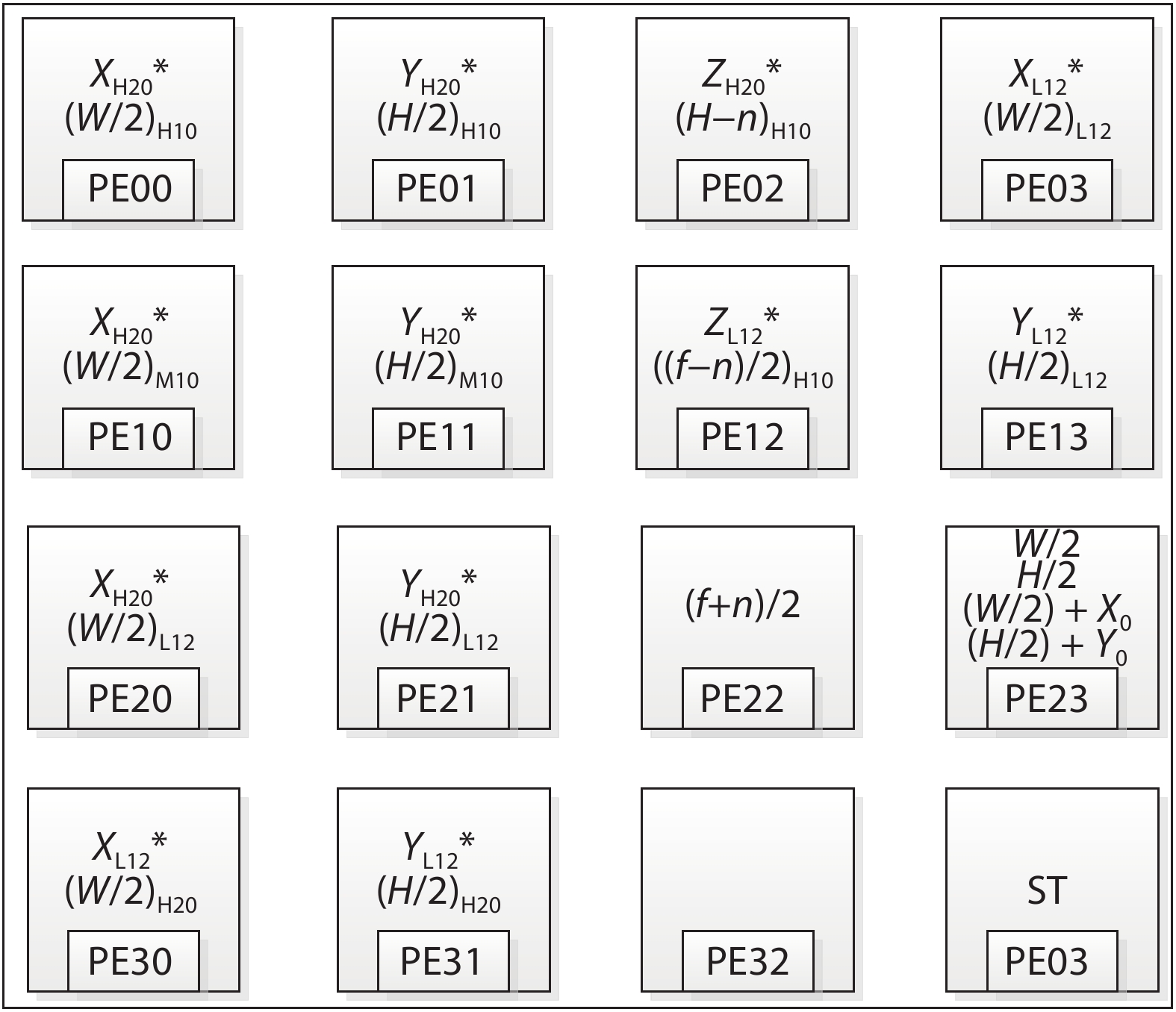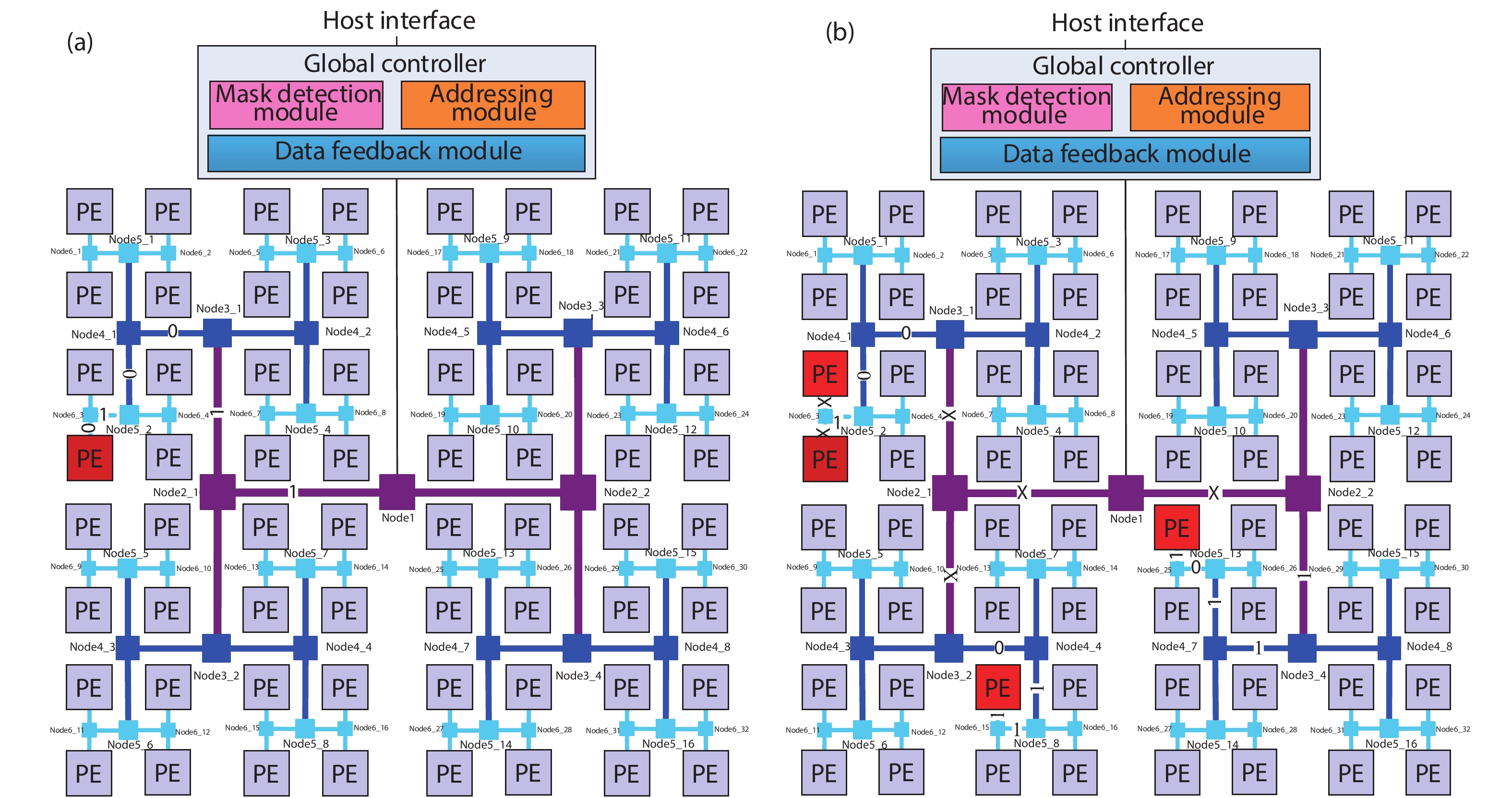
Fig. 1.
(Color online) The topology of HRM. (a) Unicast. (b) Multicast/broadcast.
ARTICLES
Junyong Deng1, Lin Jiang2, , Yun Zhu1, Xiaoyan Xie3, Xinchuang Liu1, Feilong He3, Shuang Song4 and L. K. John4
Corresponding author: Lin Jiang, Email: jianglin@xust.edu.cn
Abstract: In order to accommodate the variety of algorithms with different performance in specific application and improve power efficiency, reconfigurable architecture has become an effective methodology in academia and industry. However, existing architectures suffer from performance bottleneck due to slow updating of contexts and inadequate flexibility. This paper presents an H-tree based reconfiguration mechanism (HRM) with Huffman-coding-like and mask addressing method in a homogeneous processing element (PE) array, which supports both programmable and data-driven modes. The proposed HRM can transfer reconfiguration instructions/contexts to a particular PE or associated PEs simultaneously in one clock cycle in unicast, multicast and broadcast mode, and shut down the unnecessary PE/PEs according to the current configuration. To verify the correctness and efficiency, we implement it in RTL synthesis and FPGA prototype. Compared to prior works, the experiment results show that the HRM has improved the work frequency by an average of 23.4%, increased the updating speed by 2×, and reduced the area by 36.9%; HRM can also power off the unnecessary PEs which reduced 51% of dynamic power dissipation in certain application configuration. Furthermore, in the data-driven mode, the system frequency can reach 214 MHz, which is 1.68× higher compared with the programmable mode.
Keywords: H-tree based reconfiguration mechanism (HRM), Huffman-coding-like addressing, programmable mode, data-driven mode, homogeneous PE array
| [1] |
Yun Z, Jiang L, Wang S, et al. Design of reconfigurable array processor for multimedia application. Multimed Tools Appl, 2018, 77(3), 3639 doi: 10.1007/s11042-017-5284-7
|
| [2] |
Shi X, Luo X, Liang J, et al. Frog: Asynchronous graph processing on GPU with hybrid coloring model. IEEE Trans Knowl Data Eng, 2017, 30(1), 29 doi: 10.1109/TKDE.2017.2745562
|
| [3] |
Wang Y, Davidson A, Pan Y, et al. Gunrock: A high-performance graph processing library on the GPU. ACM SIGPLAN Notices, 2016, 51(8), 11
|
| [4] |
Cao S, Zhang C, Yao Z, et al. Efficient and effective sparse LSTM on FPGA with bank-balanced sparsity. Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2019, 63
|
| [5] |
Wu E, Zhang X, Berman D, et al. Compute-efficient neural-network acceleration. Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2019, 191
|
| [6] |
Tian R J, Jiang L, Deng J Y, et al. Design and implementation of reconfigurable viewport transformation unit in embedded GPU. Mini-Micro Syst, 2018, 39(05), 1074
|
| [7] |
Vestias M P. High-performance reconfigurable computing. In: Advanced Methodologies and Technologies in Network Architecture, Mobile Computing, and Data Analytics. IGI Global, 2019, 731
|
| [8] |
Yao P, Zheng L, Liao X, et al. An efficient graph accelerator with parallel data conflict management. Proceedings of the 27th International Conference on Parallel Architectures and Compilation Techniques, 2018, 8
|
| [9] |
Yang C, Wang Y, Wang X, et al. WRA: A 2.2-to-6.3 TOPS highly unified dynamically reconfigurable accelerator using a novel Winograd decomposition algorithm for convolutional neural networks. IEEE Trans Circuits Syst I, 2019, 66(9), 3480 doi: 10.1109/TCSI.2019.2928682
|
| [10] |
Liu L, Li Z, Yang C, et al. Hrea: An energy-efficient embedded dynamically reconfigurable fabric for 13-dwarfs processing. IEEE Trans Circuits Syst II, 2017, 65(3), 381 doi: 10.1109/TCSII.2017.2728814
|
| [11] |
Jafri S M A H, Daneshtalab M, Abbas N, et al. Transmap: Transformation based remapping and parallelism for high utilization and energy efficiency in CGRAs. IEEE Trans Comput, 2016, 65(11), 3456 doi: 10.1109/TC.2016.2525981
|
| [12] |
Karunaratne M, Mohite A K, Mitra T, et al. Hycube: A CGRA with reconfigurable single-cycle multi-hop interconnect. 2017 54th ACM/EDAC/IEEE Design Automation Conference (DAC), 2017, 1
|
| [13] |
Kim Y, Joo H, Yoon S. Inter-coarse-grained reconfigurable architecture reconfiguration technique for efficient pipelining of kernel-stream on coarse-grained reconfigurable architecture-based multi-core architecture. IET Circuits, Devices Syst, 2016, 10(4), 251 doi: 10.1049/iet-cds.2015.0047
|
| [14] |
Tajammul M A, Jafri S M A H, Hemani A, et al. Private configuration environments (PCE) for efficient reconfiguration, in CGRAs. 2013 IEEE 24th International Conference on Application-Specific Systems, Architectures and Processors, 2013, 227
|
| [15] |
Jiang L, Deng J Y, Song S, et al. HRM: H-tree based reconfiguration mechanism in homogeneous PE array for video processing. Poster in the 55th Annual Design Automation Conference (DAC’18), 2018
|
| [16] |
Huang J, Raabe A, Buckl C, et al. A workflow for runtime adaptive task allocation on heterogeneous mpsocs. 2011 Design, Automation & Test in Europe, 2011, 1
|
| [17] |
Jafri S M A H, Tajammul M A, Hemani A, et al. Energy-aware-task-parallelism for efficient dynamic voltage, and frequency scaling, in CGRAs. 2013 International Conference on Embedded Computer Systems: Architectures, Modeling, and Simulation (SAMOS), 2013, 104
|
| [18] |
Kirischian L. Reconfigurable computing systems engineering: virtualization of computing architecture. CRC Press, 2017
|
| [19] |
Wei S J, Liu L B, Yin S Y. Reconfigurable computing. Science Press, 2014 (in Chinese)
|
| [20] |
Wang Y S, Liu L B, Yin S Y, et al. Hierarchical representation of on-chip context to reduce reconfiguration time and implementation area for coarse-grained reconfigurable architecture. Sci Chin Inform Sci, 2013, 56(11), 1
|
| [21] |
Kim Y, Mahapatra R N. Dynamic context compression for low-power coarse-grained reconfigurable architecture. IEEE Trans Very Large Scale Integr Syst, 2009, 18(1), 15 doi: 10.1109/TVLSI.2008.2006846
|
| [22] |
Venkat A, Tullsen D M. Harnessing ISA diversity: Design of a heterogeneous-ISA chip multiprocessor. ACM SIGARCH Comput Architect News, 2014, 42(3), 121 doi: 10.1145/2678373.2665692
|
| [23] |
Hu C. Why FinFET and what next. Keynote in Shanghai Tech Workshop on Emerging Devices, Circuits and Systems, 2016
|
| [24] |
Deng J Y, Li T, Jiang L, et al. Design and optimization for multiprocessor interactive GPU. The Journal of China Universities of Posts and Telecommunications, 2014, 21(3), 85 doi: 10.1016/S1005-8885(14)60305-8
|
| [25] |
Deng J Y, Li T, Jiang L, et al. Design and implementation of the graphics accelerator oriented to OpenGL. Journal of Xidian University, 2015, 42(6), 124
|
| [26] |
Deng J Y, Li T, Jiang L, et al. The design of multiprocessor interactive GPU MIGPU-9. J Comput Aid Des Comput Graph, 2014, 26(9), 1468
|
| [27] |
Shen X B, Liu Z X, Wang R, et al. The unified model of computer architectures. Chin J Computs, 2007, 30(5), 729
|
| [28] |
Black D C, Donovan J, Bunton B, et al. SystemC: From the ground up. Springer Science & Business Media, 2009
|
| [29] |
Eng L Z. Qt5 C++GUI programming cookbook. Packt Publishing Ltd, 2016
|
| [30] |
Zhang X T, Jiang L, Deng J Y, et al. Design and Implementation of global controller in reconfigurable video array processor. Microelectron Comput, 2017, 34(11), 75
|

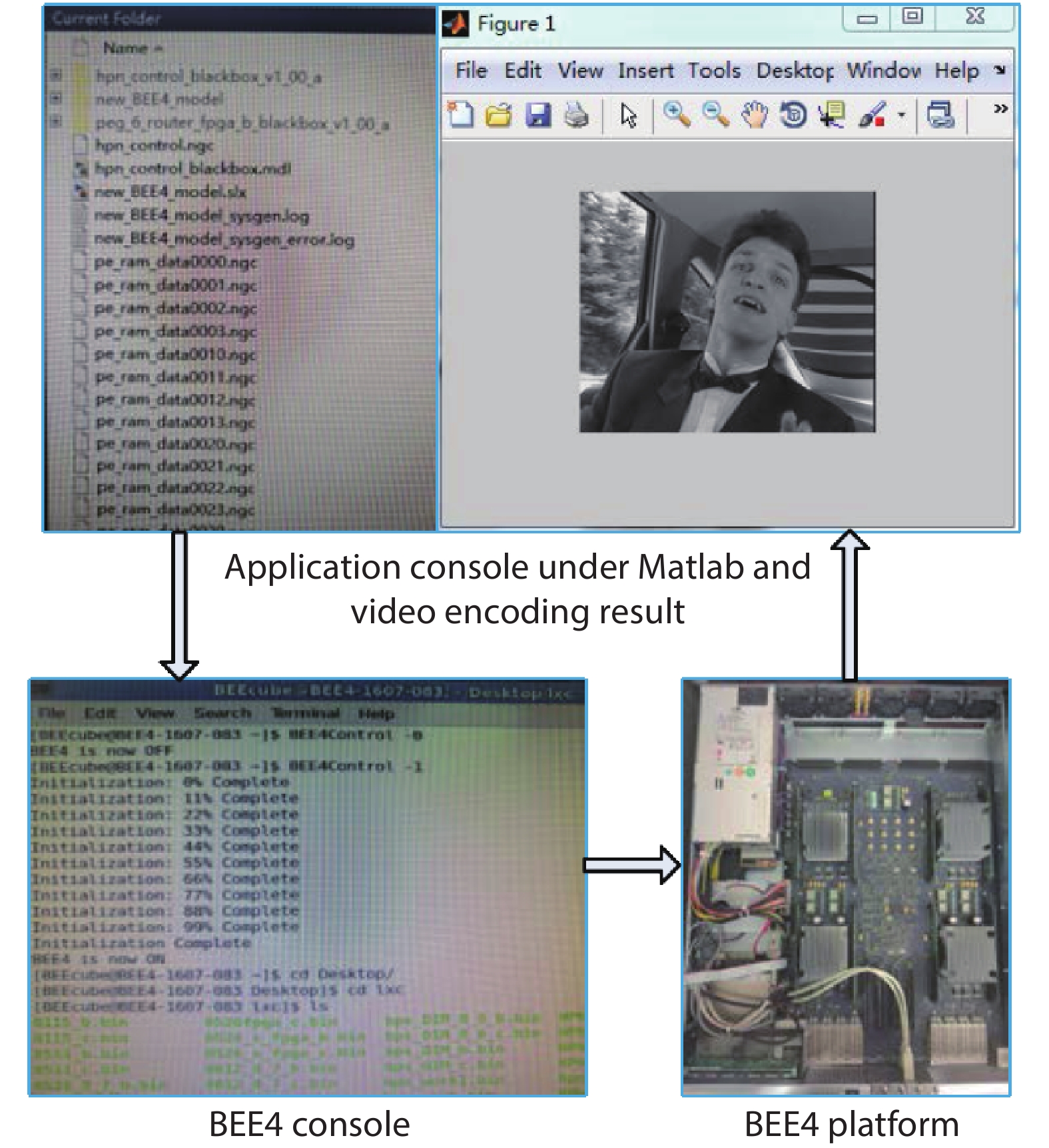


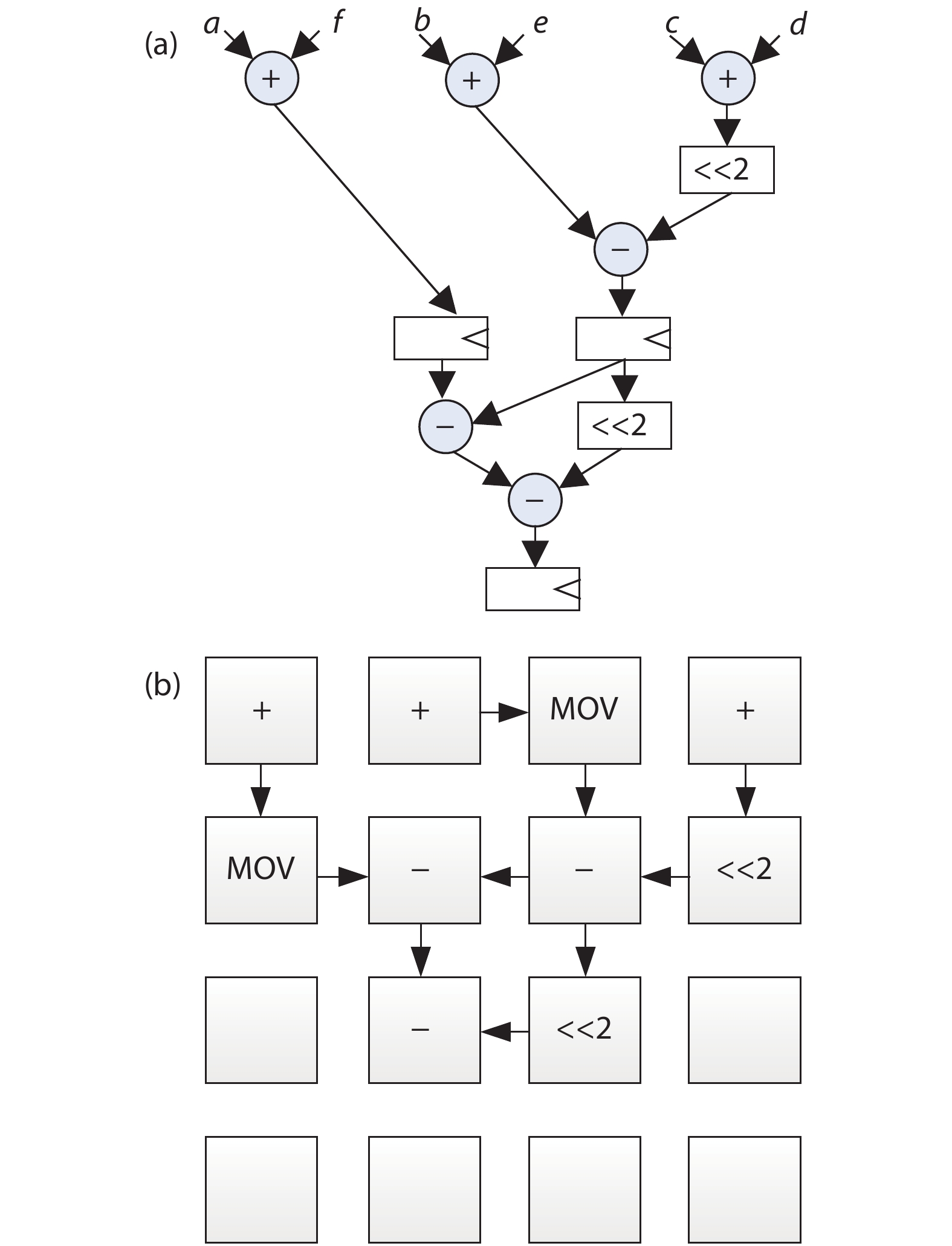
Table 1. PE cluster RTL implementation.
| Component | Parameter | This paper | RSF |
| PE | Bit-width of regs in a PE | 16 | 16 |
| # of regs in a PE | 16 | 4 | |
| # of PEs | 16 | 16 | |
| CM(4 kB)/IM(1 kB) | Bit-width of a CM/IM | 32 | 32 |
| # of CMs/IMs | 16 | 16 | |
| CB(1.5 kB)/DRAM(512 B) | # of sets | 1 | 2 |
| # of banks in a set | 1 | 3 | |
| Bit-width of a bank | 16 | 32 |
 DownLoad: CSV
DownLoad: CSV
Table 2. The statistics of reconfiguration instructions.
| FU changing | PE | Operation instruction | Call instruction |
| DCT→Intra | 16→2 | 2856 | 8 |
| DB→Intra | 15→8 | 2087 | 9 |
| Intra→DB | 9→12 | 2584 | 8 |
| IME→DCT | 11→16 | 3136 | 7 |
| FME→IME | 2→11 | 39 | 16 |
| FME | 2 | 0 | 2 |
| MC | 5 | 0 | 5 |
DownLoad: CSV
Table 3. Synthesis results of PE cluster.
| Comparison aspect | PE cluster | HRM | |||
| This paper | RSF | HReA | Comparison | ||
| Process (nm) | 90 | 90 | 65 | — | 90 |
| Area (gate equivalent) | 4155696 | 6586491 | — | 36.9%↓ | 4331 |
| Critical delay (ns) | 2.80 | 3.74 | 3.57 | 25.1%↓, 21.6%↓ | 2.02 |
| Power (mW) | 1.96 | 0.8 | — | 145%↑ | 0.48 |
DownLoad: CSV
| [1] |
Yun Z, Jiang L, Wang S, et al. Design of reconfigurable array processor for multimedia application. Multimed Tools Appl, 2018, 77(3), 3639 doi: 10.1007/s11042-017-5284-7
|
| [2] |
Shi X, Luo X, Liang J, et al. Frog: Asynchronous graph processing on GPU with hybrid coloring model. IEEE Trans Knowl Data Eng, 2017, 30(1), 29 doi: 10.1109/TKDE.2017.2745562
|
| [3] |
Wang Y, Davidson A, Pan Y, et al. Gunrock: A high-performance graph processing library on the GPU. ACM SIGPLAN Notices, 2016, 51(8), 11
|
| [4] |
Cao S, Zhang C, Yao Z, et al. Efficient and effective sparse LSTM on FPGA with bank-balanced sparsity. Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2019, 63
|
| [5] |
Wu E, Zhang X, Berman D, et al. Compute-efficient neural-network acceleration. Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2019, 191
|
| [6] |
Tian R J, Jiang L, Deng J Y, et al. Design and implementation of reconfigurable viewport transformation unit in embedded GPU. Mini-Micro Syst, 2018, 39(05), 1074
|
| [7] |
Vestias M P. High-performance reconfigurable computing. In: Advanced Methodologies and Technologies in Network Architecture, Mobile Computing, and Data Analytics. IGI Global, 2019, 731
|
| [8] |
Yao P, Zheng L, Liao X, et al. An efficient graph accelerator with parallel data conflict management. Proceedings of the 27th International Conference on Parallel Architectures and Compilation Techniques, 2018, 8
|
| [9] |
Yang C, Wang Y, Wang X, et al. WRA: A 2.2-to-6.3 TOPS highly unified dynamically reconfigurable accelerator using a novel Winograd decomposition algorithm for convolutional neural networks. IEEE Trans Circuits Syst I, 2019, 66(9), 3480 doi: 10.1109/TCSI.2019.2928682
|
| [10] |
Liu L, Li Z, Yang C, et al. Hrea: An energy-efficient embedded dynamically reconfigurable fabric for 13-dwarfs processing. IEEE Trans Circuits Syst II, 2017, 65(3), 381 doi: 10.1109/TCSII.2017.2728814
|
| [11] |
Jafri S M A H, Daneshtalab M, Abbas N, et al. Transmap: Transformation based remapping and parallelism for high utilization and energy efficiency in CGRAs. IEEE Trans Comput, 2016, 65(11), 3456 doi: 10.1109/TC.2016.2525981
|
| [12] |
Karunaratne M, Mohite A K, Mitra T, et al. Hycube: A CGRA with reconfigurable single-cycle multi-hop interconnect. 2017 54th ACM/EDAC/IEEE Design Automation Conference (DAC), 2017, 1
|
| [13] |
Kim Y, Joo H, Yoon S. Inter-coarse-grained reconfigurable architecture reconfiguration technique for efficient pipelining of kernel-stream on coarse-grained reconfigurable architecture-based multi-core architecture. IET Circuits, Devices Syst, 2016, 10(4), 251 doi: 10.1049/iet-cds.2015.0047
|
| [14] |
Tajammul M A, Jafri S M A H, Hemani A, et al. Private configuration environments (PCE) for efficient reconfiguration, in CGRAs. 2013 IEEE 24th International Conference on Application-Specific Systems, Architectures and Processors, 2013, 227
|
| [15] |
Jiang L, Deng J Y, Song S, et al. HRM: H-tree based reconfiguration mechanism in homogeneous PE array for video processing. Poster in the 55th Annual Design Automation Conference (DAC’18), 2018
|
| [16] |
Huang J, Raabe A, Buckl C, et al. A workflow for runtime adaptive task allocation on heterogeneous mpsocs. 2011 Design, Automation & Test in Europe, 2011, 1
|
| [17] |
Jafri S M A H, Tajammul M A, Hemani A, et al. Energy-aware-task-parallelism for efficient dynamic voltage, and frequency scaling, in CGRAs. 2013 International Conference on Embedded Computer Systems: Architectures, Modeling, and Simulation (SAMOS), 2013, 104
|
| [18] |
Kirischian L. Reconfigurable computing systems engineering: virtualization of computing architecture. CRC Press, 2017
|
| [19] |
Wei S J, Liu L B, Yin S Y. Reconfigurable computing. Science Press, 2014 (in Chinese)
|
| [20] |
Wang Y S, Liu L B, Yin S Y, et al. Hierarchical representation of on-chip context to reduce reconfiguration time and implementation area for coarse-grained reconfigurable architecture. Sci Chin Inform Sci, 2013, 56(11), 1
|
| [21] |
Kim Y, Mahapatra R N. Dynamic context compression for low-power coarse-grained reconfigurable architecture. IEEE Trans Very Large Scale Integr Syst, 2009, 18(1), 15 doi: 10.1109/TVLSI.2008.2006846
|
| [22] |
Venkat A, Tullsen D M. Harnessing ISA diversity: Design of a heterogeneous-ISA chip multiprocessor. ACM SIGARCH Comput Architect News, 2014, 42(3), 121 doi: 10.1145/2678373.2665692
|
| [23] |
Hu C. Why FinFET and what next. Keynote in Shanghai Tech Workshop on Emerging Devices, Circuits and Systems, 2016
|
| [24] |
Deng J Y, Li T, Jiang L, et al. Design and optimization for multiprocessor interactive GPU. The Journal of China Universities of Posts and Telecommunications, 2014, 21(3), 85 doi: 10.1016/S1005-8885(14)60305-8
|
| [25] |
Deng J Y, Li T, Jiang L, et al. Design and implementation of the graphics accelerator oriented to OpenGL. Journal of Xidian University, 2015, 42(6), 124
|
| [26] |
Deng J Y, Li T, Jiang L, et al. The design of multiprocessor interactive GPU MIGPU-9. J Comput Aid Des Comput Graph, 2014, 26(9), 1468
|
| [27] |
Shen X B, Liu Z X, Wang R, et al. The unified model of computer architectures. Chin J Computs, 2007, 30(5), 729
|
| [28] |
Black D C, Donovan J, Bunton B, et al. SystemC: From the ground up. Springer Science & Business Media, 2009
|
| [29] |
Eng L Z. Qt5 C++GUI programming cookbook. Packt Publishing Ltd, 2016
|
| [30] |
Zhang X T, Jiang L, Deng J Y, et al. Design and Implementation of global controller in reconfigurable video array processor. Microelectron Comput, 2017, 34(11), 75
|









Article views: 5307 Times PDF downloads: 94 Times Cited by: 0 Times
Received: 27 October 2019 Revised: 13 December 2019 Online: Accepted Manuscript: 06 January 2020Uncorrected proof: 07 January 2020Published: 11 February 2020
| Citation: |
Junyong Deng, Lin Jiang, Yun Zhu, Xiaoyan Xie, Xinchuang Liu, Feilong He, Shuang Song, L. K. John. HRM: H-tree based reconfiguration mechanism in reconfigurable homogeneous PE array[J]. Journal of Semiconductors, 2020, 41(2): 022402. doi: 10.1088/1674-4926/41/2/022402
****
J Y Deng, L Jiang, Y Zhu, X Y Xie, X C Liu, F L He, S Song, L K John, HRM: H-tree based reconfiguration mechanism in reconfigurable homogeneous PE array[J]. J. Semicond., 2020, 41(2): 022402. doi: 10.1088/1674-4926/41/2/022402.

|
| [1] |
Yun Z, Jiang L, Wang S, et al. Design of reconfigurable array processor for multimedia application. Multimed Tools Appl, 2018, 77(3), 3639 doi: 10.1007/s11042-017-5284-7
|
| [2] |
Shi X, Luo X, Liang J, et al. Frog: Asynchronous graph processing on GPU with hybrid coloring model. IEEE Trans Knowl Data Eng, 2017, 30(1), 29 doi: 10.1109/TKDE.2017.2745562
|
| [3] |
Wang Y, Davidson A, Pan Y, et al. Gunrock: A high-performance graph processing library on the GPU. ACM SIGPLAN Notices, 2016, 51(8), 11
|
| [4] |
Cao S, Zhang C, Yao Z, et al. Efficient and effective sparse LSTM on FPGA with bank-balanced sparsity. Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2019, 63
|
| [5] |
Wu E, Zhang X, Berman D, et al. Compute-efficient neural-network acceleration. Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2019, 191
|
| [6] |
Tian R J, Jiang L, Deng J Y, et al. Design and implementation of reconfigurable viewport transformation unit in embedded GPU. Mini-Micro Syst, 2018, 39(05), 1074
|
| [7] |
Vestias M P. High-performance reconfigurable computing. In: Advanced Methodologies and Technologies in Network Architecture, Mobile Computing, and Data Analytics. IGI Global, 2019, 731
|
| [8] |
Yao P, Zheng L, Liao X, et al. An efficient graph accelerator with parallel data conflict management. Proceedings of the 27th International Conference on Parallel Architectures and Compilation Techniques, 2018, 8
|
| [9] |
Yang C, Wang Y, Wang X, et al. WRA: A 2.2-to-6.3 TOPS highly unified dynamically reconfigurable accelerator using a novel Winograd decomposition algorithm for convolutional neural networks. IEEE Trans Circuits Syst I, 2019, 66(9), 3480 doi: 10.1109/TCSI.2019.2928682
|
| [10] |
Liu L, Li Z, Yang C, et al. Hrea: An energy-efficient embedded dynamically reconfigurable fabric for 13-dwarfs processing. IEEE Trans Circuits Syst II, 2017, 65(3), 381 doi: 10.1109/TCSII.2017.2728814
|
| [11] |
Jafri S M A H, Daneshtalab M, Abbas N, et al. Transmap: Transformation based remapping and parallelism for high utilization and energy efficiency in CGRAs. IEEE Trans Comput, 2016, 65(11), 3456 doi: 10.1109/TC.2016.2525981
|
| [12] |
Karunaratne M, Mohite A K, Mitra T, et al. Hycube: A CGRA with reconfigurable single-cycle multi-hop interconnect. 2017 54th ACM/EDAC/IEEE Design Automation Conference (DAC), 2017, 1
|
| [13] |
Kim Y, Joo H, Yoon S. Inter-coarse-grained reconfigurable architecture reconfiguration technique for efficient pipelining of kernel-stream on coarse-grained reconfigurable architecture-based multi-core architecture. IET Circuits, Devices Syst, 2016, 10(4), 251 doi: 10.1049/iet-cds.2015.0047
|
| [14] |
Tajammul M A, Jafri S M A H, Hemani A, et al. Private configuration environments (PCE) for efficient reconfiguration, in CGRAs. 2013 IEEE 24th International Conference on Application-Specific Systems, Architectures and Processors, 2013, 227
|
| [15] |
Jiang L, Deng J Y, Song S, et al. HRM: H-tree based reconfiguration mechanism in homogeneous PE array for video processing. Poster in the 55th Annual Design Automation Conference (DAC’18), 2018
|
| [16] |
Huang J, Raabe A, Buckl C, et al. A workflow for runtime adaptive task allocation on heterogeneous mpsocs. 2011 Design, Automation & Test in Europe, 2011, 1
|
| [17] |
Jafri S M A H, Tajammul M A, Hemani A, et al. Energy-aware-task-parallelism for efficient dynamic voltage, and frequency scaling, in CGRAs. 2013 International Conference on Embedded Computer Systems: Architectures, Modeling, and Simulation (SAMOS), 2013, 104
|
| [18] |
Kirischian L. Reconfigurable computing systems engineering: virtualization of computing architecture. CRC Press, 2017
|
| [19] |
Wei S J, Liu L B, Yin S Y. Reconfigurable computing. Science Press, 2014 (in Chinese)
|
| [20] |
Wang Y S, Liu L B, Yin S Y, et al. Hierarchical representation of on-chip context to reduce reconfiguration time and implementation area for coarse-grained reconfigurable architecture. Sci Chin Inform Sci, 2013, 56(11), 1
|
| [21] |
Kim Y, Mahapatra R N. Dynamic context compression for low-power coarse-grained reconfigurable architecture. IEEE Trans Very Large Scale Integr Syst, 2009, 18(1), 15 doi: 10.1109/TVLSI.2008.2006846
|
| [22] |
Venkat A, Tullsen D M. Harnessing ISA diversity: Design of a heterogeneous-ISA chip multiprocessor. ACM SIGARCH Comput Architect News, 2014, 42(3), 121 doi: 10.1145/2678373.2665692
|
| [23] |
Hu C. Why FinFET and what next. Keynote in Shanghai Tech Workshop on Emerging Devices, Circuits and Systems, 2016
|
| [24] |
Deng J Y, Li T, Jiang L, et al. Design and optimization for multiprocessor interactive GPU. The Journal of China Universities of Posts and Telecommunications, 2014, 21(3), 85 doi: 10.1016/S1005-8885(14)60305-8
|
| [25] |
Deng J Y, Li T, Jiang L, et al. Design and implementation of the graphics accelerator oriented to OpenGL. Journal of Xidian University, 2015, 42(6), 124
|
| [26] |
Deng J Y, Li T, Jiang L, et al. The design of multiprocessor interactive GPU MIGPU-9. J Comput Aid Des Comput Graph, 2014, 26(9), 1468
|
| [27] |
Shen X B, Liu Z X, Wang R, et al. The unified model of computer architectures. Chin J Computs, 2007, 30(5), 729
|
| [28] |
Black D C, Donovan J, Bunton B, et al. SystemC: From the ground up. Springer Science & Business Media, 2009
|
| [29] |
Eng L Z. Qt5 C++GUI programming cookbook. Packt Publishing Ltd, 2016
|
| [30] |
Zhang X T, Jiang L, Deng J Y, et al. Design and Implementation of global controller in reconfigurable video array processor. Microelectron Comput, 2017, 34(11), 75
|

 WeChat ID
WeChat ID
Journal of Semiconductors © 2017 All Rights Reserved 京ICP备05085259号-2