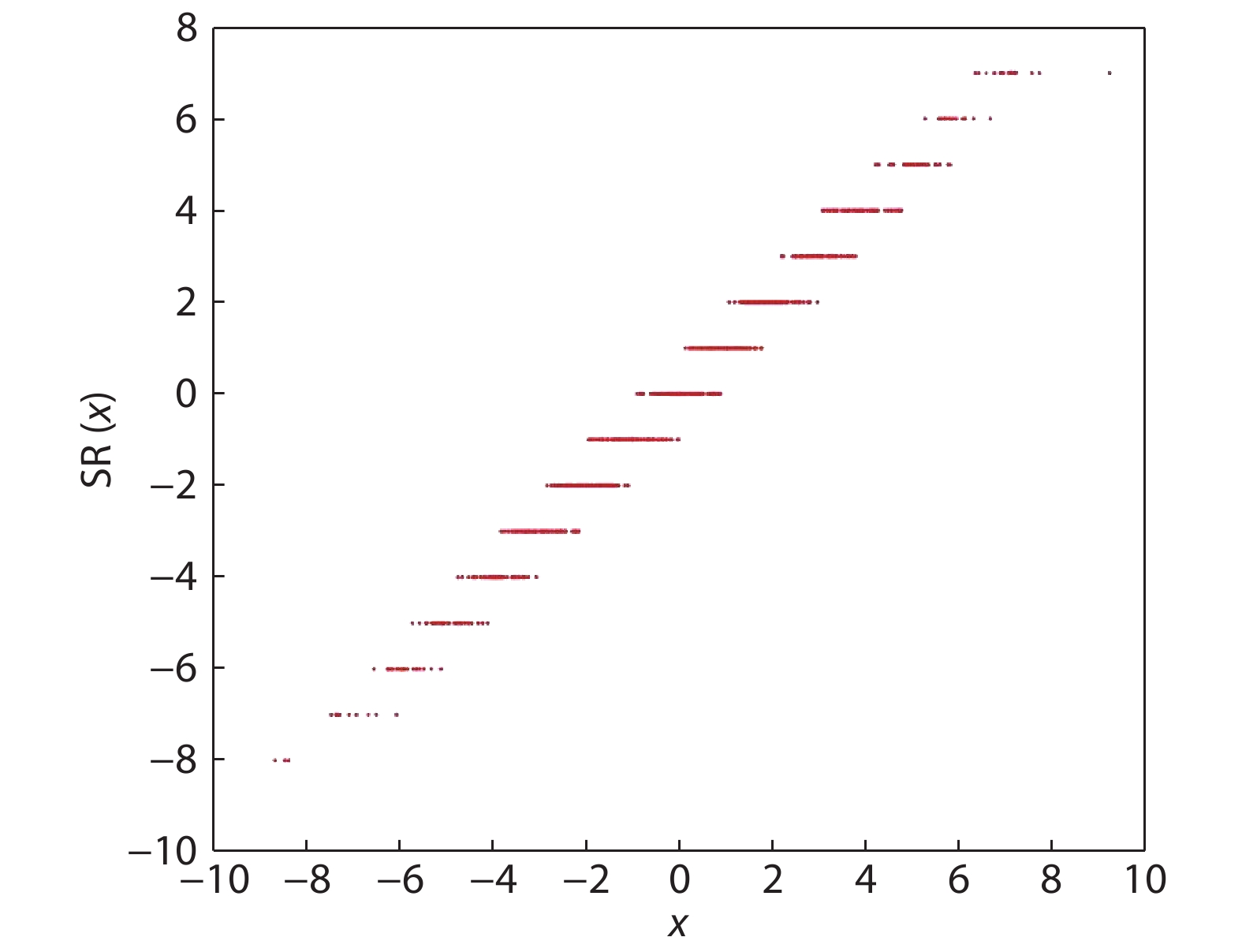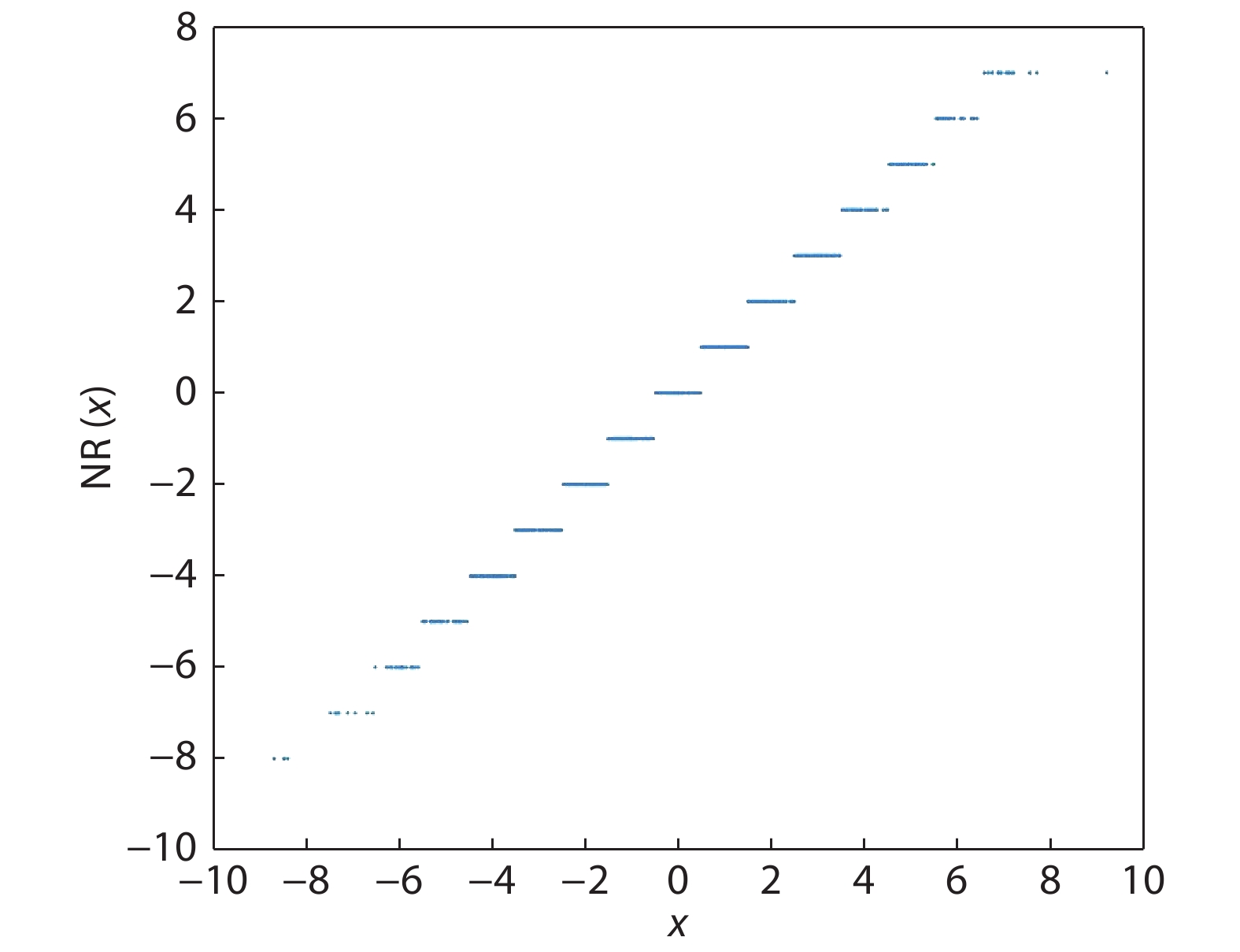
Fig. 1.
NR simulation.
ARTICLES
Chunyou Su1, ‡, Sheng Zhou2, ‡, Liang Feng1 and Wei Zhang1,
Corresponding author: Wei Zhang, Email: wei.zhang@ust.hk
Abstract: The high performance of the state-of-the-art deep neural networks (DNNs) is acquired at the cost of huge consumption of computing resources. Quantization of networks is recently recognized as a promising solution to solve the problem and significantly reduce the resource usage. However, the previous quantization works have mostly focused on the DNN inference, and there were very few works to address on the challenges of DNN training. In this paper, we leverage dynamic fixed-point (DFP) quantization algorithm and stochastic rounding (SR) strategy to develop a fully quantized 8-bit neural networks targeting low bitwidth training. The experiments show that, in comparison to the full-precision networks, the accuracy drop of our quantized convolutional neural networks (CNNs) can be less than 2%, even when applied to deep models evaluated on ImageNet dataset. Additionally, our 8-bit GNMT translation network can achieve almost identical BLEU to full-precision network. We further implement a prototype on FPGA and the synthesis shows that the low bitwidth training scheme can reduce the resource usage significantly.
Key words: CNN, quantized neural networks, limited precision training
| [1] |
Russakovsky O, Deng J, Su H, et al. Imagenet large scale visual recognition challenge. Int J Comput Vision, 2015, 115(3), 211 doi: 10.1007/s11263-015-0816-y
|
| [2] |
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks. Adv Neural Inform Process Syst, 2012, 1097
|
| [3] |
He K, Zhang X, Ren S, et al. Deep residual learning for image recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, 770
|
| [4] |
Han S, Pool J, Tran J, et al. Learning both weights and connections for efficient neural network. Adv Neural Inform Process Syst, 2015, 1135
|
| [5] |
Parashar A, Rhu M, Mukkara A, et al. Scnn: An accelerator for compressed-sparse convolutional neural networks. 2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA), 2017, 27
|
| [6] |
Han S, Liu X, Mao H, et al. EIE: efficient inference engine on compressed deep neural network. ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), 2016, 243
|
| [7] |
Li H, De S, Xu Z, et al. Training quantized nets: A deeper understanding. Adv Neural Inform Process Syst, 2017, 5811
|
| [8] |
Lu Z, Rallapalli S, Chan K, et al. Modeling the resource requirements of convolutional neural networks on mobile devices. Proceedings of the 25th ACM International Conference on Multimedia, 2017, 1663
|
| [9] |
Courbariaux M, Bengio Y, David J P. Training deep neural networks with low precision multiplications. arXiv preprint arXiv: 1412.7024, 2014
|
| [10] |
Nielsen M. How the backpropagation algorithm works. Retrieved from http://neuralnetworksanddeeplearning.com/chap2.html
|
| [11] |
Miyashita D, Lee E H, Murmann B. Convolutional neural networks using logarithmic data representation. arXiv preprint arXiv: 1603.01025, 2016
|
| [12] |
Cai Z, He X, Sun J, et al. Deep learning with low precision by half-wave gaussian quantization. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, 5918
|
| [13] |
Zhou S, Wu Y, Ni Z, et al. Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients. arXiv preprint arXiv: 1606.06160, 2016
|
| [14] |
Banner R, Hubara I, Hoffer E, et al. Scalable methods for 8-bit training of neural networks. Adv Neural Inform Process Syst, 2018, 5145
|
| [15] |
Hubara I, Courbariaux M, Soudry D, et al. Quantized neural networks: Training neural networks with low precision weights and activations. J Mach Learning Res, 2017, 18(1), 6869
|
| [16] |
Gupta S, Agrawal A, Gopalakrishnan K, et al. Deep learning with limited numerical precision. International Conference on Machine Learning, 2015, 1737
|
| [17] |
De Sa C, Feldman M, Ré C, et al. Understanding and optimizing asynchronous low-precision stochastic gradient descent. ACM SIGARCH Computer Architecture News, 2017, 45, 461
|
| [18] |
De Sa C, Leszczynski M, Zhang J, et al. High-accuracy low-precision training. arXiv preprint arXiv: 1803.03383, 2018
|
| [19] |
Chintala S, Gross S, Yeager L, et al. Alexnet. Retrieved from https://github.com/pytorch/vision/blob/master/torchvision/models/alexnet.py
|
| [20] |
Wu Y, Schuster M, Chen Z, et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv: 1609.08144, 2016
|
| [21] |
nvpstr. (2019, July 17). GNMT v2 for PyTorch. Retrieved from https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/Translation/GNMT
|
| [22] |
Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv: 1409.0473, 2014
|
| [23] |
Papineni K, Roukos S, Ward T, et al. BLEU: a method for automatic evaluation of machine translation. Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, 2002, 311
|
| [24] |
Courbariaux M, Bengio Y, David J P. Binaryconnect: Training deep neural networks with binary weights during propagations. Adv Neural Inform Process Syst, 2015, 3123
|
| [25] |
Hubara I, Courbariaux M, Soudry D, et al. Binarized neural networks. Adv Neural Inform Process Syst, 2016, 4107
|
| [26] |
Rastegari M, Ordonez V, Redmon J, et al. Xnor-net: Imagenet classification using binary convolutional neural networks. European Conference on Computer Vision, 2016, 525
|
| [27] |
Wu S, Li G, Chen F, et al. Training and inference with integers in deep neural networks. arXiv preprint arXiv: 1802.04680, 2018
|
| [28] |
Lin D D, Talathi S S. Overcoming challenges in fixed point training of deep convolutional networks. arXiv preprint arXiv: 1607.02241, 2016
|
Table 1. Top-1 accuracy of 8-bit AlexNet and ResNet18, SR versus NR.
| Model | 8-bit model (SR) | 8-bit model (NR) | Acc. Drop |
| AlexNet | 54.34% | 52.46% | 1.88% |
| ResNet-18 | 65.96% | 65.72% | 0.24% |
 DownLoad: CSV
DownLoad: CSV
Table 2. Top-1 accuracy on CIFAR-10 dataset.
| Model | Full | 8-bit model | Acc. Drop |
| ResNet-20 | 92.24% | 92.12% | 0.12% |
| ResNet-56 | 94.14% | 93.75% | 0.39% |
DownLoad: CSV
Table 3. Top-1 accuracy on ImageNet dataset.
| Model | Full | 8-bit model | Acc. Drop |
| AlexNet(DoReFa[14]) | 55.9% | 53.0% | 2.9% |
| AlexNet | 54.76% | 54.34% | 0.42% |
| ResNet-50 | 75.46% | 74.14% | 1.32% |
| Inception V3 | 76.95% | 75.03% | 1.92% |
DownLoad: CSV
Table 4. Resource usage of FPGA prototyping.
| Parameter | BRAM | DSP | FF | LUT |
| Used | 238 | 610 | 434213 | 564233 |
| Percentage | 5% | 8% | 18% | 47% |
DownLoad: CSV
| [1] |
Russakovsky O, Deng J, Su H, et al. Imagenet large scale visual recognition challenge. Int J Comput Vision, 2015, 115(3), 211 doi: 10.1007/s11263-015-0816-y
|
| [2] |
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks. Adv Neural Inform Process Syst, 2012, 1097
|
| [3] |
He K, Zhang X, Ren S, et al. Deep residual learning for image recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, 770
|
| [4] |
Han S, Pool J, Tran J, et al. Learning both weights and connections for efficient neural network. Adv Neural Inform Process Syst, 2015, 1135
|
| [5] |
Parashar A, Rhu M, Mukkara A, et al. Scnn: An accelerator for compressed-sparse convolutional neural networks. 2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA), 2017, 27
|
| [6] |
Han S, Liu X, Mao H, et al. EIE: efficient inference engine on compressed deep neural network. ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), 2016, 243
|
| [7] |
Li H, De S, Xu Z, et al. Training quantized nets: A deeper understanding. Adv Neural Inform Process Syst, 2017, 5811
|
| [8] |
Lu Z, Rallapalli S, Chan K, et al. Modeling the resource requirements of convolutional neural networks on mobile devices. Proceedings of the 25th ACM International Conference on Multimedia, 2017, 1663
|
| [9] |
Courbariaux M, Bengio Y, David J P. Training deep neural networks with low precision multiplications. arXiv preprint arXiv: 1412.7024, 2014
|
| [10] |
Nielsen M. How the backpropagation algorithm works. Retrieved from http://neuralnetworksanddeeplearning.com/chap2.html
|
| [11] |
Miyashita D, Lee E H, Murmann B. Convolutional neural networks using logarithmic data representation. arXiv preprint arXiv: 1603.01025, 2016
|
| [12] |
Cai Z, He X, Sun J, et al. Deep learning with low precision by half-wave gaussian quantization. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, 5918
|
| [13] |
Zhou S, Wu Y, Ni Z, et al. Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients. arXiv preprint arXiv: 1606.06160, 2016
|
| [14] |
Banner R, Hubara I, Hoffer E, et al. Scalable methods for 8-bit training of neural networks. Adv Neural Inform Process Syst, 2018, 5145
|
| [15] |
Hubara I, Courbariaux M, Soudry D, et al. Quantized neural networks: Training neural networks with low precision weights and activations. J Mach Learning Res, 2017, 18(1), 6869
|
| [16] |
Gupta S, Agrawal A, Gopalakrishnan K, et al. Deep learning with limited numerical precision. International Conference on Machine Learning, 2015, 1737
|
| [17] |
De Sa C, Feldman M, Ré C, et al. Understanding and optimizing asynchronous low-precision stochastic gradient descent. ACM SIGARCH Computer Architecture News, 2017, 45, 461
|
| [18] |
De Sa C, Leszczynski M, Zhang J, et al. High-accuracy low-precision training. arXiv preprint arXiv: 1803.03383, 2018
|
| [19] |
Chintala S, Gross S, Yeager L, et al. Alexnet. Retrieved from https://github.com/pytorch/vision/blob/master/torchvision/models/alexnet.py
|
| [20] |
Wu Y, Schuster M, Chen Z, et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv: 1609.08144, 2016
|
| [21] |
nvpstr. (2019, July 17). GNMT v2 for PyTorch. Retrieved from https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/Translation/GNMT
|
| [22] |
Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv: 1409.0473, 2014
|
| [23] |
Papineni K, Roukos S, Ward T, et al. BLEU: a method for automatic evaluation of machine translation. Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, 2002, 311
|
| [24] |
Courbariaux M, Bengio Y, David J P. Binaryconnect: Training deep neural networks with binary weights during propagations. Adv Neural Inform Process Syst, 2015, 3123
|
| [25] |
Hubara I, Courbariaux M, Soudry D, et al. Binarized neural networks. Adv Neural Inform Process Syst, 2016, 4107
|
| [26] |
Rastegari M, Ordonez V, Redmon J, et al. Xnor-net: Imagenet classification using binary convolutional neural networks. European Conference on Computer Vision, 2016, 525
|
| [27] |
Wu S, Li G, Chen F, et al. Training and inference with integers in deep neural networks. arXiv preprint arXiv: 1802.04680, 2018
|
| [28] |
Lin D D, Talathi S S. Overcoming challenges in fixed point training of deep convolutional networks. arXiv preprint arXiv: 1607.02241, 2016
|









Article views: 4581 Times PDF downloads: 123 Times Cited by: 0 Times
Received: 15 January 2020 Revised: Online: Accepted Manuscript: 21 January 2020Uncorrected proof: 21 January 2020Published: 11 February 2020
| Citation: |
Chunyou Su, Sheng Zhou, Liang Feng, Wei Zhang. Towards high performance low bitwidth training for deep neural networks[J]. Journal of Semiconductors, 2020, 41(2): 022404. doi: 10.1088/1674-4926/41/2/022404
****
C Y Su, S Zhou, L Feng, W Zhang, Towards high performance low bitwidth training for deep neural networks[J]. J. Semicond., 2020, 41(2): 022404. doi: 10.1088/1674-4926/41/2/022404.

|
| [1] |
Russakovsky O, Deng J, Su H, et al. Imagenet large scale visual recognition challenge. Int J Comput Vision, 2015, 115(3), 211 doi: 10.1007/s11263-015-0816-y
|
| [2] |
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks. Adv Neural Inform Process Syst, 2012, 1097
|
| [3] |
He K, Zhang X, Ren S, et al. Deep residual learning for image recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, 770
|
| [4] |
Han S, Pool J, Tran J, et al. Learning both weights and connections for efficient neural network. Adv Neural Inform Process Syst, 2015, 1135
|
| [5] |
Parashar A, Rhu M, Mukkara A, et al. Scnn: An accelerator for compressed-sparse convolutional neural networks. 2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA), 2017, 27
|
| [6] |
Han S, Liu X, Mao H, et al. EIE: efficient inference engine on compressed deep neural network. ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), 2016, 243
|
| [7] |
Li H, De S, Xu Z, et al. Training quantized nets: A deeper understanding. Adv Neural Inform Process Syst, 2017, 5811
|
| [8] |
Lu Z, Rallapalli S, Chan K, et al. Modeling the resource requirements of convolutional neural networks on mobile devices. Proceedings of the 25th ACM International Conference on Multimedia, 2017, 1663
|
| [9] |
Courbariaux M, Bengio Y, David J P. Training deep neural networks with low precision multiplications. arXiv preprint arXiv: 1412.7024, 2014
|
| [10] |
Nielsen M. How the backpropagation algorithm works. Retrieved from http://neuralnetworksanddeeplearning.com/chap2.html
|
| [11] |
Miyashita D, Lee E H, Murmann B. Convolutional neural networks using logarithmic data representation. arXiv preprint arXiv: 1603.01025, 2016
|
| [12] |
Cai Z, He X, Sun J, et al. Deep learning with low precision by half-wave gaussian quantization. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, 5918
|
| [13] |
Zhou S, Wu Y, Ni Z, et al. Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients. arXiv preprint arXiv: 1606.06160, 2016
|
| [14] |
Banner R, Hubara I, Hoffer E, et al. Scalable methods for 8-bit training of neural networks. Adv Neural Inform Process Syst, 2018, 5145
|
| [15] |
Hubara I, Courbariaux M, Soudry D, et al. Quantized neural networks: Training neural networks with low precision weights and activations. J Mach Learning Res, 2017, 18(1), 6869
|
| [16] |
Gupta S, Agrawal A, Gopalakrishnan K, et al. Deep learning with limited numerical precision. International Conference on Machine Learning, 2015, 1737
|
| [17] |
De Sa C, Feldman M, Ré C, et al. Understanding and optimizing asynchronous low-precision stochastic gradient descent. ACM SIGARCH Computer Architecture News, 2017, 45, 461
|
| [18] |
De Sa C, Leszczynski M, Zhang J, et al. High-accuracy low-precision training. arXiv preprint arXiv: 1803.03383, 2018
|
| [19] |
Chintala S, Gross S, Yeager L, et al. Alexnet. Retrieved from https://github.com/pytorch/vision/blob/master/torchvision/models/alexnet.py
|
| [20] |
Wu Y, Schuster M, Chen Z, et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv: 1609.08144, 2016
|
| [21] |
nvpstr. (2019, July 17). GNMT v2 for PyTorch. Retrieved from https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/Translation/GNMT
|
| [22] |
Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv: 1409.0473, 2014
|
| [23] |
Papineni K, Roukos S, Ward T, et al. BLEU: a method for automatic evaluation of machine translation. Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, 2002, 311
|
| [24] |
Courbariaux M, Bengio Y, David J P. Binaryconnect: Training deep neural networks with binary weights during propagations. Adv Neural Inform Process Syst, 2015, 3123
|
| [25] |
Hubara I, Courbariaux M, Soudry D, et al. Binarized neural networks. Adv Neural Inform Process Syst, 2016, 4107
|
| [26] |
Rastegari M, Ordonez V, Redmon J, et al. Xnor-net: Imagenet classification using binary convolutional neural networks. European Conference on Computer Vision, 2016, 525
|
| [27] |
Wu S, Li G, Chen F, et al. Training and inference with integers in deep neural networks. arXiv preprint arXiv: 1802.04680, 2018
|
| [28] |
Lin D D, Talathi S S. Overcoming challenges in fixed point training of deep convolutional networks. arXiv preprint arXiv: 1607.02241, 2016
|

 WeChat ID
WeChat ID
Journal of Semiconductors © 2017 All Rights Reserved 京ICP备05085259号-2