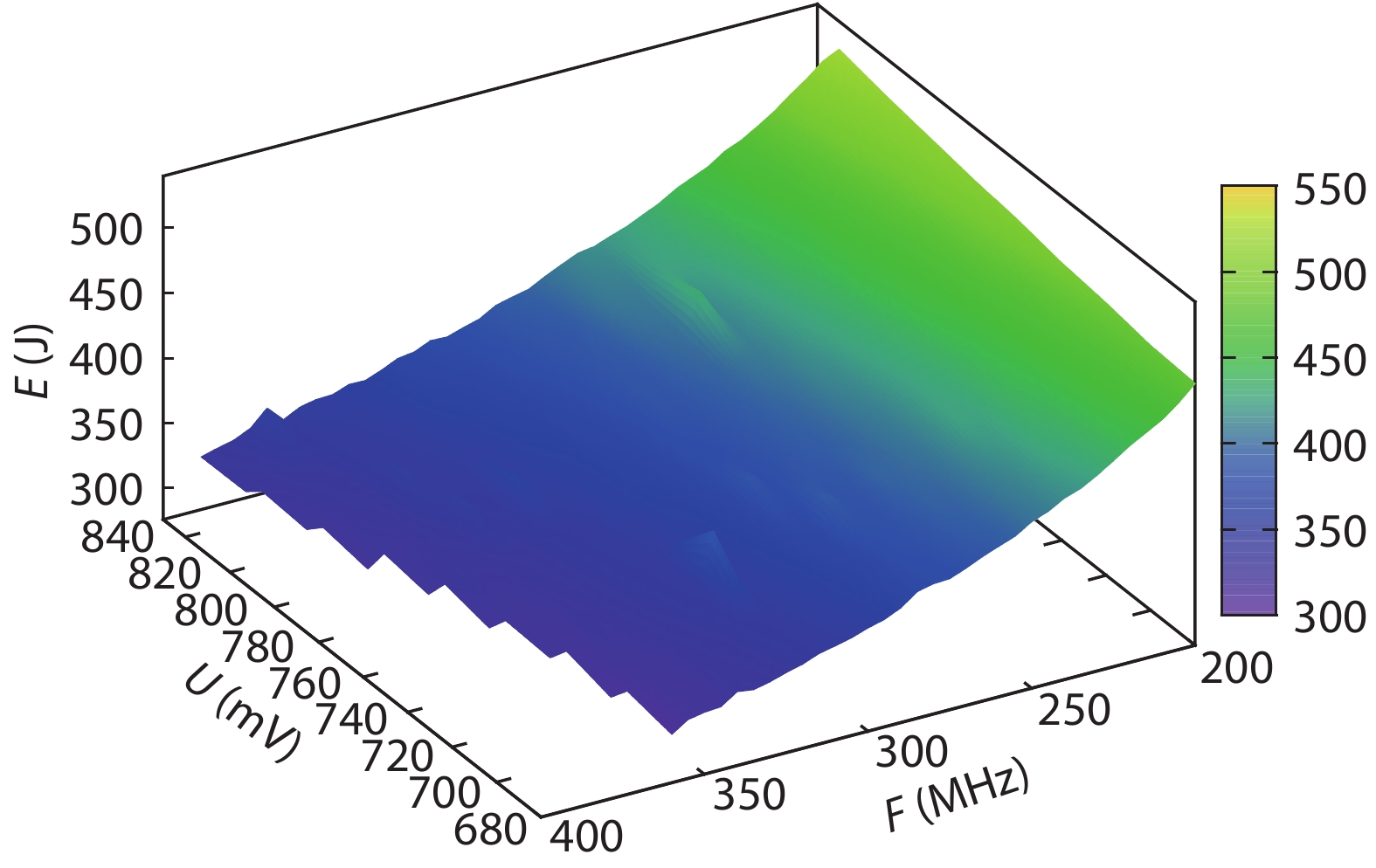
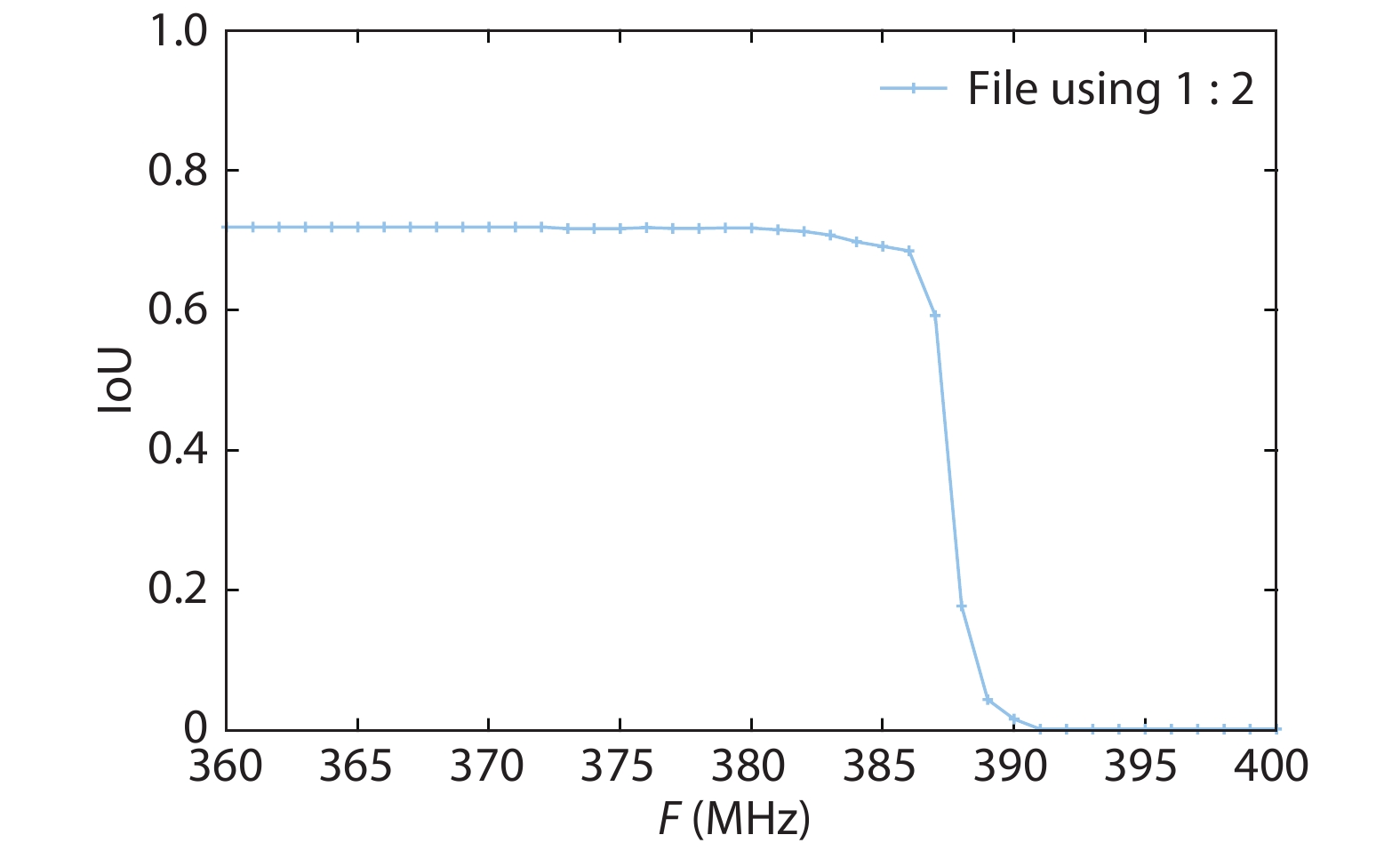
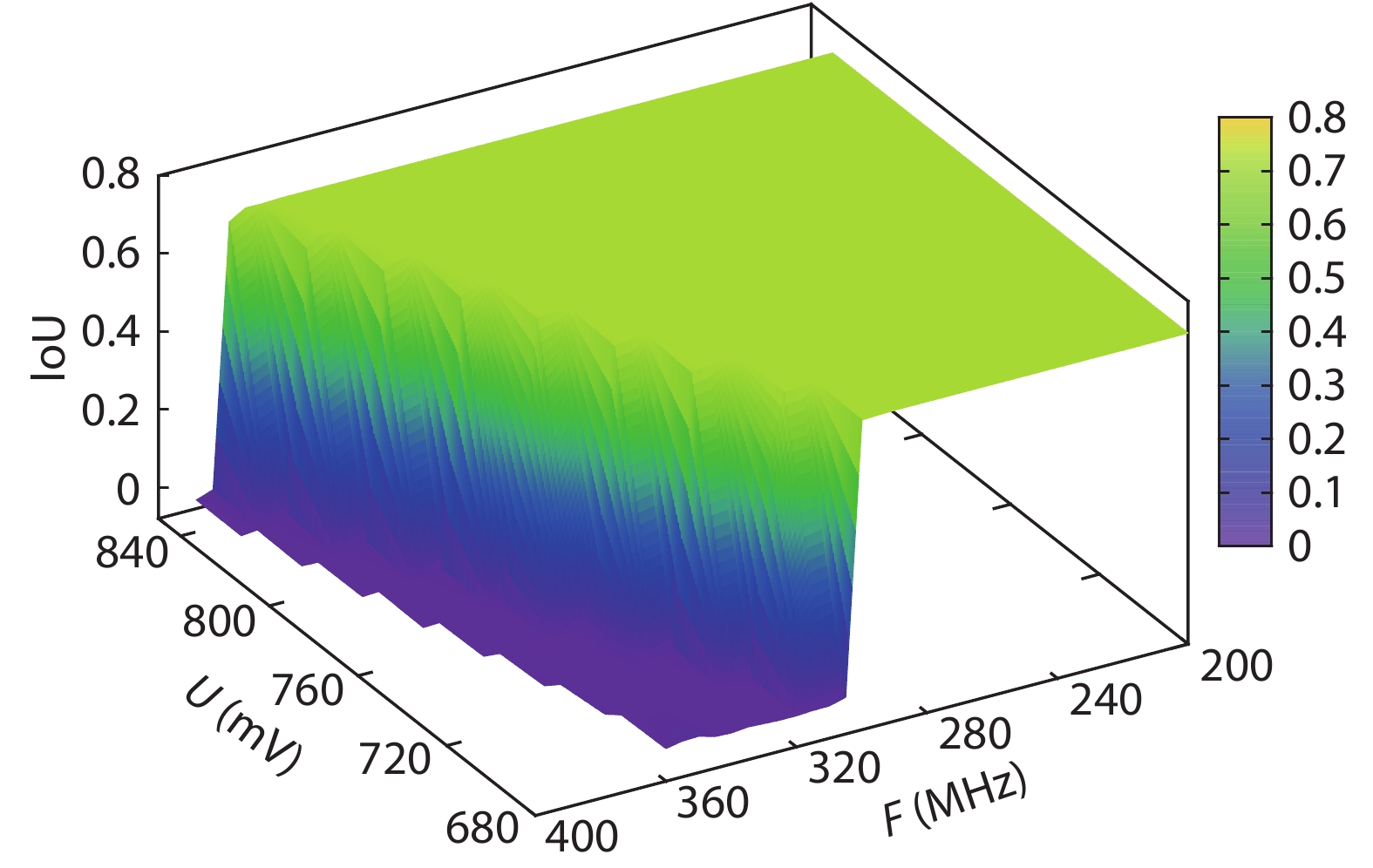
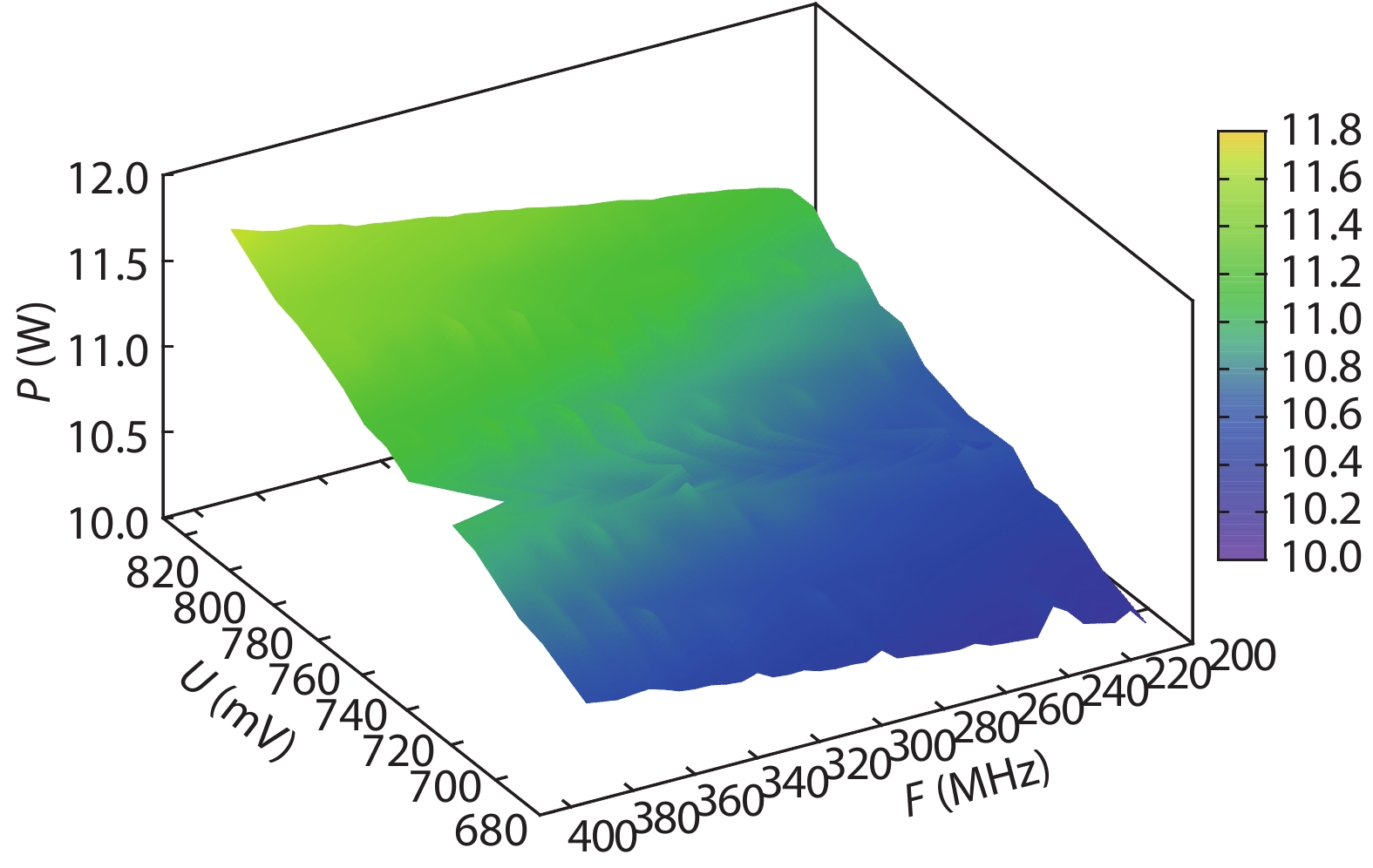
On the one hand, accelerating convolution neural networks (CNNs) on FPGAs requires ever increasing high energy efficiency in the edge computing paradigm. On the other hand, unlike normal digital algorithms, CNNs maintain their high robustness even with limited timing errors. By taking advantage of this unique feature, we propose to use dynamic voltage and frequency scaling (DVFS) to further optimize the energy efficiency for CNNs. First, we have developed a DVFS framework on FPGAs. Second, we apply the DVFS to SkyNet, a state-of-the-art neural network targeting on object detection. Third, we analyze the impact of DVFS on CNNs in terms of performance, power, energy efficiency and accuracy. Compared to the state-of-the-art, experimental results show that we have achieved 38% improvement in energy efficiency without any loss in accuracy. Results also show that we can achieve 47% improvement in energy efficiency if we allow 0.11% relaxation in accuracy.