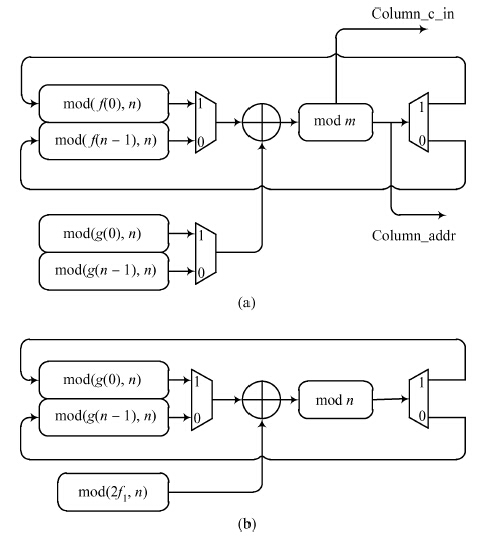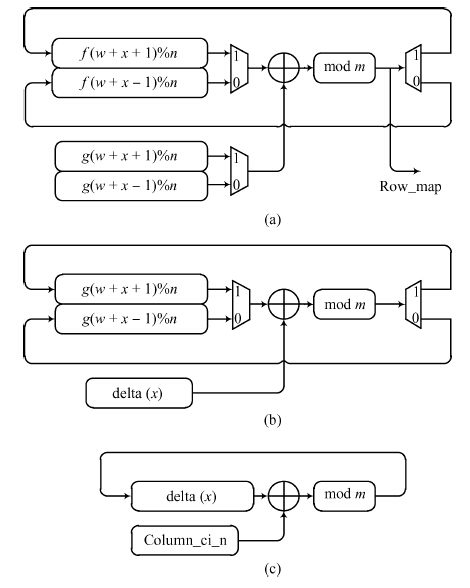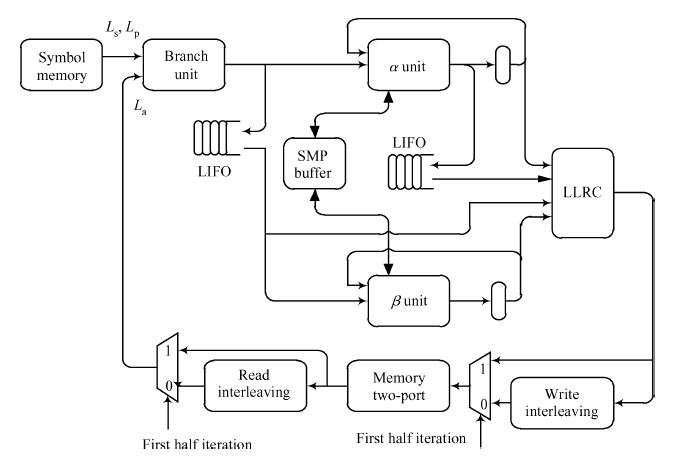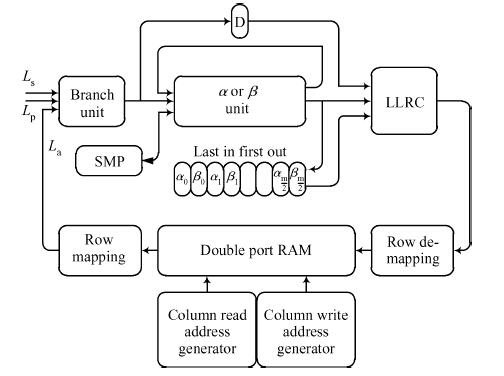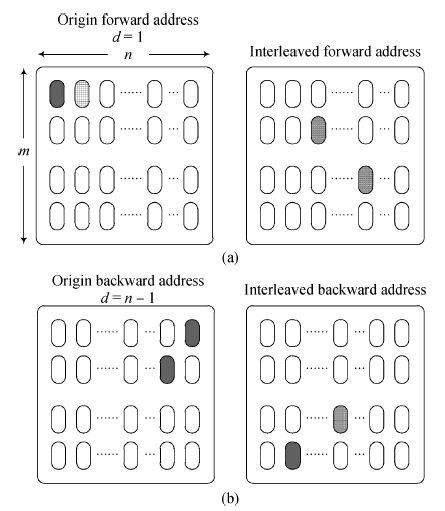
Fig. 1.
Matrix interleaving.
SEMICONDUCTOR INTEGRATED CIRCUITS
Le Yang, Tianchun Ye, Bin Wu and Ruiqi Zhang
Corresponding author: Bin Wu, E-mail: wubin@ime.ac.cn
Abstract: This paper presents a turbo decoder supporting all 188 block sizes in 3GPP long term evolution (LTE) standard which can be employed in the LTE micro-eNodB system. The design allows 1, 2, 4, 8 or 16 soft-in/soft-out (SISO) decoders to concurrently process each block size, and the number of iterations can be adjusted. This article proposes an improved SISO algorithm and interleaving design, calculated forward state matrix and backward state matrix alternately, and the branch transition probability can be used in the Turbo decode process directly just after one clock delay. The structure enables a decoder processing radix-2 algorithm with high speed, instead of radix-4 as the conventional decoder. Moreover, the paper details an interleaver/de-interleaver, which is combined by two operational steps. One is column address mapping and the other is intra-row permutation. Decoder realizes interleaving by loading data from memories whose address is generated by column mapping and then lets data passing through inter-row permutation. For de-interleaving, the system can adopt reverse operation.
Keywords: LTE, turbo decoder, (quadratic polynomial permutation) QPP interleaver
| [1] | |
| [2] | |
| [3] | |
| [4] | |
| [5] | |
| [6] | |
| [7] | |
| [8] | |
| [9] |
| [1] | |
| [2] | |
| [3] | |
| [4] | |
| [5] | |
| [6] | |
| [7] | |
| [8] | |
| [9] |









Article views: 3008 Times PDF downloads: 37 Times Cited by: 0 Times
Received: 25 November 2014 Revised: Online: Published: 01 July 2015
| Citation: |
Le Yang, Tianchun Ye, Bin Wu, Ruiqi Zhang. LTE turbo decoder design[J]. Journal of Semiconductors, 2015, 36(7): 075003. doi: 10.1088/1674-4926/36/7/075003
****
L Yang, T C Ye, B Wu, R Q Zhang. LTE turbo decoder design[J]. J. Semicond., 2015, 36(7): 075003. doi: 10.1088/1674-4926/36/7/075003.

|
| [1] | |
| [2] | |
| [3] | |
| [4] | |
| [5] | |
| [6] | |
| [7] | |
| [8] | |
| [9] |

 WeChat ID
WeChat ID
Journal of Semiconductors © 2017 All Rights Reserved 京ICP备05085259号-2

 DownLoad:
DownLoad: