


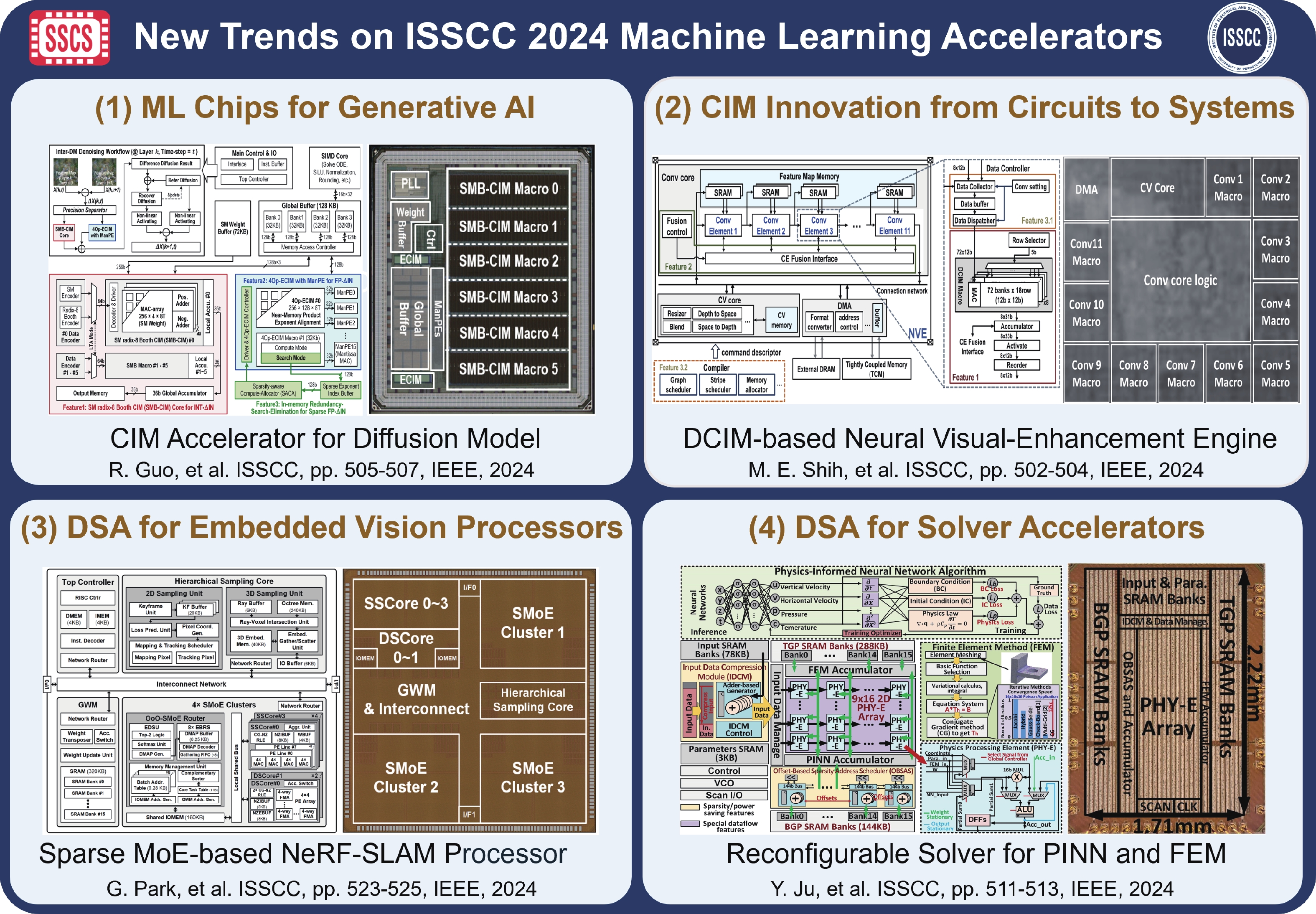
Fig. 1.
(Color online) New trends on ISSCC 2024 machine learning accelerators.
RESEARCH HIGHLIGHTS
Bohan Yang1, 3, Jia Chen1, 2 and Fengbin Tu1, 2,
Corresponding author: Fengbin Tu, fengbintu@ust.hk
| [1] |
Bommasani R, Hudson D A, Adeli E, et al. On the opportunities and risks of foundation models. arXiv preprint, 2021 doi: 10.48550/arXiv.2108.07258
|
| [2] |
Achiam J, Adler S, Agarwal S, et al. GPT-4 technical report. arXiv preprint, 2023 doi: 10.48550/arXiv.2303.08774
|
| [3] |
Ramesh A, Pavlov M, Goh G, et al. Zero-shot text-to-image generation. International Conference on Machine Learning (ICML), 2021 doi: 10.48550/arXiv.2102.12092
|
| [4] |
Mu C, Zheng J P, Chen C X. Beyond convolutional neural networks computing: New trends on ISSCC 2023 machine learning chips. J Semicond, 2023, 44, 050203 doi: 10.1088/1674-4926/44/5/050203
|
| [5] |
Alben J. Computing in the era of generative AI. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 26 doi: 10.1109/ISSCC49657.2024.10454562
|
| [6] |
Smith A, Chapman E, Patel C, et al. AMD InstinctTM MI300 series modular chiplet package–HPC and AI accelerator for exa-class systems. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 490 doi: 10.1109/ISSCC49657.2024.10454441
|
| [7] |
Guo R Q, Wang L, Chen X F, et al. A 28nm 74.34TFLOPS/W BF16 heterogenous CIM-based accelerator exploiting denoising-similarity for diffusion models. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 362 doi: 10.1109/ISSCC49657.2024.10454308
|
| [8] |
Kim S, Kim S, Jo W, et al. C-transformer: A 2.6-18.1μJ/token homogeneous DNN-transformer/spiking-transformer processor with big-little network and implicit weight generation for large language models. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 368 doi: 10.1109/ISSCC49657.2024.10454330
|
| [9] |
ISSCC 2024 forum 2: Energy-efficient AI-computing systems for large-language models. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 593
|
| [10] |
Fujiwara H, Mori H, Zhao W C, et al. A 3nm, 32.5TOPS/W, 55.0TOPS/mm2 and 3.78Mb/mm2 fully-digital compute-in-memory macro supporting INT12 × INT12 with a parallel-MAC architecture and foundry 6T-SRAM bit cell. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 572 doi: 10.1109/ISSCC49657.2024.10454556
|
| [11] |
He Y F, Fan S P, Li X, et al. A 28nm 2.4Mb/mm2 6.9-16.3TOPS/mm2 eDRAM-LUT-based digital-computing-in-memory macro with in-memory encoding and refreshing. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 578 doi: 10.1109/ISSCC49657.2024.10454323
|
| [12] |
Guo A, Chen X, Dong F Y, et al. A 22nm 64kb lightning-like hybrid computing-in-memory macro with a compressed adder tree and analog-storage quantizers for transformer and CNNs. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 570 doi: 10.1109/ISSCC49657.2024.10454278
|
| [13] |
Wang L F, Li W Z, Zhou Z D, et al. A flash-SRAM-ADC-fused plastic computing-in-memory macro for learning in neural networks in a standard 14nm FinFET process. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 582 doi: 10.1109/ISSCC49657.2024.10454372
|
| [14] |
Tu F B, Wang Y Q, Wu Z H, et al. A 28nm 29.2TFLOPS/W BF16 and 36.5TOPS/W INT8 reconfigurable digital CIM processor with unified FP/INT pipeline and bitwise In-memory booth multiplication for cloud deep learning acceleration. 2022 IEEE International Solid-State Circuits Conference (ISSCC), 2022, 1 doi: 10.1109/ISSCC42614.2022.9731762
|
| [15] |
Wang Y, Yang X L, Qin Y B, et al. A 28nm 83.23TFLOPS/W POSIT-based compute-in-memory macro for high-accuracy AI applications. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 566 doi: 10.1109/ISSCC49657.2024.10454567
|
| [16] |
Wen T H, Hsu H H, Khwa W S, et al. A 22nm 16Mb floating-point ReRAM compute-in-memory macro with 31.2TFLOPS/W for AI edge devices. 2024 IEEE International Solid State Circuits Conference (ISSCC), 2024 doi: 10.1109/ISSCC49657.2024.10454468
|
| [17] |
Shih M E, Hsieh S W, Tsai P Y, et al. NVE: A 3nm 23.2TOPS/W 12b-digital-CIM-based neural engine for high-resolution visual-quality enhancement on smart devices. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 360 doi: 10.1109/ISSCC49657.2024.10454482
|
| [18] |
Wang Y P, Yang M T, Lo C P, et al. Vecim: A 289.13GOPS/W RISC-V vector co-processor with compute-in-memory vector register file for efficient high-performance computing. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 492 doi: 10.1109/ISSCC49657.2024.10454387
|
| [19] |
Apple Vision Pro, https://www.apple.com/apple-vision-pro/
|
| [20] |
Figure 01 robot, https://www.figure.ai/
|
| [21] |
Park G, Song S, Sang H Y, et al. Space-mate: A 303.5mW real-time sparse mixture-of-experts-based NeRF-SLAM processor for mobile spatial computing. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 374 doi: 10.1109/ISSCC49657.2024.10454487
|
| [22] |
Ryu J, Kwon H, Park W, et al. NeuGPU: A 18.5mJ/iter neural-graphics processing unit for instant-modeling and real-time rendering with segmented-hashing architecture. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 372 doi: 10.1109/ISSCC49657.2024.10454276
|
| [23] |
Nose K, Fujii T, Togawa K, et al. A 23.9TOPS/W @ 0.8V, 130TOPS AI accelerator with 16 × performance-accelerable pruning in 14nm heterogeneous embedded MPU for real-time robot applications. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 364 doi: 10.1109/ISSCC49657.2024.10454357
|
| [24] |
Chu Y C, Lin Y C, Lo Y C, et al. A fully integrated annealing processor for large-scale autonomous navigation optimization. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 488 doi: 10.1109/ISSCC49657.2024.10454294
|
| [25] |
Song J H, Wu Z H, Tang X Y, et al. A variation-tolerant In-eDRAM continuous-time Ising machine featuring 15-level coefficients and leaked negative-feedback annealing. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 490 doi: 10.1109/ISSCC49657.2024.10454272
|
| [26] |
Bae J, Shim C, Kim B. E-chimera: A scalable SRAM-based Ising macro with enhanced-chimera topology for solving combinatorial optimization problems within memory. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 286 doi: 10.1109/ISSCC49657.2024.10454340
|
| [27] |
Bae J, Koo J, Shim C, et al. LISA: A 576 × 4 all-in-one replica-spins continuous-time latch-based Ising computer using massively-parallel random-number generations and replica equalizations. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 284 doi: 10.1109/ISSCC49657.2024.10454559
|
| [28] |
Shim C, Bae J, Kim B. VIP-sat: A Boolean satisfiability solver featuring 5 × 12 variable in-memory processing elements with 98% solvability for 50-variables 218-clauses 3-SAT problems. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 486 doi: 10.1109/ISSCC49657.2024.10454397
|
| [29] |
Ju Y H, Xu G Q, Gu J. A 28nm physics computing unit supporting emerging physics-informed neural network and finite element method for real-time scientific computing on edge devices. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 366 doi: 10.1109/ISSCC49657.2024.10454502
|
| [1] |
Bommasani R, Hudson D A, Adeli E, et al. On the opportunities and risks of foundation models. arXiv preprint, 2021 doi: 10.48550/arXiv.2108.07258
|
| [2] |
Achiam J, Adler S, Agarwal S, et al. GPT-4 technical report. arXiv preprint, 2023 doi: 10.48550/arXiv.2303.08774
|
| [3] |
Ramesh A, Pavlov M, Goh G, et al. Zero-shot text-to-image generation. International Conference on Machine Learning (ICML), 2021 doi: 10.48550/arXiv.2102.12092
|
| [4] |
Mu C, Zheng J P, Chen C X. Beyond convolutional neural networks computing: New trends on ISSCC 2023 machine learning chips. J Semicond, 2023, 44, 050203 doi: 10.1088/1674-4926/44/5/050203
|
| [5] |
Alben J. Computing in the era of generative AI. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 26 doi: 10.1109/ISSCC49657.2024.10454562
|
| [6] |
Smith A, Chapman E, Patel C, et al. AMD InstinctTM MI300 series modular chiplet package–HPC and AI accelerator for exa-class systems. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 490 doi: 10.1109/ISSCC49657.2024.10454441
|
| [7] |
Guo R Q, Wang L, Chen X F, et al. A 28nm 74.34TFLOPS/W BF16 heterogenous CIM-based accelerator exploiting denoising-similarity for diffusion models. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 362 doi: 10.1109/ISSCC49657.2024.10454308
|
| [8] |
Kim S, Kim S, Jo W, et al. C-transformer: A 2.6-18.1μJ/token homogeneous DNN-transformer/spiking-transformer processor with big-little network and implicit weight generation for large language models. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 368 doi: 10.1109/ISSCC49657.2024.10454330
|
| [9] |
ISSCC 2024 forum 2: Energy-efficient AI-computing systems for large-language models. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 593
|
| [10] |
Fujiwara H, Mori H, Zhao W C, et al. A 3nm, 32.5TOPS/W, 55.0TOPS/mm2 and 3.78Mb/mm2 fully-digital compute-in-memory macro supporting INT12 × INT12 with a parallel-MAC architecture and foundry 6T-SRAM bit cell. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 572 doi: 10.1109/ISSCC49657.2024.10454556
|
| [11] |
He Y F, Fan S P, Li X, et al. A 28nm 2.4Mb/mm2 6.9-16.3TOPS/mm2 eDRAM-LUT-based digital-computing-in-memory macro with in-memory encoding and refreshing. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 578 doi: 10.1109/ISSCC49657.2024.10454323
|
| [12] |
Guo A, Chen X, Dong F Y, et al. A 22nm 64kb lightning-like hybrid computing-in-memory macro with a compressed adder tree and analog-storage quantizers for transformer and CNNs. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 570 doi: 10.1109/ISSCC49657.2024.10454278
|
| [13] |
Wang L F, Li W Z, Zhou Z D, et al. A flash-SRAM-ADC-fused plastic computing-in-memory macro for learning in neural networks in a standard 14nm FinFET process. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 582 doi: 10.1109/ISSCC49657.2024.10454372
|
| [14] |
Tu F B, Wang Y Q, Wu Z H, et al. A 28nm 29.2TFLOPS/W BF16 and 36.5TOPS/W INT8 reconfigurable digital CIM processor with unified FP/INT pipeline and bitwise In-memory booth multiplication for cloud deep learning acceleration. 2022 IEEE International Solid-State Circuits Conference (ISSCC), 2022, 1 doi: 10.1109/ISSCC42614.2022.9731762
|
| [15] |
Wang Y, Yang X L, Qin Y B, et al. A 28nm 83.23TFLOPS/W POSIT-based compute-in-memory macro for high-accuracy AI applications. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 566 doi: 10.1109/ISSCC49657.2024.10454567
|
| [16] |
Wen T H, Hsu H H, Khwa W S, et al. A 22nm 16Mb floating-point ReRAM compute-in-memory macro with 31.2TFLOPS/W for AI edge devices. 2024 IEEE International Solid State Circuits Conference (ISSCC), 2024 doi: 10.1109/ISSCC49657.2024.10454468
|
| [17] |
Shih M E, Hsieh S W, Tsai P Y, et al. NVE: A 3nm 23.2TOPS/W 12b-digital-CIM-based neural engine for high-resolution visual-quality enhancement on smart devices. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 360 doi: 10.1109/ISSCC49657.2024.10454482
|
| [18] |
Wang Y P, Yang M T, Lo C P, et al. Vecim: A 289.13GOPS/W RISC-V vector co-processor with compute-in-memory vector register file for efficient high-performance computing. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 492 doi: 10.1109/ISSCC49657.2024.10454387
|
| [19] |
Apple Vision Pro, https://www.apple.com/apple-vision-pro/
|
| [20] |
Figure 01 robot, https://www.figure.ai/
|
| [21] |
Park G, Song S, Sang H Y, et al. Space-mate: A 303.5mW real-time sparse mixture-of-experts-based NeRF-SLAM processor for mobile spatial computing. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 374 doi: 10.1109/ISSCC49657.2024.10454487
|
| [22] |
Ryu J, Kwon H, Park W, et al. NeuGPU: A 18.5mJ/iter neural-graphics processing unit for instant-modeling and real-time rendering with segmented-hashing architecture. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 372 doi: 10.1109/ISSCC49657.2024.10454276
|
| [23] |
Nose K, Fujii T, Togawa K, et al. A 23.9TOPS/W @ 0.8V, 130TOPS AI accelerator with 16 × performance-accelerable pruning in 14nm heterogeneous embedded MPU for real-time robot applications. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 364 doi: 10.1109/ISSCC49657.2024.10454357
|
| [24] |
Chu Y C, Lin Y C, Lo Y C, et al. A fully integrated annealing processor for large-scale autonomous navigation optimization. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 488 doi: 10.1109/ISSCC49657.2024.10454294
|
| [25] |
Song J H, Wu Z H, Tang X Y, et al. A variation-tolerant In-eDRAM continuous-time Ising machine featuring 15-level coefficients and leaked negative-feedback annealing. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 490 doi: 10.1109/ISSCC49657.2024.10454272
|
| [26] |
Bae J, Shim C, Kim B. E-chimera: A scalable SRAM-based Ising macro with enhanced-chimera topology for solving combinatorial optimization problems within memory. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 286 doi: 10.1109/ISSCC49657.2024.10454340
|
| [27] |
Bae J, Koo J, Shim C, et al. LISA: A 576 × 4 all-in-one replica-spins continuous-time latch-based Ising computer using massively-parallel random-number generations and replica equalizations. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 284 doi: 10.1109/ISSCC49657.2024.10454559
|
| [28] |
Shim C, Bae J, Kim B. VIP-sat: A Boolean satisfiability solver featuring 5 × 12 variable in-memory processing elements with 98% solvability for 50-variables 218-clauses 3-SAT problems. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 486 doi: 10.1109/ISSCC49657.2024.10454397
|
| [29] |
Ju Y H, Xu G Q, Gu J. A 28nm physics computing unit supporting emerging physics-informed neural network and finite element method for real-time scientific computing on edge devices. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 366 doi: 10.1109/ISSCC49657.2024.10454502
|









Article views: 6512 Times PDF downloads: 1034 Times Cited by: 0 Times
Received: 08 March 2024 Revised: 26 March 2024 Online: Accepted Manuscript: 02 April 2024Uncorrected proof: 02 April 2024Published: 10 April 2024
| Citation: |
Bohan Yang, Jia Chen, Fengbin Tu. Towards efficient generative AI and beyond-AI computing: New trends on ISSCC 2024 machine learning accelerators[J]. Journal of Semiconductors, 2024, 45(4): 040204. doi: 10.1088/1674-4926/45/4/040204
****
B H Yang, J Chen, F B Tu. Towards efficient generative AI and beyond-AI computing: New trends on ISSCC 2024 machine learning accelerators[J]. J. Semicond, 2024, 45(4): 040204. doi: 10.1088/1674-4926/45/4/040204

|
 Bohan Yang is currently a senior undergraduate at the School of the Gifted Young, University of Science and Technology of China, Hefei, China. He is also a visiting intern at the Department of Electronic and Computer Engineering, The Hong Kong University of Science and Technology, Hong Kong, China. His research interests include modern computer architecture, accelerators for emerging workloads, and software hardware co-design
Bohan Yang is currently a senior undergraduate at the School of the Gifted Young, University of Science and Technology of China, Hefei, China. He is also a visiting intern at the Department of Electronic and Computer Engineering, The Hong Kong University of Science and Technology, Hong Kong, China. His research interests include modern computer architecture, accelerators for emerging workloads, and software hardware co-design Jia Chen is currently a Postdoc researcher at the AI Chip Center for Emerging Smart Systems (ACCESS), The Hong Kong University of Science and Technology. She received her Ph.D. degree in microelectronics and solid-state electronics from Huazhong University of Science and Technology in 2021. Her research interests include emerging non-volatile memory devices and computing-in-memory related circuit design
Jia Chen is currently a Postdoc researcher at the AI Chip Center for Emerging Smart Systems (ACCESS), The Hong Kong University of Science and Technology. She received her Ph.D. degree in microelectronics and solid-state electronics from Huazhong University of Science and Technology in 2021. Her research interests include emerging non-volatile memory devices and computing-in-memory related circuit design Fengbin Tu received the B.S. degree from the School of Electronic Engineering, Beijing University of Posts and Telecommunications, Beijing, China, in 2013, and received the Ph.D. degree from the Institute of Microelectronics, Tsinghua University, Beijing, China, in 2019. Dr. Tu is currently an Assistant Professor at the Department of Electronic and Computer Engineering, The Hong Kong University of Science and Technology, Hong Kong, China. He was a Postdoctoral Fellow at the AI Chip Center for Emerging Smart Systems (ACCESS), Hong Kong, China, from 2022 to 2023, and a Postdoctoral Scholar at the Scalable Energy-efficient Architecture Lab (SEAL), the Department of Electrical and Computer Engineering, University of California, Santa Barbara, CA, USA, from 2019 to 2022. His research interests include AI chip, computer architecture, reconfigurable computing, and computing-in-memory. His AI chips ReDCIM and Thinker won the 2023 Top-10 Research Advances in China Semiconductors and 2017 ISLPED Design Contest Award, respectively. He has published two books, Architecture Design and Memory Optimization for Neural Network Accelerators and Artificial Intelligence Chip Design. His research works appeared at top conferences and journals on integrated circuits and computer architecture, including ISSCC, JSSC, DAC, ISCA, and MICRO
Fengbin Tu received the B.S. degree from the School of Electronic Engineering, Beijing University of Posts and Telecommunications, Beijing, China, in 2013, and received the Ph.D. degree from the Institute of Microelectronics, Tsinghua University, Beijing, China, in 2019. Dr. Tu is currently an Assistant Professor at the Department of Electronic and Computer Engineering, The Hong Kong University of Science and Technology, Hong Kong, China. He was a Postdoctoral Fellow at the AI Chip Center for Emerging Smart Systems (ACCESS), Hong Kong, China, from 2022 to 2023, and a Postdoctoral Scholar at the Scalable Energy-efficient Architecture Lab (SEAL), the Department of Electrical and Computer Engineering, University of California, Santa Barbara, CA, USA, from 2019 to 2022. His research interests include AI chip, computer architecture, reconfigurable computing, and computing-in-memory. His AI chips ReDCIM and Thinker won the 2023 Top-10 Research Advances in China Semiconductors and 2017 ISLPED Design Contest Award, respectively. He has published two books, Architecture Design and Memory Optimization for Neural Network Accelerators and Artificial Intelligence Chip Design. His research works appeared at top conferences and journals on integrated circuits and computer architecture, including ISSCC, JSSC, DAC, ISCA, and MICRO| [1] |
Bommasani R, Hudson D A, Adeli E, et al. On the opportunities and risks of foundation models. arXiv preprint, 2021 doi: 10.48550/arXiv.2108.07258
|
| [2] |
Achiam J, Adler S, Agarwal S, et al. GPT-4 technical report. arXiv preprint, 2023 doi: 10.48550/arXiv.2303.08774
|
| [3] |
Ramesh A, Pavlov M, Goh G, et al. Zero-shot text-to-image generation. International Conference on Machine Learning (ICML), 2021 doi: 10.48550/arXiv.2102.12092
|
| [4] |
Mu C, Zheng J P, Chen C X. Beyond convolutional neural networks computing: New trends on ISSCC 2023 machine learning chips. J Semicond, 2023, 44, 050203 doi: 10.1088/1674-4926/44/5/050203
|
| [5] |
Alben J. Computing in the era of generative AI. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 26 doi: 10.1109/ISSCC49657.2024.10454562
|
| [6] |
Smith A, Chapman E, Patel C, et al. AMD InstinctTM MI300 series modular chiplet package–HPC and AI accelerator for exa-class systems. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 490 doi: 10.1109/ISSCC49657.2024.10454441
|
| [7] |
Guo R Q, Wang L, Chen X F, et al. A 28nm 74.34TFLOPS/W BF16 heterogenous CIM-based accelerator exploiting denoising-similarity for diffusion models. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 362 doi: 10.1109/ISSCC49657.2024.10454308
|
| [8] |
Kim S, Kim S, Jo W, et al. C-transformer: A 2.6-18.1μJ/token homogeneous DNN-transformer/spiking-transformer processor with big-little network and implicit weight generation for large language models. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 368 doi: 10.1109/ISSCC49657.2024.10454330
|
| [9] |
ISSCC 2024 forum 2: Energy-efficient AI-computing systems for large-language models. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 593
|
| [10] |
Fujiwara H, Mori H, Zhao W C, et al. A 3nm, 32.5TOPS/W, 55.0TOPS/mm2 and 3.78Mb/mm2 fully-digital compute-in-memory macro supporting INT12 × INT12 with a parallel-MAC architecture and foundry 6T-SRAM bit cell. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 572 doi: 10.1109/ISSCC49657.2024.10454556
|
| [11] |
He Y F, Fan S P, Li X, et al. A 28nm 2.4Mb/mm2 6.9-16.3TOPS/mm2 eDRAM-LUT-based digital-computing-in-memory macro with in-memory encoding and refreshing. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 578 doi: 10.1109/ISSCC49657.2024.10454323
|
| [12] |
Guo A, Chen X, Dong F Y, et al. A 22nm 64kb lightning-like hybrid computing-in-memory macro with a compressed adder tree and analog-storage quantizers for transformer and CNNs. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 570 doi: 10.1109/ISSCC49657.2024.10454278
|
| [13] |
Wang L F, Li W Z, Zhou Z D, et al. A flash-SRAM-ADC-fused plastic computing-in-memory macro for learning in neural networks in a standard 14nm FinFET process. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 582 doi: 10.1109/ISSCC49657.2024.10454372
|
| [14] |
Tu F B, Wang Y Q, Wu Z H, et al. A 28nm 29.2TFLOPS/W BF16 and 36.5TOPS/W INT8 reconfigurable digital CIM processor with unified FP/INT pipeline and bitwise In-memory booth multiplication for cloud deep learning acceleration. 2022 IEEE International Solid-State Circuits Conference (ISSCC), 2022, 1 doi: 10.1109/ISSCC42614.2022.9731762
|
| [15] |
Wang Y, Yang X L, Qin Y B, et al. A 28nm 83.23TFLOPS/W POSIT-based compute-in-memory macro for high-accuracy AI applications. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 566 doi: 10.1109/ISSCC49657.2024.10454567
|
| [16] |
Wen T H, Hsu H H, Khwa W S, et al. A 22nm 16Mb floating-point ReRAM compute-in-memory macro with 31.2TFLOPS/W for AI edge devices. 2024 IEEE International Solid State Circuits Conference (ISSCC), 2024 doi: 10.1109/ISSCC49657.2024.10454468
|
| [17] |
Shih M E, Hsieh S W, Tsai P Y, et al. NVE: A 3nm 23.2TOPS/W 12b-digital-CIM-based neural engine for high-resolution visual-quality enhancement on smart devices. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 360 doi: 10.1109/ISSCC49657.2024.10454482
|
| [18] |
Wang Y P, Yang M T, Lo C P, et al. Vecim: A 289.13GOPS/W RISC-V vector co-processor with compute-in-memory vector register file for efficient high-performance computing. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 492 doi: 10.1109/ISSCC49657.2024.10454387
|
| [19] |
Apple Vision Pro, https://www.apple.com/apple-vision-pro/
|
| [20] |
Figure 01 robot, https://www.figure.ai/
|
| [21] |
Park G, Song S, Sang H Y, et al. Space-mate: A 303.5mW real-time sparse mixture-of-experts-based NeRF-SLAM processor for mobile spatial computing. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 374 doi: 10.1109/ISSCC49657.2024.10454487
|
| [22] |
Ryu J, Kwon H, Park W, et al. NeuGPU: A 18.5mJ/iter neural-graphics processing unit for instant-modeling and real-time rendering with segmented-hashing architecture. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 372 doi: 10.1109/ISSCC49657.2024.10454276
|
| [23] |
Nose K, Fujii T, Togawa K, et al. A 23.9TOPS/W @ 0.8V, 130TOPS AI accelerator with 16 × performance-accelerable pruning in 14nm heterogeneous embedded MPU for real-time robot applications. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 364 doi: 10.1109/ISSCC49657.2024.10454357
|
| [24] |
Chu Y C, Lin Y C, Lo Y C, et al. A fully integrated annealing processor for large-scale autonomous navigation optimization. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 488 doi: 10.1109/ISSCC49657.2024.10454294
|
| [25] |
Song J H, Wu Z H, Tang X Y, et al. A variation-tolerant In-eDRAM continuous-time Ising machine featuring 15-level coefficients and leaked negative-feedback annealing. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 490 doi: 10.1109/ISSCC49657.2024.10454272
|
| [26] |
Bae J, Shim C, Kim B. E-chimera: A scalable SRAM-based Ising macro with enhanced-chimera topology for solving combinatorial optimization problems within memory. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 286 doi: 10.1109/ISSCC49657.2024.10454340
|
| [27] |
Bae J, Koo J, Shim C, et al. LISA: A 576 × 4 all-in-one replica-spins continuous-time latch-based Ising computer using massively-parallel random-number generations and replica equalizations. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 284 doi: 10.1109/ISSCC49657.2024.10454559
|
| [28] |
Shim C, Bae J, Kim B. VIP-sat: A Boolean satisfiability solver featuring 5 × 12 variable in-memory processing elements with 98% solvability for 50-variables 218-clauses 3-SAT problems. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 486 doi: 10.1109/ISSCC49657.2024.10454397
|
| [29] |
Ju Y H, Xu G Q, Gu J. A 28nm physics computing unit supporting emerging physics-informed neural network and finite element method for real-time scientific computing on edge devices. 2024 IEEE International Solid-State Circuits Conference (ISSCC), 2024, 366 doi: 10.1109/ISSCC49657.2024.10454502
|

 WeChat ID
WeChat ID
Journal of Semiconductors © 2017 All Rights Reserved 京ICP备05085259号-2

 DownLoad:
DownLoad:

